MetaEmbed: Scaling Multimodal Retrieval at Test-Time with Flexible Late Interaction
Abstract: Universal multimodal embedding models have achieved great success in capturing semantic relevance between queries and candidates. However, current methods either condense queries and candidates into a single vector, potentially limiting the expressiveness for fine-grained information, or produce too many vectors that are prohibitively expensive for multi-vector retrieval. In this work, we introduce MetaEmbed, a new framework for multimodal retrieval that rethinks how multimodal embeddings are constructed and interacted with at scale. During training, a fixed number of learnable Meta Tokens are appended to the input sequence. At test-time, their last-layer contextualized representations serve as compact yet expressive multi-vector embeddings. Through the proposed Matryoshka Multi-Vector Retrieval training, MetaEmbed learns to organize information by granularity across multiple vectors. As a result, we enable test-time scaling in multimodal retrieval, where users can balance retrieval quality against efficiency demands by selecting the number of tokens used for indexing and retrieval interactions. Extensive evaluations on the Massive Multimodal Embedding Benchmark (MMEB) and the Visual Document Retrieval Benchmark (ViDoRe) confirm that MetaEmbed achieves state-of-the-art retrieval performance while scaling robustly to models with 32B parameters.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
MetaEmbed: A simple explanation
What this paper is about (overview)
The paper introduces MetaEmbed, a smarter way for computers to find the right match between things like pictures and text. This is called multimodal retrieval. Imagine you ask a question (text) and want the system to find the best image, or you show a picture and want the best matching caption. MetaEmbed makes this searching both accurate and fast, and it lets you choose how much speed or accuracy you want at the moment you use it.
What questions the paper tries to answer (key objectives)
- How can we keep fine details when matching images and text, instead of squeezing everything into one blunt summary number?
- How can we avoid using hundreds of tiny pieces (tokens) that make searching slow and expensive?
- Can we train a system that lets users pick “quick and cheap” or “slow but super accurate” at test-time, without retraining the model?
How the method works (in everyday language)
Think of each image or text as a book you want to shelve in a library so you can find it later.
- Old way 1: One-summary approach
- You write one short summary for the whole book. It’s fast to store and compare, but you lose details (like important characters or events).
- Old way 2: Many-details approach
- You create hundreds of note cards with lots of details. It’s very accurate but takes a ton of space and time to compare every card.
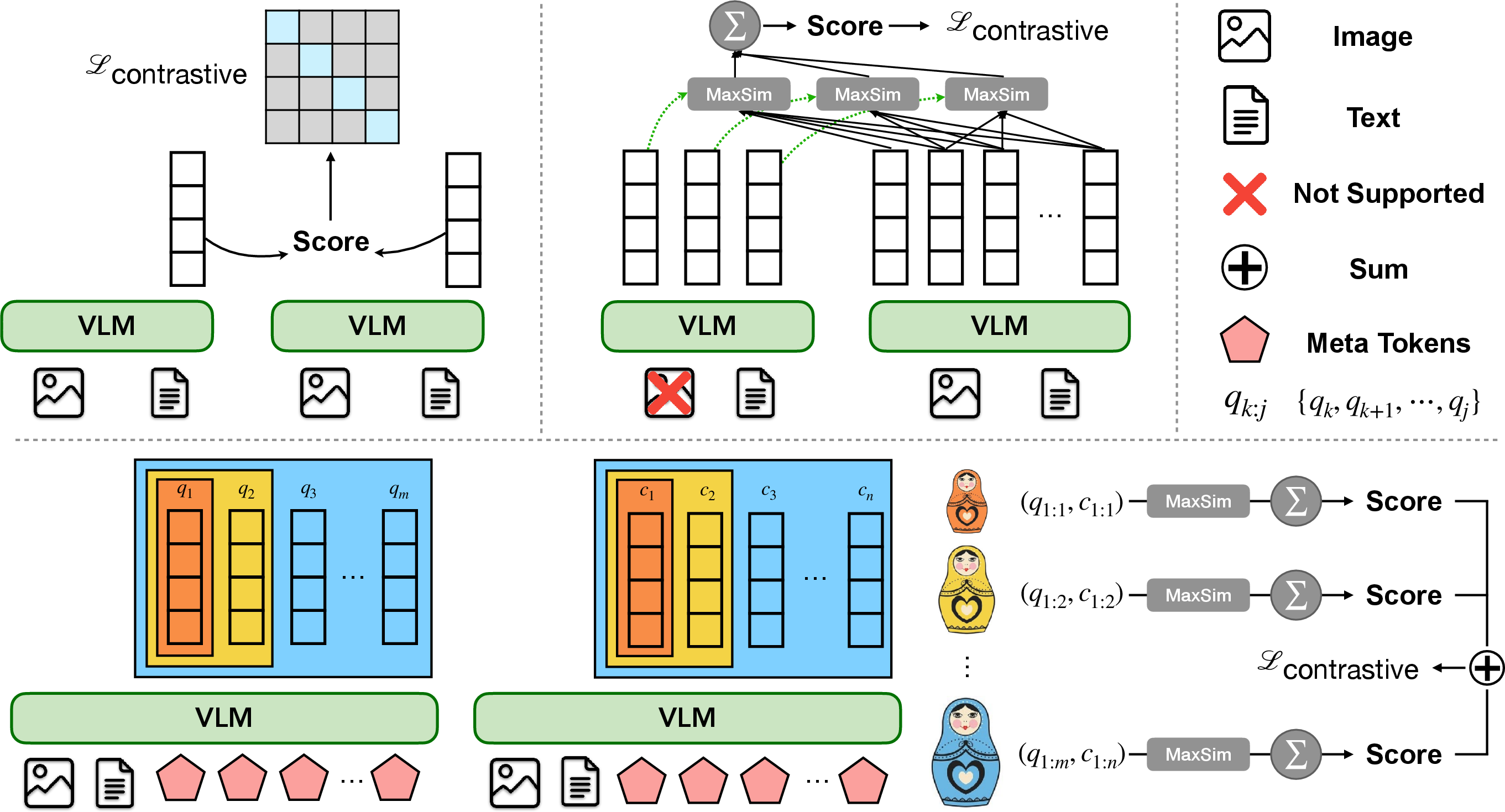
MetaEmbed’s idea: use a small set of “smart sticky notes”
- Meta Tokens: The model attaches a few learnable “sticky notes” to each input (image or text). These notes travel through the model together with the input, so they end up holding a compact, smart summary of both the big picture and important details.
