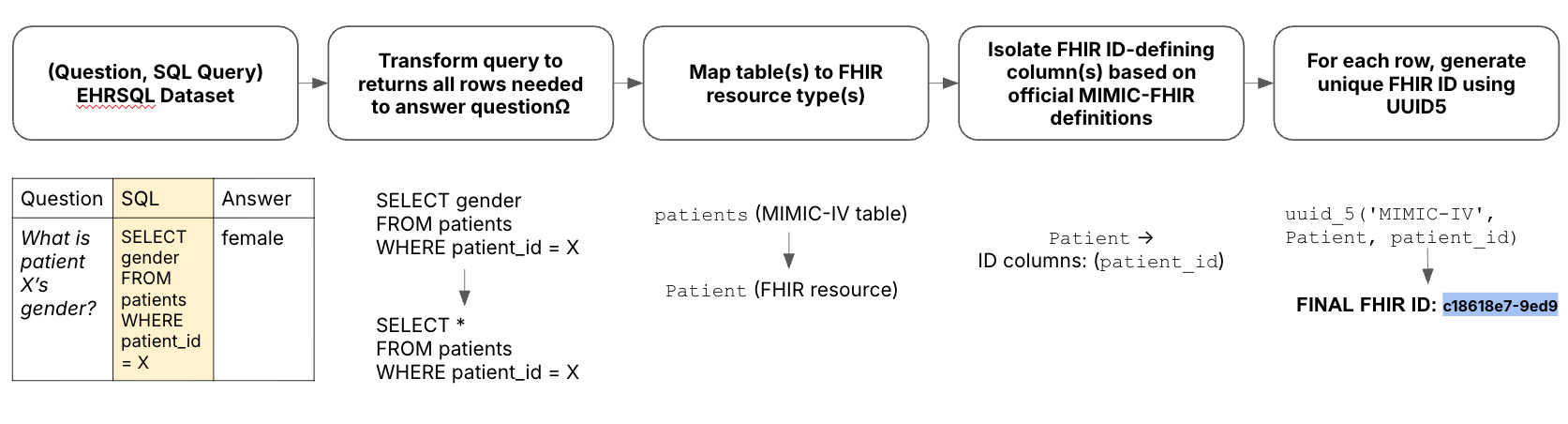
- The paper introduces FHIR-AgentBench, a comprehensive benchmark for evaluating LLM agents in realistic, interoperable EHR question answering.
- It employs a two-step evaluation process using metrics like retrieval precision and answer correctness to assess multi-turn and code-integrated approaches.
- Despite the benefits of multi-turn interaction, retrieval precision remains a bottleneck, emphasizing the need for improved parsing of complex FHIR structures.
FHIR-AgentBench: Benchmarking LLM Agents for Realistic Interoperable EHR Question Answering
Introduction
LLMs in healthcare have been evolving to handle complex, real-world data in Electronic Health Records (EHRs). The introduction of Health Level Seven Fast Healthcare Interoperability Resources (HL7 FHIR) demands a new approach for evaluating these models, which prior benchmarks have not adequately addressed. FHIR-AgentBench fills this gap by providing a comprehensive benchmark that evaluates the capabilities of LLM agents in the context of FHIR-based question answering, grounded in real-world clinical scenarios.
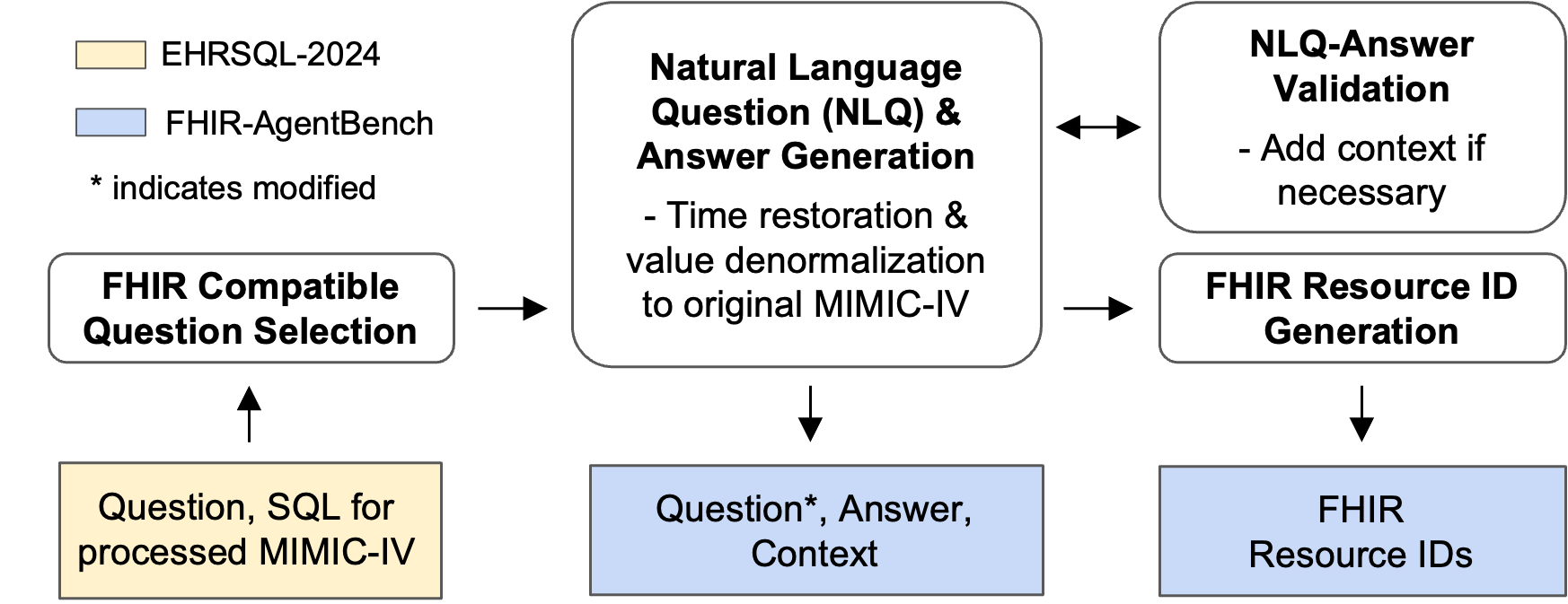
Figure 1: Overview of the construction process for FHIR-AgentBench.
