- The paper presents a comprehensive taxonomy categorizing hallucinations in LLM agents across reasoning, execution, perception, memorization, and communication.
- It reviews causes—including sensor errors, flawed memory and tool documentation, and uncoordinated communication—and discusses detection via self-verification and benchmarking.
- The survey advocates mitigation strategies using external knowledge, paradigm improvements, and post-hoc verification to enhance agent safety and reliability.
Overview of Hallucinations in LLM-Based Agents
The paper "LLM-based Agents Suffer from Hallucinations: A Survey of Taxonomy, Methods, and Directions" (arXiv ID: (2509.18970)) provides a comprehensive examination of hallucinations in LLM agents. It addresses the critical issue of hallucinations affecting the reliability and safety of these agents. The survey categorizes these hallucinations, identifies their causes, reviews mitigation and detection methods, and proposes future research directions. The following sections explore the taxonomy, causes, methodologies, and implications of these hallucinations.
Taxonomy of Agent Hallucinations
The authors propose a new taxonomy for hallucinations occurring at different stages of an agent's workflow, comprising five main types:
- Reasoning Hallucinations: Logical errors in goal understanding, intention decomposition, and planning generation (Figure 1).
- Execution Hallucinations: Errors related to tool selection and invocation, where agents confidently execute non-existent or irrelevant actions (Figure 2).