- Meta Embeddings: At the end, these few sticky notes become the representation of the item. You don’t store hundreds of notes—just a handful that still capture what matters.
How matching works (late interaction):
- When you compare a query (like a question) to a candidate (like an image), you match each sticky note from the query with the best matching sticky note from the candidate, then add up those matches. This keeps detailed information without comparing every single image patch or word token.
How training makes the notes flexible (Matryoshka idea):
- Matryoshka dolls go from big to small, nested inside each other.
- The model trains the sticky notes in “prefix groups,” like nested dolls: the first 1 note should capture the biggest idea, the first 2 notes give more detail, then 4 notes, then 8, and so on.
- Because of this, at test-time you can choose how many notes to use:
- Few notes: faster, uses less memory, slightly less accurate.
- More notes: slower, uses more memory, more accurate.
- This choice (called the retrieval budget) is made at test-time—no retraining needed.
In short:
- Turn each item into a small set of smart notes (Meta Tokens).
- Train those notes so the early ones give a coarse summary and the later ones add detail (Matryoshka training).
- Match queries and candidates by letting each query note find its best partner in the candidate (late interaction).
What they found (main results and why they matter)
Across big benchmarks, MetaEmbed set or matched top results while staying efficient:
- Strong accuracy on tough tests:
- MMEB (a large benchmark with image classification, visual question answering, retrieval, and grounding): MetaEmbed beat previous methods at multiple model sizes. The 7B and especially the 32B versions reached state-of-the-art results.
- ViDoRe v2 (visual document retrieval, including multilingual and biomedical): MetaEmbed performed very well, even though it wasn’t trained specifically on multilingual data.
- Test-time flexibility works:
- When you increase the number of sticky notes used during search, accuracy goes up in a smooth, predictable way.
- With very few notes, it’s fast and still solid. With more notes, it becomes very accurate.
- Efficient and scalable:
- Old multi-vector methods need hundreds of tokens per image and per query—too slow and memory-heavy.
- MetaEmbed uses only a small number of notes while keeping detail, so it’s much more practical at scale.
- The time spent comparing items (scoring) is usually small compared to the time spent turning a query into notes (encoding). This means the flexible matching doesn’t slow things down much in real use.
- Works across different base models:
- The method works with several vision-language backbones (like Qwen2.5-VL, PaliGemma, and Llama-3.2-Vision).
- Performance depends on the backbone’s strengths (for example, if a backbone is weaker at certain question-answering tasks, that can show up in the retrieval results).
- Training design (Matryoshka Multi-Vector Retrieval) is crucial:
- Training the notes in nested groups makes the low-budget settings (fewer notes) much stronger.
