Perspectra: Choosing Your Experts Enhances Critical Thinking in Multi-Agent Research Ideation
Abstract: Recent advances in multi-agent systems (MAS) enable tools for information search and ideation by assigning personas to agents. However, how users can effectively control, steer, and critically evaluate collaboration among multiple domain-expert agents remains underexplored. We present Perspectra, an interactive MAS that visualizes and structures deliberation among LLM agents via a forum-style interface, supporting @-mention to invite targeted agents, threading for parallel exploration, with a real-time mind map for visualizing arguments and rationales. In a within-subjects study with 18 participants, we compared Perspectra to a group-chat baseline as they developed research proposals. Our findings show that Perspectra significantly increased the frequency and depth of critical-thinking behaviors, elicited more interdisciplinary replies, and led to more frequent proposal revisions than the group chat condition. We discuss implications for designing multi-agent tools that scaffold critical thinking by supporting user control over multi-agent adversarial discourse.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces Perspectra, a new computer tool that helps people come up with research ideas and think more critically. Instead of talking to one AI, Perspectra lets you talk to several AI “experts,” each playing a different role (like a policy expert, a data scientist, or a psychologist). The tool feels like an online forum: you can start threads on different topics, tag specific experts to join, and see a mind map that shows how the discussion and arguments connect.
What were they trying to find out?
The researchers wanted to know:
- How can we give users better control over multiple AI experts so discussions are easier to steer and understand?
- Does letting users choose which experts to involve—and structuring the conversation—help people think more deeply and improve their research ideas?
- Will this approach be especially helpful for interdisciplinary topics (ideas that mix different fields)?
How did they do it?
Perspectra combines familiar ideas with smart AI in a way that’s easy to navigate.
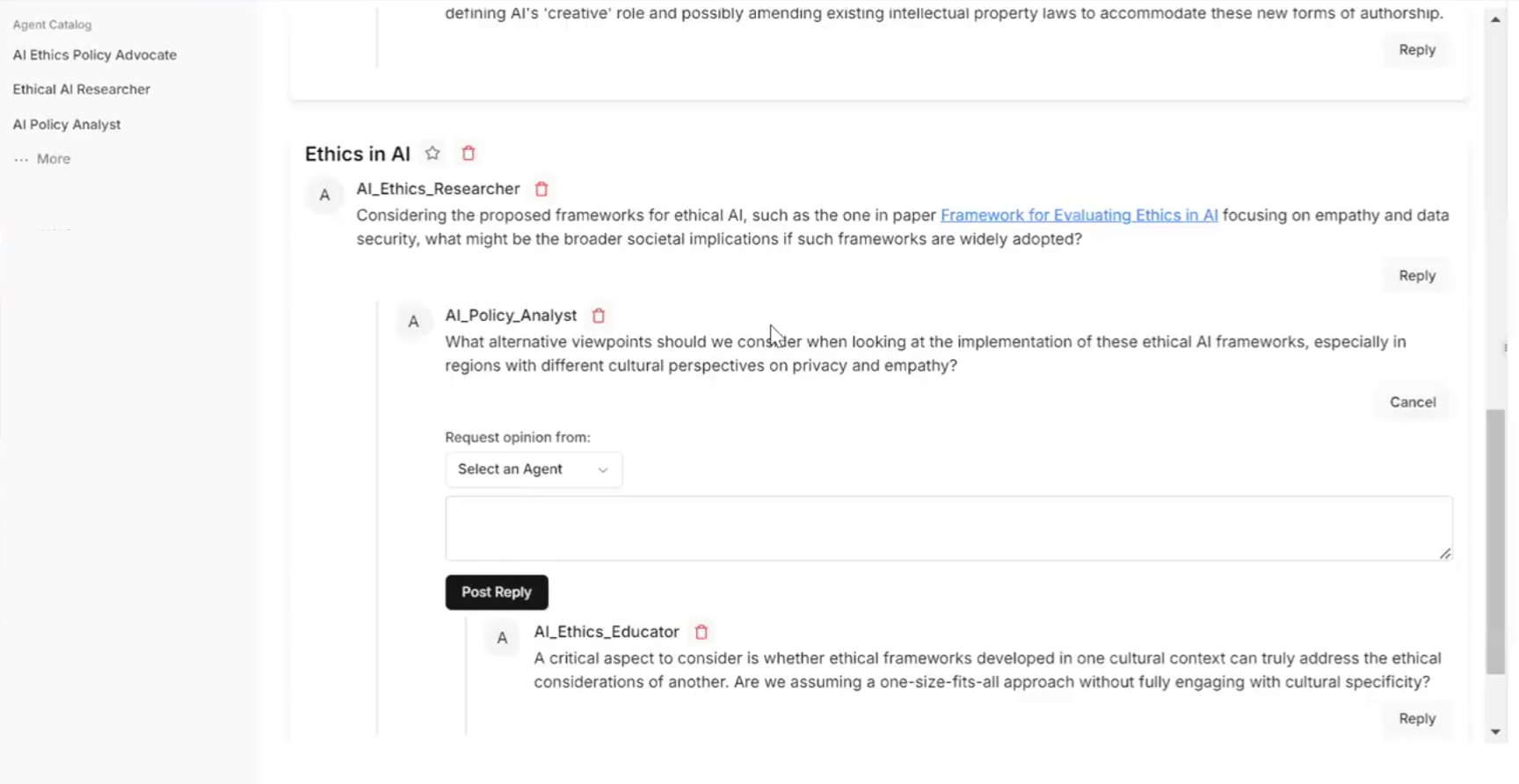
- Forum-style threads: Imagine a message board where each thread is about a sub-topic. You can reply, start new threads, and keep related messages together so nothing gets lost.