- Perception Hallucinations: Deviations in transforming external information due to sensor malfunctions or encoding limitations.
- Memorization Hallucinations: The use of outdated or erroneous memory content during decision-making.
- Communication Hallucinations: Inaccurate or misleading information exchange between agents in multi-agent systems.
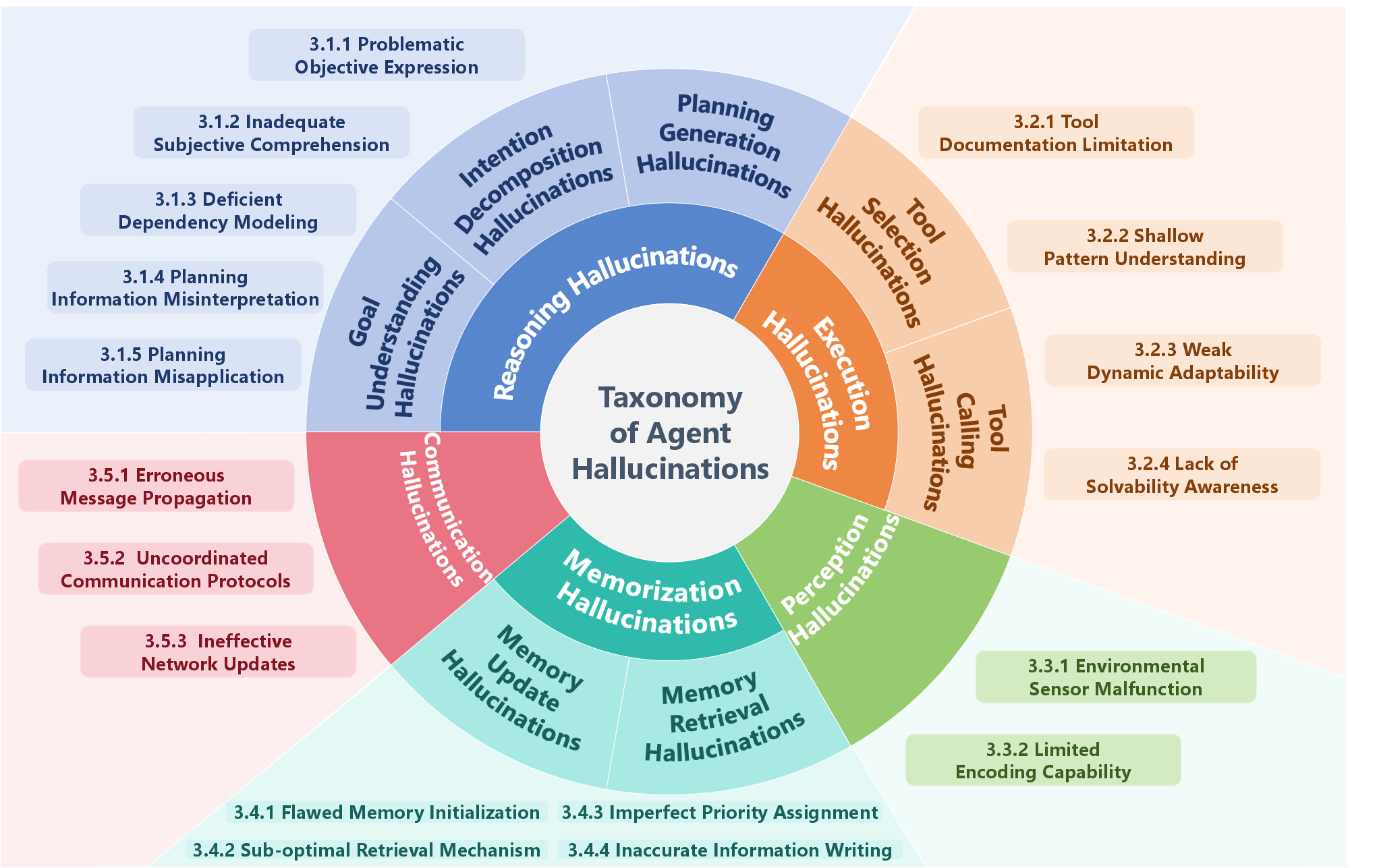
Figure 1: A taxonomy of agent hallucinations with corresponding triggering causes.
Causes of Hallucinations
Hallucinations stem from various sources, including:
- Sensor Malfunctions: Affecting perception through faulty data collection.
- Poor Tool Documentation: Leading to execution errors due to inadequate understanding of tool functionalities.
- Flawed Memory Initialization and Sub-optimal Retrieval: Introducing memorization errors via inaccurate or biased initial memory.
- Uncoordinated Communication Protocols: Causing inconsistencies in information exchange within multi-agent setups.
These factors can aggravate hallucinatory behavior, particularly in complex environments or tasks requiring extensive coordination and collaboration.
Mitigation and Detection Strategies
The survey identifies several approaches:
Mitigation Strategies
- Knowledge Utilization: Leveraging external world knowledge and expert domains to guide agents.
- Paradigm Improvement: Employing contrastive, curriculum, reinforcement, and causal learning to enhance agent capabilities.
- Post-hoc Verification: Introducing self-verification mechanisms and external validators to check and correct outputs after execution (Figure 3).
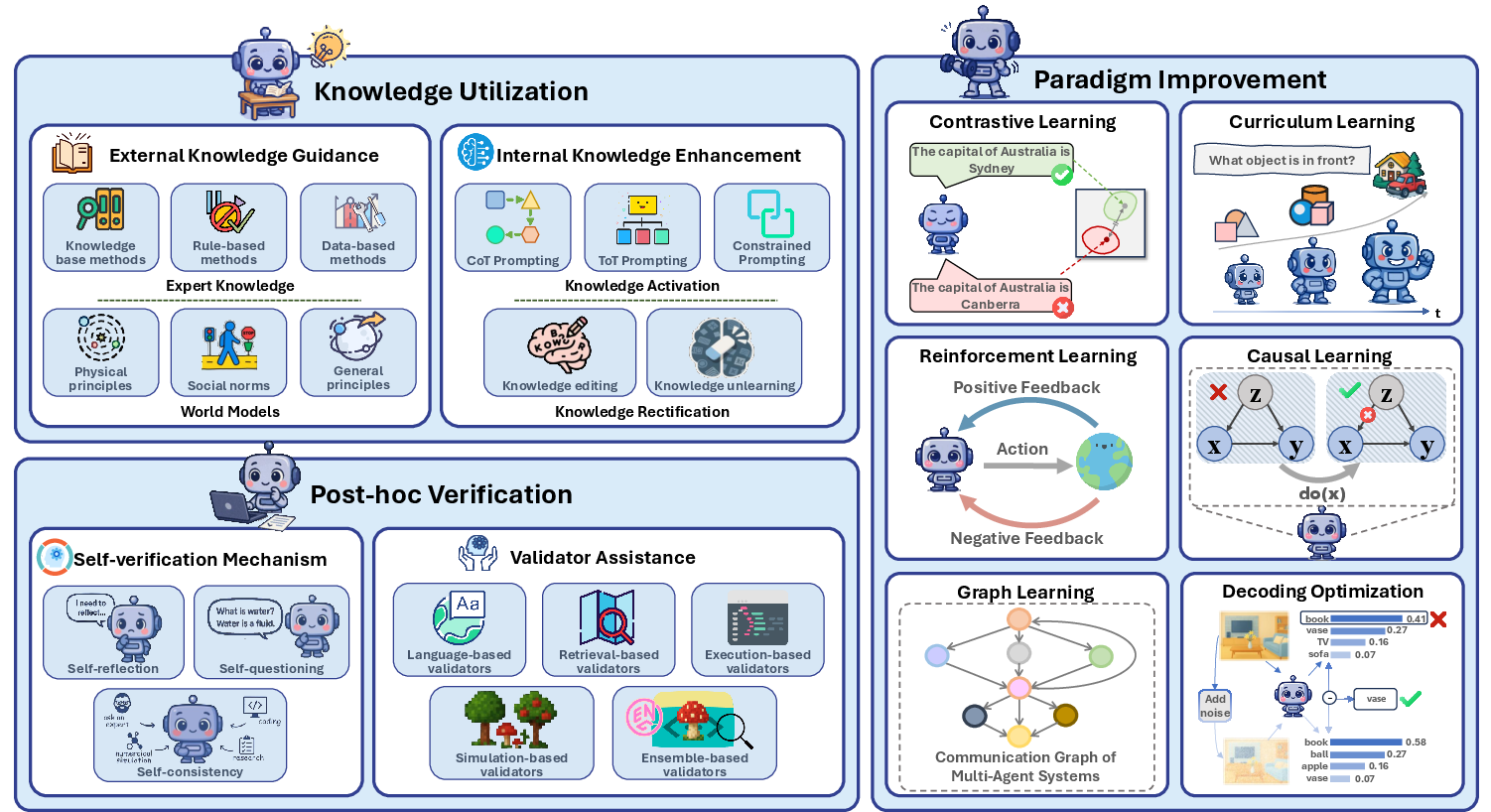