- Even at full budget (more notes), this training does not hurt performance and can even improve it.
Why this matters:
- You get both fine-grained understanding (details matter) and real-world efficiency (memory and speed matter), and you can dial the balance up or down as needed.
What this could change (implications and impact)
MetaEmbed shows a practical path to better, more flexible search across images and text:
- Real products can choose speed vs. accuracy on the fly (for example, mobile devices pick speed; servers pick accuracy).
- It enables rich multimodal-to-multimodal search (image+text queries against image+text documents) without exploding compute costs.
- It scales well to very large models (like 32B parameters) and multiple backbones, making it a strong foundation for future systems.
In everyday terms: MetaEmbed is like giving every item in a giant library a handful of very smart, layered sticky notes that make finding the right match fast, accurate, and adjustable—so you can search the way you need, when you need it.
Knowledge Gaps
Below is a single, concrete list of knowledge gaps, limitations, and open questions that remain unresolved in the paper. Each point is framed to be actionable for future research.
- Multimodal-to-multimodal retrieval evaluation is missing: there are no experiments where both queries and candidates contain images (e.g., image+text → image+text or image → image), despite claims of enabling such scenarios.
- Lack of web-scale indexing experiments: results are reported up to 100k candidates; behavior at million/billion-scale corpora (index memory, throughput, sharding, resilience) is untested.
- No integration with approximate nearest neighbor search: the method isn’t evaluated with ANN systems (e.g., IVF-PQ/HNSW, Faiss, ScaNN, Milvus) to quantify recall/latency trade-offs and compatibility under multi-vector late interaction.
- Index compression and quantization are not addressed: there is no study of bfloat16 vs FP16/INT8/PQ, vector pruning, grouped quantization, or product quantization for memory reduction at scale.
- End-to-end latency is under-characterized: only scoring latency is analyzed; query encoding dominates but is not comprehensively benchmarked across batch sizes, concurrency, and varied input lengths/modalities.
- No automatic test-time budget selection: the paper provides manual budget (r_q, r_c) selection; strategies for adaptive, per-query budget control (e.g., uncertainty-aware cascades or early exit) are absent.
- Fixed group configurations with minimal sensitivity analysis: the choices of group sizes (e.g., {(1,1), (2,4), …, (16,64)}), group weights w_g, and temperature τ lack systematic ablation or principled selection criteria.
- Ambiguity about Meta Tokens’ nature: it is unclear whether Meta Tokens are global parameters shared across inputs or dynamically conditioned per instance; their learned roles and per-token contribution remain uninterpreted.
- Limited exploration of late interaction operators: only MaxSim is used; alternatives (softmax pooling, learned attention kernels, temperature-controlled pooling, or weighted aggregation) are not compared.
- No re-ranking pipeline: the approach isn’t evaluated with a cross-encoder re-ranker on top of MetaEmbed retrieval to measure potential gains and cost in realistic retrieval stacks.
- Impact on generative capabilities is unmeasured: LoRA fine-tuning for embedding may degrade the VLM’s generation abilities; catastrophic forgetting or multi-task co-training strategies are not assessed.
- Document/OCR robustness is not studied: sensitivity to OCR errors, layout complexity, small fonts, and multi-column/page structures is not quantified, especially for ViDoRe-style domains.
- Multilingual generalization lacks controlled analysis: despite promising ViDoRe v2 results without multilingual training, broader evaluation across languages/scripts, long/complex queries, and code-switching is missing.
- Training data scale and diversity are limited: only MMEB-train and ViDoRe-train (with one hard negative) are used; scaling with synthetic data (e.g., MegaPairs) or teacher distillation (e.g., UniME) in the MetaEmbed framework is untested.
- Modal extension is unclear: the “universal multimodal” framing is text-image only; extension to video/audio (and their retrieval tasks) is not explored.
- Scaling laws for number of Meta Tokens (R_q, R_c) and embedding dimension (D) are absent: the paper uses max (16,64) but does not chart accuracy–cost curves for varying token counts and dimensions across backbone sizes.
- Asymmetric budgeting across modalities/tasks is not optimized: r_q < r_c is chosen, but a principled study for text vs image, short vs long queries, and VQA vs retrieval is missing.
- Multi-image/multi-page queries are not evaluated: composition across multiple images/pages (common in document retrieval) and its effect on MetaEmbed is untested.
- Training stability and sensitivity are not reported: convergence plots, seed variance, optimizer choices, and hard-negative mining strategies (beyond one from MoCa) lack documentation.