- @-mentions: Just like tagging someone on social media, you can invite specific AI experts into a thread. This means you decide who joins which part of the conversation.
- “What-if” previews: You can quickly see a hypothetical reply from a chosen expert and stance (agree, disagree, or question), like asking, “What would the critic say?”
- Mind map: Picture a visual map with bubbles and lines showing claims, support, questions, and counter-arguments. It zooms in and out so you can see the big picture or details without getting overwhelmed.
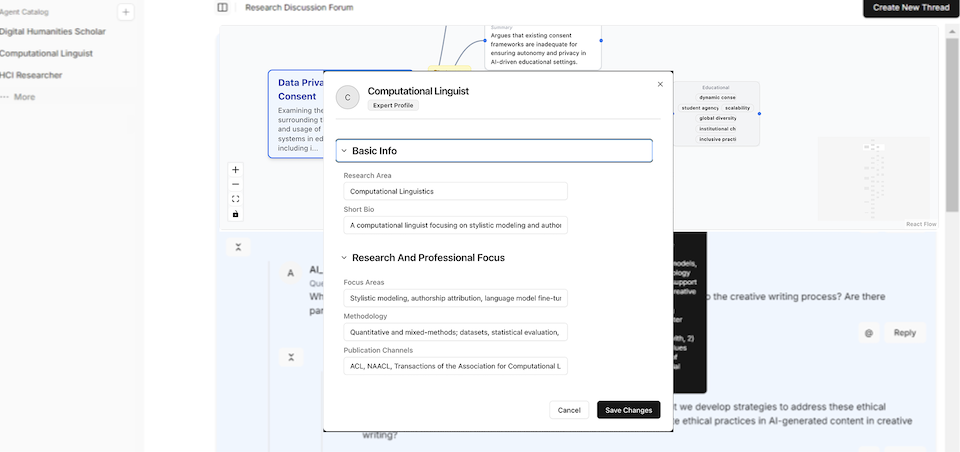
Behind the scenes, each AI expert has:
- A persona (a background profile, like methods they use and what they care about).
- A memory (it remembers earlier parts of the discussion and how its ideas have changed).
- Access to research papers (it can search and cite sources).
To test Perspectra, the team ran a “within-subjects” study with 18 people. That means every participant used both:
- Perspectra, and
- A simpler “group chat” setup (like one conversation where all AI agents talk together), which served as the baseline.
Participants used both tools to develop short interdisciplinary research proposals. The researchers looked at chat logs, surveys, think-aloud comments, and interviews to understand what changed in people’s thinking and their final proposals.
What did they find, and why does it matter?