Benchmark Overview
FHIR-AgentBench evaluates LLM agents across dimensions critical for clinical applications: clinical authenticity, data complexity, and interoperability via FHIR. It comprises 2,931 real-world questions derived from the MIMIC-IV-FHIR dataset, a de-identified patient database known for its comprehensive coverage of clinical events. The benchmark challenges LLMs to perform various complex tasks, including multi-step reasoning, robust data retrieval, and synthesis across diverse FHIR resources.
The benchmark construction process involves selecting relevant questions, generating natural language questions (NLQs) and answers, and verifying these against FHIR resources (Figure 1). The focus on realism ensures that the benchmark tests agents on tasks reflective of actual clinical inquiries, thus providing a more rigorous evaluation of their real-world utility.
Agent Evaluation
In evaluating agent performance, the FHIR-AgentBench employs a two-step task: first, retrieving relevant data from FHIR resources, and second, generating correct answers. Metrics used include retrieval precision and recall, alongside answer correctness. Notably, retrieval precision is often low due to the extensive query noise introduced during the retrieval phase, underscoring the benchmark's challenging nature.
Our experiments show that multi-turn agents, equipped with code interpreters, significantly outperform single-turn approaches, achieving up to 50% answer correctness. These results highlight the importance of iterative reasoning and procedural logic when dealing with FHIR’s nested data structures. However, the challenge remains substantial, with no single LLM surpassing others convincingly across all metrics.
Key Findings
- Multi-Turn Interaction: Agents capable of iterative reasoning exhibit higher recall and better answer correctness. This suggests that decomposing tasks into multiple interactions aids in navigating FHIR’s complexity.
- Code Integration: The use of code generation improves agents' capabilities to parse and interpret data, crucial for understanding FHIR’s graph-like resource structures.
- Retrieval Challenges: Despite retrieval attempts, the precision remains a bottleneck, impacting the agents' ability to synthesize accurate responses from retrieved data.
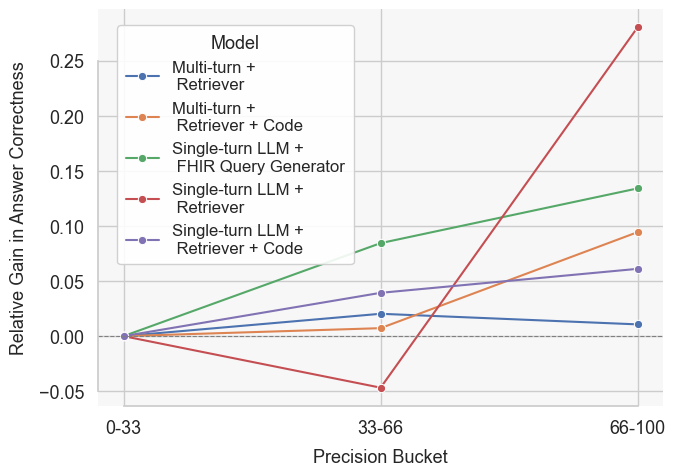
Figure 2: Relative gain in answer correctness across precision buckets for the o4-mini model under different agent frameworks. Gains are calculated after filtering to questions with perfect recall, isolating the effect of unnecessary resources on answer correctness.
Error Analysis
Understanding agent failure modes provides crucial insights for future improvements. Common errors include:
Conclusion
FHIR-AgentBench presents a significant step forward in benchmarking LLMs for realistic EHR interoperability. By challenging agents with complex, clinically relevant tasks grounded in the FHIR framework, it offers a detailed view of current capabilities and areas needing improvement. Future research could expand the dataset scope and refine agent architectures to better handle FHIR’s intricacies, ultimately aiming for robust, deployable clinical AI applications. By openly releasing this benchmark, we provide a platform for advancing the field toward truly interoperable AI solutions in healthcare.