- Robustness to adversarial/noisy inputs is unexamined: no analysis of adversarial images/prompts, spurious correlations, or noise in candidates/queries.
- Metrics are limited: reliance on P@1 and NDCG@5 omits Recall@K, MRR, calibration metrics, and reliability analyses (e.g., score calibration for thresholding or filtering).
- Data leakage auditing is missing: the paper does not report checks for overlap/contamination between training and evaluation splits in MMEB/ViDoRe.
- Diminishing returns with larger backbones need rigorous analysis: while 32B shows gains, a more thorough cost–benefit curve and diminishing returns characterization is absent.
- Operational index maintenance is not addressed: incremental indexing, deletions, updates, and consistency of matryoshka prefixes under evolving corpora are not studied.
- Hardware/software ecosystem benchmarking is absent: performance across different GPU generations, CPU-only scenarios, and vector DBs is unreported.
- Fair baseline comparison to single-vector Matryoshka is missing: MetaEmbed vs single-vector MRL with matched compute/budgets is not systematically compared.
- Per-task breakdown and failure modes are thin: deeper analysis of which MMEB/ViDoRe tasks benefit most/least, and qualitative error studies, are not provided.
- Training includes claims about multimodal-to-multimodal feasibility but lacks direct empirical verification: explicitly test scenarios with images on both sides to substantiate the claimed advantage over patch/token-heavy methods.
- Token ordering and importance are fixed via prefix-nesting: learning per-instance token importance, dynamic reordering, or token pruning at test-time could improve efficiency but are unexplored.
- Energy and cost reporting is absent: GPU-hours, watts, and index build times are not provided; deployment guidance (cost-aware recipes) would help practitioners.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, leveraging MetaEmbed’s flexible, compact multi-vector embeddings and test-time scaling via Matryoshka Multi-Vector Retrieval (MMR).
- Enterprise multimodal search and knowledge management — Sectors: software, enterprise IT — What it enables: unified retrieval across PDFs, slides, images, charts, screenshots, and text (including multimodal-to-multimodal queries) with a tunable latency/accuracy knob. — Tools/products/workflows: a “MetaEmbed Search” service backed by FAISS/ScaNN; a vector DB extension that stores nested multi-vector prefixes; admin dashboard to set per-tenant retrieval budgets. — Assumptions/dependencies: high-quality OCR for scanned docs; vector DB support for late interaction (MaxSim) and multi-vector indexing; GPU/accelerator capacity for query encoding; data governance and access control.
- Visual document retrieval for ESG, biomedical, and multilingual corpora — Sectors: finance, healthcare, research — What it enables: domain document search aligned with ViDoRe tasks (ESG reports, biomedical papers, multilingual filings), robust even without dedicated multilingual training. — Tools/products/workflows: “ESG Finder,” “BioDoc Search,” and multilingual search plugins; retrieval-augmented dashboards for analysts; query-time budget knob for rapid triage vs deep search. — Assumptions/dependencies: compliance with data privacy (HIPAA/GDPR where applicable); domain-specific prompt templates; controlled vocabularies or ontologies to improve recall.
- E-commerce multimodal product search — Sectors: retail, marketplaces — What it enables: search by text, image, or text+image edits (e.g., “like this shoe but waterproof”), accurate fine-grained attribute retrieval with compact indices. — Tools/products/workflows: product catalog index with tiered Meta Tokens; dynamic budgets by device and SLA; reranking pipelines that increase prefix size for top-K candidates. — Assumptions/dependencies: product taxonomy quality; image quality and attribute labeling; ANN infrastructure that can scale to tens/hundreds of millions of SKUs.
- Customer support copilots with multimodal RAG — Sectors: software, telecom, consumer electronics — What it enables: retrieve manuals, annotated screenshots, wiring diagrams, and chat logs to ground LLM responses; tune budgets for mobile vs server inference. — Tools/products/workflows: retrieval middleware exposing (r_q, r_c) as an API parameter; fallbacks that progressively expand budgets for unresolved tickets. — Assumptions/dependencies: knowledge base hygiene; safe retrieval filters; GPU quota for peak hours; logging/observability for retrieval quality.
- Digital asset management (DAM) in media/newsrooms — Sectors: media, entertainment — What it enables: fast, fine-grained search over large image/video poster frames, captions, and storyboards; cross-modal alignment for editorial workflows. — Tools/products/workflows: nested-index “fast skim” mode for breaking news; “deep precision” mode for final curation; rights/usage metadata retrieval. — Assumptions/dependencies: storage budget for multi-vector prefixes; role-based access; consistent captioning pipelines.