Here are the key results from comparing Perspectra to the group chat:
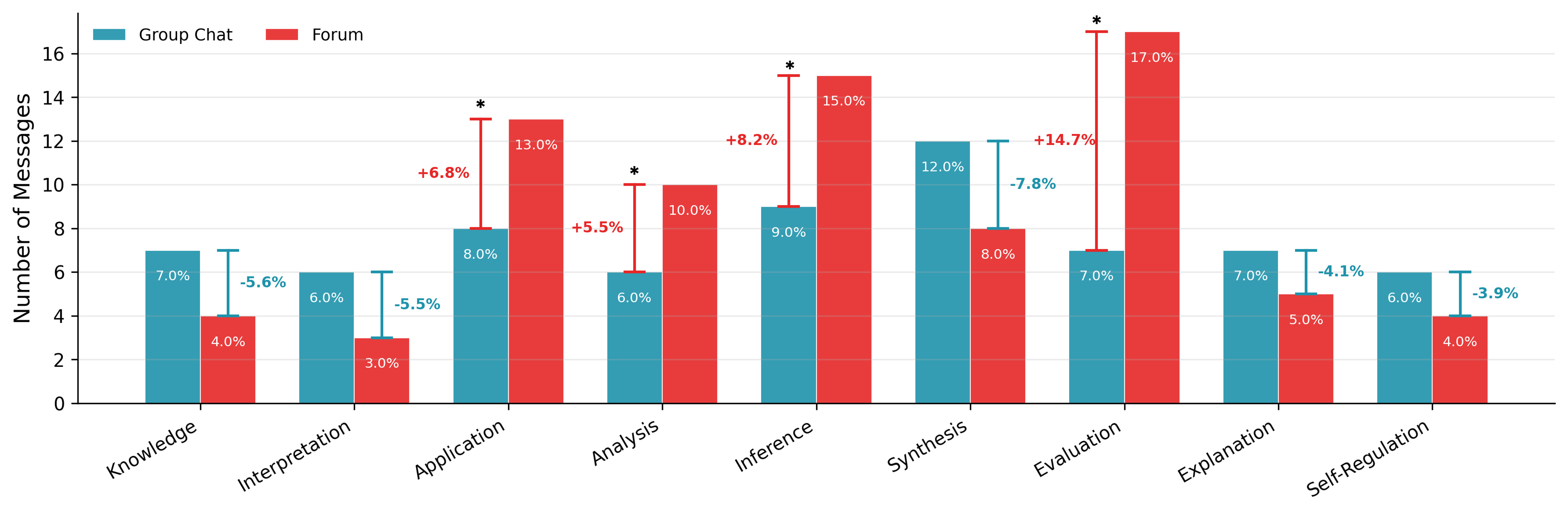
- More critical thinking: With Perspectra, people did more high-level thinking—like analyzing assumptions, applying ideas to new situations, drawing conclusions from evidence, and evaluating claims. This is the kind of deep thinking schools and scientists care about.
- More interdisciplinary replies: The forum-style setup invited more cross-field conversations, which helps when building ideas that mix different areas.
- More and better revisions: People revised their proposals more often and improved them more with Perspectra than with the group chat. That suggests Perspectra changes not just the discussion, but the final work.
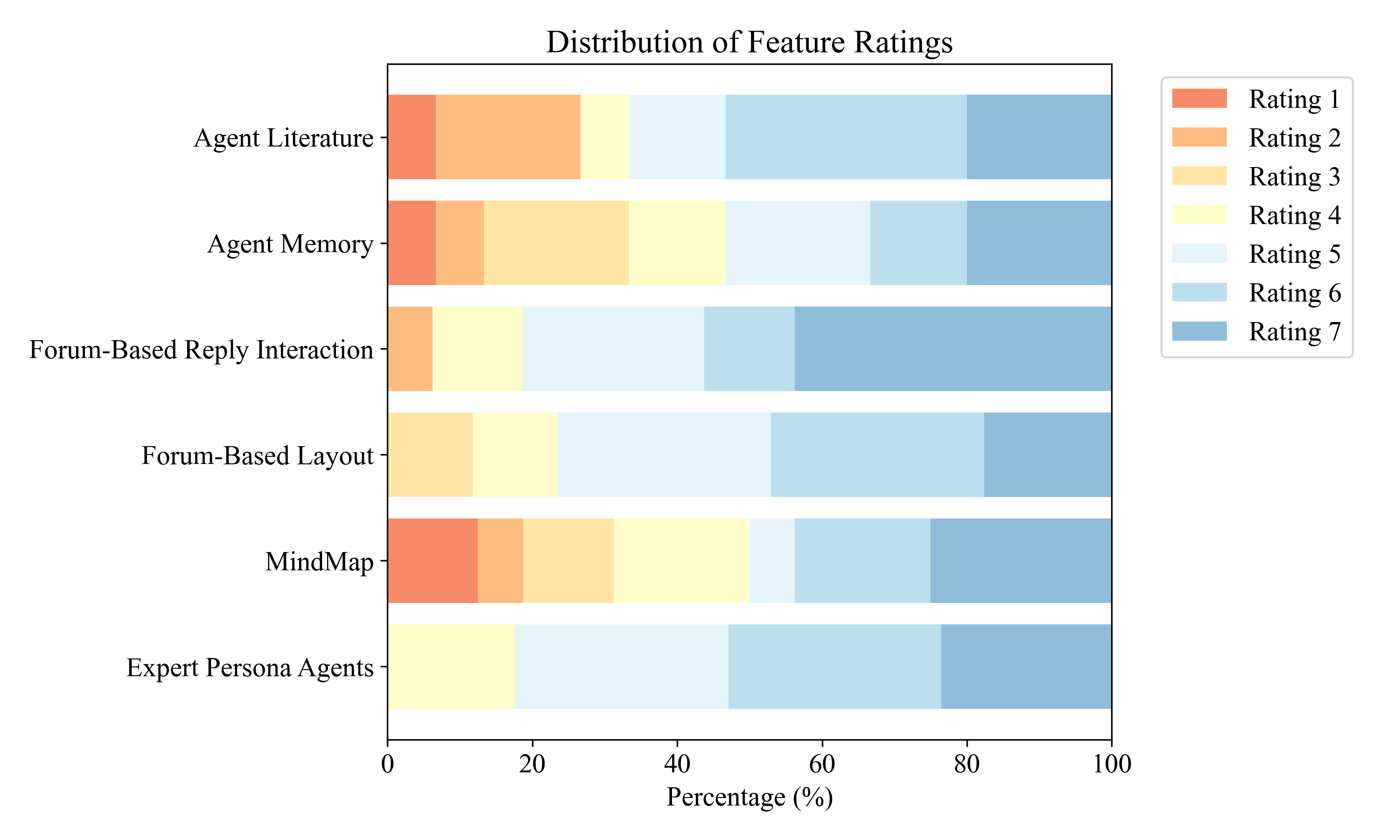
- Useful structure and flexibility: Features like @-mentions and mind maps helped users control the discussion and understand the reasoning behind the AI’s responses. Some users even invented helpful habits, like leaving TODO notes and using the system to double-check claims.
- Right balance of control: Many participants preferred more control and structure at the start (when exploring broadly), and less control later (when focusing deeply). Perspectra supports that balance.
Why it matters: When AI tools are designed to help people argue, question, and compare different viewpoints, users don’t just collect facts—they actually learn to think better. That’s especially important now that AI can make it easy to skim or accept answers without evaluating them.
What’s the impact?
Perspectra shows a promising direction for future AI tools:
- Support critical thinking: Tools should make disagreements and questions part of the process, not something to avoid. Seeing CLAIM, SUPPORT, QUESTION, and REBUT moves makes argument structure clear.
- Give users control: Let people choose which experts to involve in which threads, to avoid overload and keep conversations focused.
- Reduce confusion: Use visual maps and clear labels to make complex discussions easier to follow.