Figure 3: A simple illustration of approaches to agent hallucination mitigation. It encompasses three branches, knowledge utilization, paradigm improvement, and post-hoc certification, comprising a total of ten representative methods.
Detection Methods
Detection methods include self-questioning techniques, ensemble validators, and specific benchmarks that assess different types of hallucinations in real-time settings (Figure 2).

Figure 2: The depiction of different types of agent hallucinations, each illustrated with a representative example.
Implications and Future Research Directions
This paper emphasizes the importance of addressing hallucinations for ensuring the robustness and reliability of LLM agents. It suggests avenues such as:
- Hallucinatory Accumulation: Investigating how minor hallucinations can accumulate over lengthy decision sequences.
- Unified Benchmark Construction: Developing comprehensive benchmarks evaluating all hallucination types systematically.
- Continual Self-evolution: Focusing on agents' ability to adapt to dynamic changes and evolving goals.
These directions aim to overcome current challenges and risks posed by hallucinations, promising significant improvements in the deployment of LLM agents across diverse applications.
Conclusion
By providing a detailed taxonomy and exploring mitigation and detection strategies, this survey paves the way for advancing research into hallucinations in LLM-based agents. It lays a foundation for future investigations aimed at enhancing agent reliability and safety in complex real-world scenarios, driving towards increasingly robust intelligent systems.