- Legal e-discovery and compliance review — Sectors: legal, finance — What it enables: retrieval across contracts, scanned exhibits, annotated figures, and emails; adjustable budgets for early case assessment vs detailed review. — Tools/products/workflows: discovery review UI with query budget slider; server-side expansion (e.g., from (2,4) to (16,64)) for shortlists; audit logs of retrieval decisions. — Assumptions/dependencies: strong OCR and redaction tooling; chain-of-custody requirements; defensibility of retrieval scoring.
- Education and assessment support for charts/diagrams — Sectors: education, EdTech — What it enables: retrieve exemplar solutions and references for chart/table questions (ChartQA-like), science images, and labeled diagrams; instructor tools to pull analogous items. — Tools/products/workflows: classroom assistant that first searches with small prefixes during live sessions, then re-ranks with larger budgets offline. — Assumptions/dependencies: licensed curricular content; age-appropriate filtering; accessibility support.
- On-device gallery and notes search — Sectors: consumer software, mobile — What it enables: low-latency search over photos, screenshots, and sketched notes using compact, nested embeddings; budget scaling by battery and device class. — Tools/products/workflows: mobile SDK that precomputes candidate prefixes; adaptive retrieval based on device thermal state and user SLA. — Assumptions/dependencies: on-device acceleration (NPUs/GPUs); storage limits for multi-vector indices; privacy-preserving design.
- Developer SDKs and vector DB adapters — Sectors: software infrastructure — What it enables: drop-in late-interaction scoring and nested multi-vector index management for FAISS, ScaNN, Milvus, pgvector. — Tools/products/workflows: “MetaEmbed-ANN” adapters; CLI to build/store/query group-wise prefixes; monitoring for accuracy vs latency trade-offs. — Assumptions/dependencies: ANN support for grouped vectors; careful memory planning; reproducible evaluation (MMEB/ViDoRe) baked in.
- Cloud retrieval API with budget SLA — Sectors: cloud platforms — What it enables: a hosted multimodal retrieval service with per-request (r_q, r_c) control and automatic fallback to larger budgets on ambiguous queries. — Tools/products/workflows: usage-based billing by index size and budget; policy guardrails for PII; tiered routing (edge vs core DC). — Assumptions/dependencies: clear licensing for VLM backbones (Qwen2.5-VL/Llama-3.2-Vision/PaliGemma); regional data residency compliance.
- Migration pathway from single-vector systems — Sectors: all — What it enables: incremental gains by indexing only small prefixes first (e.g., (2,4)), then rolling out larger prefixes as storage/budget allows. — Tools/products/workflows: dual-write indices; A/B tests against single-vector baselines; per-query budget heuristics. — Assumptions/dependencies: backward-compatible APIs; cost management for index growth; change management for ranking logic.
Long-Term Applications
The following require additional research, scaling, or ecosystem development (e.g., ANN support, hardware acceleration, large-scale training/fine-tuning, policy frameworks).
- Web-scale multimodal-to-multimodal search (images, charts, PDFs, video keyframes) — Sectors: search engines, media — What it enables: Internet-scale retrieval where both queries and candidates are multimodal; efficient late interaction without patch-level explosion. — Tools/products/workflows: hierarchical, sharded multi-vector indices; multi-stage routing that increases prefixes only for finalists. — Assumptions/dependencies: distributed MaxSim acceleration; cost-aware budget controllers; robust de-duplication and safety filters.
- Dynamic, energy-aware retrieval controllers — Sectors: cloud, energy — What it enables: automatically set (r_q, r_c) per request by latency, energy price, carbon intensity, and answer confidence. — Tools/products/workflows: budget controllers trained via bandits/RL; carbon-aware schedulers. — Assumptions/dependencies: instrumentation for energy and latency; accurate confidence estimation; policy alignment with sustainability targets.
- Federated and privacy-preserving multimodal retrieval — Sectors: healthcare, finance, government — What it enables: in-silo indices with late interaction executed via secure enclaves or split computation; privacy-preserving cross-silo ranking. — Tools/products/workflows: secure multiparty MaxSim; differential privacy for index storage; federated budget tuning. — Assumptions/dependencies: cryptographic protocols for multi-vector ops; regulatory approvals; performance overhead acceptance.
- Real-time AR assistants with contextual retrieval — Sectors: AR/VR, consumer, field service — What it enables: on-device retrieval from manuals/know-how given live camera frames; budget scales with motion/scene complexity. — Tools/products/workflows: streaming index updates; temporal caching of top-K with progressive refinement. — Assumptions/dependencies: low-power accelerators; efficient video-to-meta embeddings; safety gating.