- Help real work: This approach doesn’t just feel better—it leads to stronger research proposals and better revisions.
In simple terms: Perspectra helps you build smarter ideas by letting you guide a friendly debate among AI experts, see the reasoning clearly, and organize everything so you can learn and improve faster.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored, to guide future research and development.
- Study scope and generalizability: Validate effects beyond a short, single-session lab task by running longitudinal field deployments (e.g., 4–8 weeks) embedded in authentic research workflows.
- Participant diversity: Assess whether findings hold across expertise levels (undergraduates, PhD students, senior researchers), disciplines, and cultural/language backgrounds; report demographics and stratified effects.
- Ecological validity: Examine performance when users bring their own ongoing projects (with messy constraints, deadlines, collaborators) rather than a bounded prompt-driven proposal task.
- Stronger baselines: Compare against state-of-the-art multi-agent research tools (e.g., ResearchAgent, NovelSeek, MDTeamGPT) and threaded-chat UIs with partial structure to isolate Perspectra’s added value.
- Feature ablations: Run controlled ablation studies to quantify the unique contributions of @-mentions, thread branching, “what-if” preview, deliberation labels, and the mind map visualization.
- Measurement validity: Provide blinded expert ratings of proposal quality with inter-rater reliability statistics, and triangulate with objective task performance metrics beyond edit counts.
- Critical-thinking operationalization: Detail coding schemes, reliability, and construct validity; test whether measured behaviors transfer to independent tasks without the tool (skill vs. in-situ behavior).
- Cognitive load: Directly measure cognitive load (e.g., NASA-TLX), time-on-task, switching costs across threads, and decision latency to validate claims about reduced burden and improved sensemaking.
- Scalability of visualization: Stress-test the mind map and threads with large, branching debates (100–500+ posts) to evaluate readability, navigation, and summarization fidelity under graph explosion.
- Accuracy of deliberation labels: Assess how often agents misapply CLAIM/SUPPORT/REBUT/QUESTION labels, and whether mislabeling degrades user comprehension; consider post-hoc classifier correction.
- “What-if” preview clarity: Investigate whether users conflate hypothetical agent replies with actual consensus; evaluate UI cues, user mental models, and downstream decision errors due to counterfactuals.
- Persona fidelity and bias: Audit persona profiles (from Persona Hub + clustering) for stereotyping, overgeneralization, or methodological bias; test user-authored vs. prebuilt personas and their effects.
- Literature reliability: Measure factual accuracy, citation validity, source quality, and hallucination rates in GraphRAG outputs; implement and evaluate citation verification and traceability UX.
- Tool retrieval coverage: Quantify recall/precision of the literature pipeline across domains (e.g., HCI vs. biomed), newer vs. older papers, and paywalled content; report failure modes.
- Memory and drift: Evaluate long-term agent memory behaviors (stability, contradiction, error propagation) and whether the memory viewer actually improves user trust and diagnosis of agent shifts.
- Autonomy vs. control: Explore adaptive orchestration that recommends personas, stances, or thread branching when appropriate, and empirically derive optimal levels of user control to avoid overload.
- Adversarial discourse safety: Study how structured dissent affects user trust, anxiety, and groupthink mitigation; design guardrails for harmful or discriminatory “devil’s advocate” moves.
- Multi-user collaboration: Extend to settings where multiple humans co-orchestrate agents; examine turn-taking, conflict resolution, shared awareness, and provenance of edits.
- Accessibility and inclusion: Evaluate accessibility of the forum and mind map (screen readers, keyboard navigation, color vision deficiencies) and design alternatives for non-visual interaction.
- Internationalization: Test multilingual support for both users and agents; evaluate cross-lingual retrieval and the stability of deliberation labels across languages.
- Modal breadth: Assess how Perspectra supports non-textual artifacts (figures, code, datasets, equations) and multi-modal ideation; integrate code execution/search and data visualization tools.
- Cost/latency and responsiveness: Report token/cost budgets, average latency per turn, and perceived responsiveness; examine how delays affect exploration depth and user engagement.
- Privacy and IP: Analyze risks of sharing unpublished research ideas with external LLMs; specify data handling, opt-out, and on-prem/self-hosted options for sensitive domains.
- Confounds in backend differences: Separate UI effects from backend deliberation action-space differences by running Perspectra UI with and without action labels and by adding labels to the baseline.
- Thread management: Develop and test mechanisms for merging threads, cross-thread linking, deduplication, and global synthesis to mitigate fragmentation and lost context.
- Persuasion and influence: Study whether agents’ rhetorical styles or persona authority unduly steer user judgments; add explanations of uncertainty and calibrated confidence displays.
- User onboarding and learning curve: Measure time to proficiency, error patterns, and needed scaffolds/tutorials for effectively using @-mentions, branching, and the mind map.
- Domain transfer: Test Perspectra in domains with high stakes or strict methodology (e.g., clinical, legal, security) to assess compliance, auditability, and domain-specific constraints.
- Outcome durability: Examine whether improved proposals lead to downstream successes (e.g., advisor approvals, peer reviews, funding decisions) and whether gains persist after tool use stops.
Practical Applications
Immediate Applications
The paper’s system (Perspectra) and study findings can be translated into deployable workflows wherever knowledge workers need structured deliberation, explicit argument mapping, and user control over multi‑agent LLMs.
- Academia — Research ideation and proposal development (higher ed, research labs)
- Use case: Draft and iteratively refine literature-backed research proposals by inviting targeted “expert” personas via @‑mentions, exploring alternatives with what‑if stances, and tracking arguments in a mind map.
- Tools/products: A Perspectra-like web app; Overleaf/Notion/Confluence plugins that turn notes into threaded agent panels with argument maps; Zotero/Mendeley extension to ingest citations into GraphRAG.
- Dependencies/assumptions: Access to reliable LLMs; integration with paper APIs (Semantic Scholar/OpenAlex) and institution proxies; user training to interpret argument maps; human oversight for factuality and citations.
- Academia — Grant-panel and peer‑review rehearsal
- Use case: Simulate critical reviews from different disciplinary reviewers; @‑mention dissenting personas to “red team” a proposal and improve rebuttals.