- Robotics perception-by-retrieval — Sectors: robotics, manufacturing, logistics — What it enables: retrieve part IDs, tool states, or assembly steps by comparing current camera view to a curated, indexed library; budget increases when uncertainty is high. — Tools/products/workflows: perception loops that escalate from coarse to fine prefixes; integration with task planners. — Assumptions/dependencies: domain fine-tuning; robust lighting/pose variation handling; real-time constraints.
- Multimodal RAG with budget-aware fusion — Sectors: software, productivity — What it enables: retrieval-augmented generation that adaptively expands retrieval budgets for ambiguous or high-stakes prompts before answering. — Tools/products/workflows: retrieval “budget escalators” tied to answerability/uncertainty scores; learn-to-route pipelines. — Assumptions/dependencies: reliable uncertainty estimates; cost-quality trade-off modeling; prompt-grounding safety rules.
- Hardware/ANN acceleration for late interaction — Sectors: semiconductors, infra — What it enables: kernels and index structures specialized for MaxSim across nested prefixes; compression schemes aligned with MMR. — Tools/products/workflows: GPU/NPU kernels for batched MaxSim; prefix-aware quantization; memory-mapped hierarchical indices. — Assumptions/dependencies: ecosystem support in FAISS/ScaNN/Milvus; compiler/runtime integration; acceptable accuracy under quantization.
- Domain-specialized Meta Tokens and curricula — Sectors: legal, biotech, geospatial, security — What it enables: pre-trained, reusable Meta Tokens tailored to a domain’s granularity (e.g., clauses/figures, binding sites, map layers). — Tools/products/workflows: token libraries and adapters; LoRA fine-tuning kits; domain-specific budget presets. — Assumptions/dependencies: curated domain corpora; licensing; evaluation suites akin to MMEB/ViDoRe for each domain.
- Cross-lingual and low-resource expansion — Sectors: global public sector, NGOs, education — What it enables: strong multilingual retrieval for documents and infographics in low-resource languages; budget increases for script-rich or noisy inputs. — Tools/products/workflows: multilingual pretraining/fine-tuning pipelines; transliteration-aware retrieval. — Assumptions/dependencies: coverage of scripts/fonts; OCR for complex scripts; dataset availability.
- Standardization and policy for energy-efficient retrieval — Sectors: policy, standards bodies — What it enables: procurement standards and reporting for adjustable retrieval budgets, energy/latency disclosures, and accuracy benchmarks. — Tools/products/workflows: “retrieval budget” in SLAs; public leaderboards that include cost/energy metrics. — Assumptions/dependencies: consensus on metrics; verifiable reporting; alignment with compliance regimes.
- Secure content moderation and provenance search — Sectors: platforms, trust & safety — What it enables: retrieval of near-duplicate multimodal content and provenance trails using compact multi-vectors; tiered budgets for suspected abuse. — Tools/products/workflows: nested indices for hashes+embeddings; escalated budgets for human-in-the-loop review. — Assumptions/dependencies: watermarking/provenance signals; legal frameworks for content handling; robust adversarial defenses.
Notes on feasibility across applications
- Compute and latency: Query encoding dominates latency; ensure sufficient accelerators or move heavy encoding offline for candidates.
- Index size: Memory grows with retrieval budget and corpus size; plan storage tiers and prefix sizes carefully.
- ANN/DB support: Requires multi-vector storage and late interaction (MaxSim) support; consider custom adapters if not yet available.
- Backbone and licensing: Choice of VLM backbone materially affects performance (e.g., VQA variance across backbones); confirm usage rights.
- Data quality: OCR, metadata, captions, and domain labels strongly influence outcomes for visual documents.
- Safety/compliance: Enforce privacy, access control, auditability, and safe retrieval filtering, especially in regulated domains.