- Tools/products: “Reviewer panel simulator” with preset personas mapped to funding agencies’ typical criteria.
- Dependencies: Up-to-date agency criteria encoded in personas; governance for disclosure and bias mitigation.
- Education — Critical thinking and argumentation practice (K‑12, higher ed)
- Use case: Classroom debates and assignments where students thread questions, tag contrasting personas, and see ISSUE/CLAIM/SUPPORT/REBUT relationships; instructors assess higher‑order thinking.
- Tools/products: LMS plugins (Canvas/Moodle) with forum-to-mind‑map views; auto-rubrics capturing application/analysis/evaluation behaviors.
- Dependencies: Age‑appropriate content filters; teacher PD on facilitating multi‑agent discourse; logging for academic integrity.
- Industry R&D — Cross‑functional ideation and design reviews
- Use case: Product discovery and design critiques with agents embodying UX, security, compliance, and business roles; branch threads for alternatives and trade‑offs; consolidate into decision records.
- Tools/products: Slack/Teams add‑ins that instantiate persona panels in channel threads; ADR (Architecture Decision Record) assistants visualizing rationales.
- Dependencies: Secure access to internal docs; persona curation reflecting company standards; data privacy controls.
- Policy and governance — Drafting and “red teaming” regulations or guidelines
- Use case: Simulate stakeholder panels (e.g., privacy advocate, regulator, industry rep) to stress‑test policy text and uncover unintended consequences.
- Tools/products: “Policy deliberation cockpit” with evidence-traceable claims and rebuttals; export to consultation briefs.
- Dependencies: Up-to-date legal corpora; traceability from claims to sources; human legal review.
- Software engineering — Requirements, threat modeling, and code review
- Use case: Threaded discussions with security, performance, and accessibility personas; what‑if “disagree” stances to surface risks; map outcomes to tickets.
- Tools/products: GitHub/GitLab/VS Code extensions surfacing argument maps in PRs/issues; integration with risk registers.
- Dependencies: Repository access; prompt hardening to avoid code hallucinations; policy for code exposure.
- Knowledge management — Sensemaking across parallel topics
- Use case: Break large investigations into threads; use semantic zoom to navigate and summarize; capture decisions with rationale lineage.
- Tools/products: Mind‑map SDK/widget embeddable in wikis and internal portals; export to Markdown/PDF with issue–claim structure.
- Dependencies: Enterprise search connectors; indexing governance; performance on large graphs.
- Consulting and professional services — Client brief development
- Use case: Rapidly assemble multi‑disciplinary viewpoints to refine problem statements, hypotheses, and engagement plans.
- Tools/products: Proposal workbench that logs claims, supports, and questions per stakeholder persona.
- Dependencies: Confidentiality agreements; sandboxed, self‑hosted LLMs for sensitive data.
- Healthcare (non‑clinical operations) — Protocol and policy drafting
- Use case: Develop clinic operations protocols (e.g., scheduling, consent workflows) with QA, ethics, and patient‑advocacy personas; map compliance rationales.
- Tools/products: Hospital policy assistant with argument maps, not for clinical diagnosis/treatment.
- Dependencies: Strict PHI safeguards; compliance/legal oversight; avoid clinical decision support unless regulated.
- Daily life — Structured decision support
- Use case: Major purchases or planning (e.g., choosing a degree program or car) by inviting cost/benefit/environmental personas and comparing claims/rebuts in a map.
- Tools/products: Consumer-facing “multi‑advisor” app with threaded alternatives and rationale exports.
- Dependencies: Clear disclaimers; curated data sources for consumer accuracy; simple UX to avoid cognitive overload.
- Media and communications — Editorial planning and fact checking
- Use case: Newsroom pre‑mortems where fact‑checker and legal personas challenge claims; map sources to statements.
- Tools/products: CMS plugin for argument tracing from article assertions to citations.
- Dependencies: Verified source pipelines; editorial policy alignment; time-to-publish constraints.
- Finance (non‑trading research) — Investment memo scaffolding
- Use case: Analyst memos with bull/bear personas and risk/compliance perspectives in parallel threads; capture rationale lineage.
- Tools/products: Research workbench integrated with document stores and compliance logging.
- Dependencies: Information barrier controls; supervision for market risk; model audit trails.
Long‑Term Applications
These require further research, scaling, evaluation, or regulatory adaptation to reach production maturity.
- Enterprise‑grade, multi‑user deliberation platforms with provenance and audit
- Vision: Collaborative human+agent forums where teams co‑author decisions with cryptographically signed evidence trails and stance dynamics.
- Dependencies: Standards for argument provenance; role‑based access control; scalability for thousands of threads.
- Evidence‑grounded, high‑assurance MAS for regulated domains
- Vision: FDA/EMA/SEC‑compliant deliberation tools where every claim links to vetted sources and uncertainty is quantified.
- Dependencies: Robust fact‑checking, calibration, and adjudication workflows; third‑party audits; model governance frameworks.
- Mixed human–AI expert panels for policy consultation and public engagement
- Vision: Town‑hall platforms where AI personas scaffold diverse viewpoints and citizens explore what‑if stances before voting/feedback.
- Dependencies: Bias audits, transparency mandates, safeguards against persuasion or misinformation; multilingual support.
- Healthcare clinical decision conference simulators (e.g., tumor boards) — research prototypes only
- Vision: Pre‑meeting preparation tools that surface literature-backed arguments and counterpoints to aid clinicians’ discussion (not autonomous decisions).
- Dependencies: Regulatory clearance as clinical support tools; EHR integration; rigorous validation with outcomes data.
- Autonomous research co‑pilots integrating deep‑research agents
- Vision: Systems that plan literature searches, synthesize findings, and produce living argument maps that update as evidence shifts.
- Dependencies: Continual ingestion pipelines; citation reliability scoring; detect and correct hallucinations.
- Curriculum‑embedded critical thinking analytics
- Vision: Longitudinal dashboards measuring students’ application/analysis/evaluation behaviors across courses via MAS interactions.
- Dependencies: Validated rubrics; privacy-preserving learning analytics; instructor buy‑in and alignment with assessment standards.
- Organizational memory and decision‑rationale graphs
- Vision: Company‑wide knowledge graphs that link decisions to claims, supports, and rebuttals across projects for reuse and audit.
- Dependencies: Interoperability with data catalogs and wikis; information lifecycle policies; cultural adoption.
- Persona marketplaces and governance
- Vision: Curated libraries of domain‑validated personas (e.g., “FDA compliance officer,” “safety engineer”) with versioning and performance benchmarks.
- Dependencies: Certification processes, IP/licensing frameworks, continuous evaluation against drift and bias.
- Cross‑cultural, multilingual deliberation frameworks
- Vision: Argument models that adapt to rhetorical norms and legal traditions across languages and regions.
- Dependencies: Multilingual LLM quality; culturally aware argument taxonomies; evaluation datasets.
- Real‑time meeting facilitation and minute‑taking with stance tracking
- Vision: Live capture of human discussion with automatic ISSUE/CLAIM/SUPPORT/REBUT labeling and action‑item extraction.
- Dependencies: Accurate speech‑to‑text; identity/role detection; consent and privacy compliance.
- Safety and risk‑aware agents that natively surface dissent
- Vision: MAS that intentionally generate structured counter‑arguments (“devil’s advocate”) calibrated to risk profiles.
- Dependencies: Robust adversarial prompting strategies; safeguards against false disagreement; user controls for cognitive load.
Cross‑cutting assumptions and dependencies
- Model quality and cost: Requires reliable, well‑calibrated LLMs (or strong small models) and affordable inference for multi‑agent turns.
- Data access: Integrations with literature APIs, enterprise search, and GraphRAG stores; citation tracing is essential for credibility.
- Human oversight: Findings must be reviewed for factuality; systems should expose uncertainty and rationale, not chain‑of‑thought.
- Usability: Threaded forums and mind maps reduce overload only if well‑designed; training and onboarding may be required.
- Governance: Privacy, security, and IP safeguards; logging and audit for regulated uses; bias and safety evaluations for personas.
- Change management: Adoption depends on fitting into existing tools (Slack/Teams, LMS, wikis, IDEs) and workflows.
Glossary
- @-mention: An interface convention for tagging and notifying specific participants to draw them into a conversation. "supporting @-mention to invite targeted agents"
- adversarial discourse: A structured exchange where participants take opposing stances to surface tensions and improve reasoning quality. "supporting user control over multi-agent adversarial discourse."
- Agent Dialogue Framework (ADF): A formal model for structuring agent interactions, specifying dialogue types, moves, and rules. "the Agent Dialogue Framework (ADF) \cite{mcburney2002games}"
- agglomerative clustering: A bottom-up hierarchical clustering method that iteratively merges the closest clusters. "using agglomerative clustering;"
- argumentation speech acts: Formal categories of communicative moves in argumentation (e.g., assert, challenge, concede). "on argumentation speech acts, Toulmin's model of argument structure"
- AutoGen: A framework for building and orchestrating multi-agent LLM systems with tool use and coordination. "implemented using AutoGen~\cite{wu2024autogen} framework."