Glossary
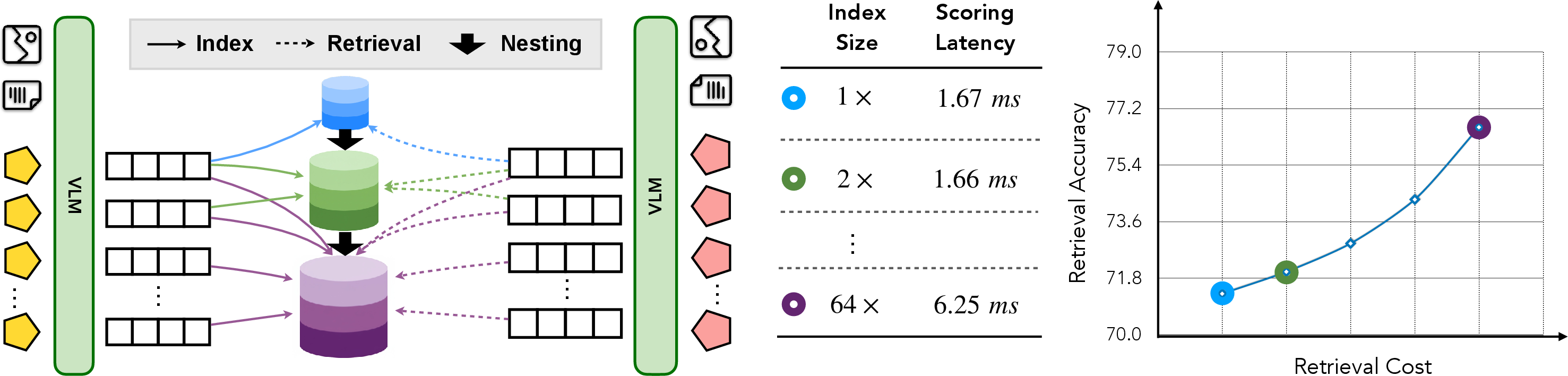
- A100 GPU: A specific NVIDIA data-center GPU model used for benchmarking retrieval latency. "Scoring latency is reported with 100,000 candidates per query on an A100 GPU."
- bfloat16 precision: A reduced-precision floating-point format that speeds up computation and reduces memory use in deep learning. "Index is stored and compared with bfloat16 precision~\citep{wang_kanwar_2019_bfloat16}."
- ColBERT: A multi-vector dense retrieval framework that introduces late interaction between query and document token embeddings. "In text retrieval, ColBERT~\citep{khattab2020colbert} introduced a multi-vector late interaction mechanism that retains multiple token-level embeddings and uses a lightweight scoring between query and document token representations."
- contrastive learning: A training paradigm that pulls matched (positive) pairs together and pushes unmatched (negative) pairs apart in the embedding space. "one could apply contrastive learning on the extracted embedding from the hidden states of the last layer of a VLM to learn meaningful multimodal representations while retaining pre-trained knowledge."
- contrastive objective: A loss function that maximizes similarity of correct pairs while minimizing it for incorrect pairs. "Single vector retrieval method computes a score for each pair of query and candidate and uses contrastive objective to maximize the score for corresponding pairs."
- cross-attention-based models: Architectures that integrate visual inputs into LLMs via cross-attention layers. "as well as cross-attention-based models such as Llama-3.2-Vision~\citep{grattafiori2024llama}."
- cross-modal retrieval: Retrieving relevant content across different modalities (e.g., text-to-image, image-to-text). "While existing methods, including CLIP~\citep{CLIP}, BLIP~\citep{BLIP} and SigLIP~\citep{SigLIP} have demonstrated superior performance in cross-modal retrieval,"
- decoder-only models: Neural architectures composed solely of decoder blocks (without an encoder), often used for generative tasks. "including decoder-only models such as Qwen2.5-VL~\citep{Qwen25-VL} and PaliGemma~\citep{beyer2024paligemma},"
- embedding dimension: The number of features (D) in each embedding vector. "where is the embedding dimension, and are the number of token-level vectors for the query and the candidate, respectively."
- hard negative: A challenging negative example chosen to improve training by making discrimination more difficult. "We only incorporate MMEB-train~\citep{jiang2025vlmvec} and ViDoRe-train~\citep{ColPali} with one explicit hard negative from \cite{chen2025moca} for training all variants of MetaEmbed."
- index memory consumption: The memory required to store candidate embeddings in the retrieval index. "we mainly discuss the efficiency of MetaEmbed as a flexible multi-vector retrieval method, with a focus on index memory consumption and latency under varying retrieval budgets."
- index size: The total storage footprint of the retrieval index containing candidate embeddings. "This results in large index sizes and slower retrieval processing."
- InfoNCE loss: A contrastive loss based on noise-contrastive estimation commonly used for representation learning. "The InfoNCE loss~\citep{oord2018representation} for group is:"
- L2 normalization: Scaling a vector to unit length by dividing by its L2 norm. "followed by L2 normalization."
- late interaction: A retrieval strategy where multiple query and document vectors interact after independent encoding to compute relevance. "To enable flexible late interaction, where users can trade off retrieval accuracy against computational budget and retrieval latency, we draw inspiration from Matryoshka Representation Learning~\citep{kusupati2022matryoshka} and design the Matryoshka Multi-Vector Retrieval (MMR) module in MetaEmbed."