- Cognitive Synergy: The phenomenon where combined, complementary cognitive processes yield capabilities beyond individual components. "Cognitive Synergy as a driver of complex human cognition~\cite{luppi2022synergistic}."
- cognitive load: The mental effort required to process information, which interfaces try to minimize to aid understanding. "reduce cognitive load and enhance ideation"
- deep research agents: LLM-driven agents that conduct extended literature search, retrieval, and synthesis for in-depth reports. "deep research agents~\cite{huang2025deep,zheng2025deepresearcher}."
- devil's-advocate agents: Agents designed to challenge prevailing views to reduce conformity and stimulate critical thinking. "devil's-advocate agents amplify minority voices to counter conformity pressure"
- Distributed Cognition theory: A perspective that cognitive processes are distributed across people, artifacts, and environments. "Distributed Cognition theory~\cite{hutchins1995cognition} has been applied in a wide range of system designs to support sensemaking"
- epistemic orientation: A stance toward what counts as knowledge and how it is justified within a field. "discipline, methodological stance, research role, epistemic orientation,"
- Graph-based retrieval database: A storage and query system that indexes knowledge as a graph to enable structured, relation-aware retrieval. "a graph-based retrieval database to support cross-perspective ideation"
- GraphRAG: A retrieval-augmented generation approach that grounds LLM outputs in graph-structured knowledge. "A GraphRAG database (implemented using a modified version of LightRAG~\cite{guo2024lightrag} to support citation tracing)"
- knowledge graph: A graph of entities and relations used to represent and query structured knowledge. "constructs and queries a knowledge graph over both entities and text snippets extracted from papers."
- LangMem: A persistent memory component for LLM agents that stores and retrieves long-term interaction snippets. "a modified version of LangMem"
- LightRAG: A lightweight implementation of graph-based retrieval-augmented generation for grounding model outputs. "LightRAG~\cite{guo2024lightrag}"
- locutions: Conventionalized utterance types in dialogue protocols that define the function of a speech act. "a small set of locutions adapted from \citet{prakken2006formal}"
- methodological stance: A researcher’s preferred approaches and methods (e.g., qualitative, quantitative, mixed). "discipline, methodological stance, research role, epistemic orientation,"
- Multi-Agent Systems (MAS): Systems composed of multiple interacting agents that collaborate to solve tasks. "LLM-based Multi-Agent Systems (MAS)~\cite{guo2024large} are increasingly being adopted"
- OpenAlex: An open index of scholarly works, authors, venues, and institutions, accessible via APIs. "OpenAlex~\cite{priem2022openalex}"
- Persona Hub: A dataset of structured persona profiles used to initialize agent backgrounds. "Persona Hub dataset \cite{ge2024scaling}"
- ReAct-style reasoning loop: An approach that interleaves reasoning with actions (e.g., tool calls) to plan, retrieve, and revise before responding. "Agents follow a ReAct-style reasoning loop~\cite{yao2023react} integrated with Autogen's tool-calling capabilities."
- Semantic Scholar (S2) API: An API for programmatic access to Semantic Scholar’s scholarly metadata and search. "the Semantic Scholar (S2) API~\cite{kinney2023semantic}"
- semantic zooming: A UI technique where the level of detail shown changes with zoom level to aid navigation. "including semantic zooming to support sensemaking."
- sensemaking: The process of organizing information to build understanding, particularly in complex or unfamiliar domains. "to support sensemaking."
- thread branching: Creating new discussion threads from specific posts to explore subtopics in parallel. "thread branching that facilitates parallel exploration of multiple topics"
- tool-calling: Mechanisms that allow LLMs to invoke external tools or functions during reasoning. "Autogen's tool-calling capabilities."
- Toulmin's model of argument structure: A framework that decomposes arguments into components like Claim, Grounds, Warrant, Backing, and Rebuttal. "Toulmin's model of argument structure \cite{toulmin2003uses}"
- Walton and Krabbe's dialogue types and commitment rules: Theories classifying dialogues (e.g., deliberation, persuasion) and tracking participants’ commitments. "Walton {paper_content} Krabbe's dialogue types and commitment rules \cite{walton1995commitment}"
- within-subjects study: An experimental design where each participant experiences all conditions for direct comparison. "In a within-subjects study with 18 participants,"
Collections
Sign up for free to add this paper to one or more collections.