- late interaction operator: The formal operator that sums the maximum similarities (dot products) between query and document vectors. "The late interaction operator $\mathbf{LI}(q, d) = \sum_{i=1}^{N_q} \max_{j \in [1, N_d]} \left\langle \mathbf{E}_{\mathbf{q}^{(i)}, \mathbf{E}_{\mathbf{d}^{(j)} \right\rangle.$"
- LoRA: Low-Rank Adaptation, a parameter-efficient fine-tuning method for large models. "We use LoRA~\citep{lora} with a rank of 32 and scaling factor in all training."
- Massive Multimodal Embedding Benchmark (MMEB): A comprehensive benchmark of 36 tasks for evaluating multimodal embeddings. "We first validate MetaEmbed on the Massive Multimodal Embedding Benchmark (MMEB)~\citep{MMEB} and Visual Document Retrieval Benchmarks (ViDoRe) v2~\citep{ColPali},"
- Matryoshka Multi-Vector Retrieval (MMR): A training framework that organizes multi-vector embeddings into nested prefixes for flexible test-time interaction. "Inspired by~\cite{kusupati2022matryoshka} , we impose a prefix-nested structure on Meta Embeddings so that the first few vectors form a coarse summary, and additional vectors refine the representation."
- Matryoshka Representation Learning (MRL): A method to encode features at multiple granularities in a nested structure within a single representation. "Matryoshka Representation Learning (MRL)~\citep{kusupati2022matryoshka} was introduced to encode features at multiple granularities within a single vector in a nested structure."
- MaxSim: A maximum-similarity interaction used in late interaction scoring. "late interaction (e.g., MaxSim in Eq.~\ref{eq:late_interaction}) between multiple embeddings."
- Meta Embeddings: Compact, contextualized vectors obtained from Meta Tokens to represent inputs for late interaction. "their final hidden states serve as Meta Embeddings."
- Meta Tokens: Learnable tokens appended to inputs whose final hidden states become multi-vector embeddings. "we introduce a small number of learnable Meta Tokens appended to the input sequence of the query and candidate."
- multi-vector retrieval: Dense retrieval where each item is represented by multiple embedding vectors instead of a single vector. "In multi-vector retrieval, scores are computed via maximum similarity across vector pairs and aggregated before applying the contrastive objective."
- multimodal retrieval: Retrieving relevant content across modalities such as text and images. "Multimodal retrieval consists of retrieving relevant content across different modalities, where the query can be text , an image or a combination of both ."
- NDCG@5: Normalized Discounted Cumulative Gain at rank 5; a ranking evaluation metric. "and use average NDCG@5 as the metric."
- Precision@1: The fraction of queries where the top-ranked result is correct. "and use Precision@1 as the evaluation metric."
- prefix-nested structure: An organization of embeddings where initial vectors give a coarse summary and later ones refine it. "we impose a prefix-nested structure on Meta Embeddings so that the first few vectors form a coarse summary,"
- retrieval budget: The selected number of query and candidate vectors used for indexing and interaction at test time. "In later sections, we refer to the selected combination of group sizes as the retrieval budget."
- retrieval latency: The time required to compute retrieval scores and rankings. "incur substantial efficiency costs in terms of index size, retrieval latency and feasibility."
- scoring latency: The time specifically spent computing similarity scores in the retrieval pipeline. "Scoring latency is reported with 100,000 candidates per query on an A100 GPU."
- temperature hyper-parameter: A scaling parameter in contrastive softmax that controls distribution sharpness. "with as a temperature hyper-parameter."
- test-time scaling: Adjusting the number of vectors used at inference to trade off accuracy against efficiency. "As a result, we enable test-time scaling in multimodal retrieval where users can balance retrieval quality against efficiency demands by selecting the number of tokens used for indexing and retrieval interactions."
- Vision-LLM (VLM): A model that jointly processes visual and textual inputs to produce unified representations. "Thanks to recent advances in building embeddings through foundation vision-LLMs (VLMs),"
- Visual Document Retrieval Benchmark (ViDoRe): A benchmark for evaluating visual document retrieval systems. "the Massive Multimodal Embedding Benchmark (MMEB) and the Visual Document Retrieval Benchmark (ViDoRe) confirm that MetaEmbed achieves state-of-the-art retrieval performance"
- Visual Grounding: Linking textual expressions to visual regions or objects in images. "and visual grounding e.g. COCO~\citep{coco}, RefCOCO~\citep{referitgame,refcoco}."
Collections
Sign up for free to add this paper to one or more collections.