- The paper introduces a robust pipeline using BERTopic, seed words, and LLM validation to automate the classification of civic proposals.
- It demonstrates that semi-supervised approaches with VCGE seed words significantly improve taxonomy alignment, as evidenced by ARI and NMI metrics.
- The study offers practical insights for real-time policy responses by streamlining civic engagement on Brazil's national participation platform.
Introduction
The paper "Semantic Clustering of Civic Proposals: A Case Study on Brazil's National Participation Platform" addresses the challenge of effectively organizing civic participation data on digital platforms. With the advent of platforms such as "Brasil Participativo" (BP), capturing and organizing civic proposals has become a high-priority task for governments. However, manual classification is impractical at scale, requiring interventions from specialists and alignment with official taxonomies. This study introduces a methodology combining BERTopic, seed words, and automatic validation by LLMs to efficiently transform vast amounts of citizen input into actionable data. The proposed approach seeks to preserve semantic coherence and align institutionally, promising minimal human intervention.
Methodology
The methodological framework is comprehensive, incorporating data extraction and pre-processing, internal validation and hyperparameter optimization, topic modeling, and external validation. Crucial to this pipeline are:
Results
Parameter Optimization
Researchers identified optimal configurations for BERTopic that maximized semantic coherence and thematic diversity. Using BERTimbau-large for embedding generation proved superior across different parameter settings due to its ability to balance internal coherence and thematic diversity.
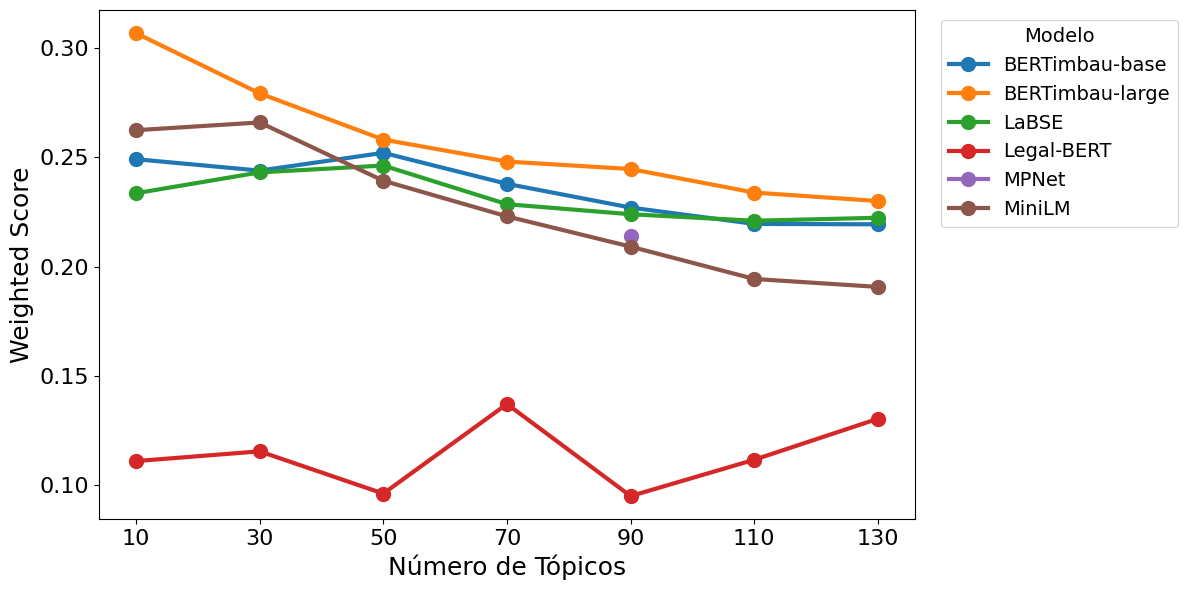
Figure 2: Weighted Score por Modelo e Número de Tópicos.
The optimal configuration for extracting 56 topics involved a uni-gram model with specific target numbers for topics and topic size. This configuration effectively balanced the thematic diversity and robustness of clusters.
Impact of Semi-supervision
The incorporation of seed words significantly improved semantic alignment with VCGE categories, enhancing both semantic coherence and resultant thematic consistency without substantially compromising topic diversity.
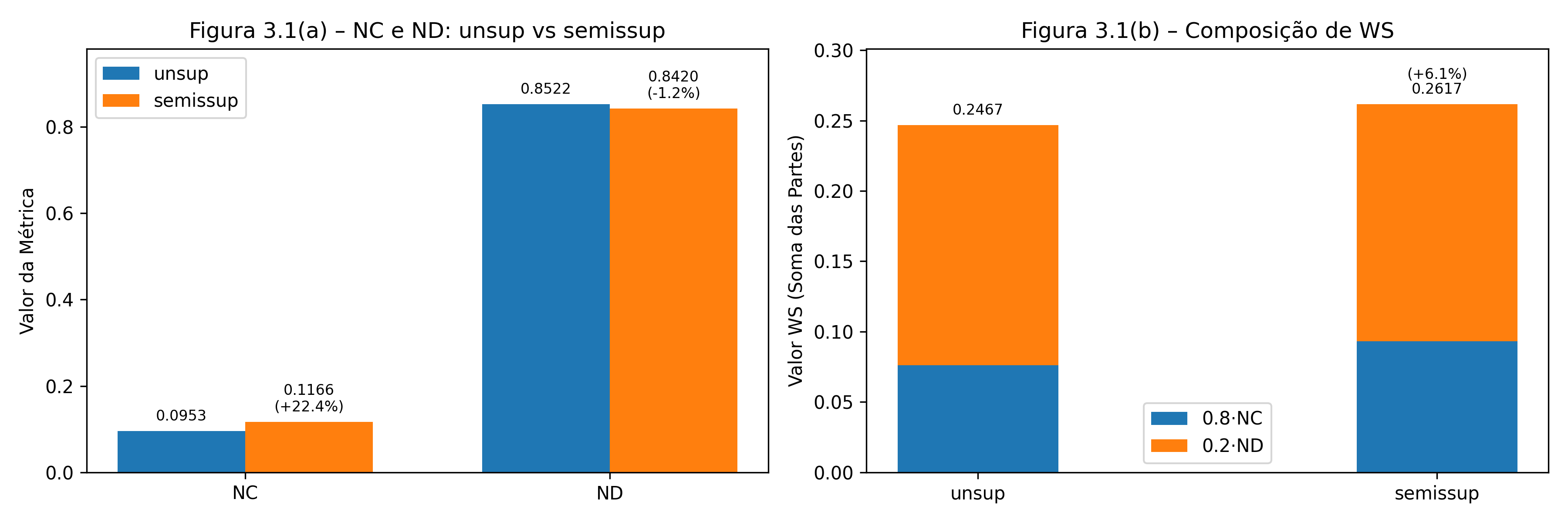
Figure 3: Comparação entre não-supervisionado e semi-supervisionado.
Comparative studies between unsupervised and semi-supervised approaches revealed measurable improvements, particularly in ARI and NMI metrics, which reflect the strength of the alignment with official taxonomy at both high-level and more detailed levels.
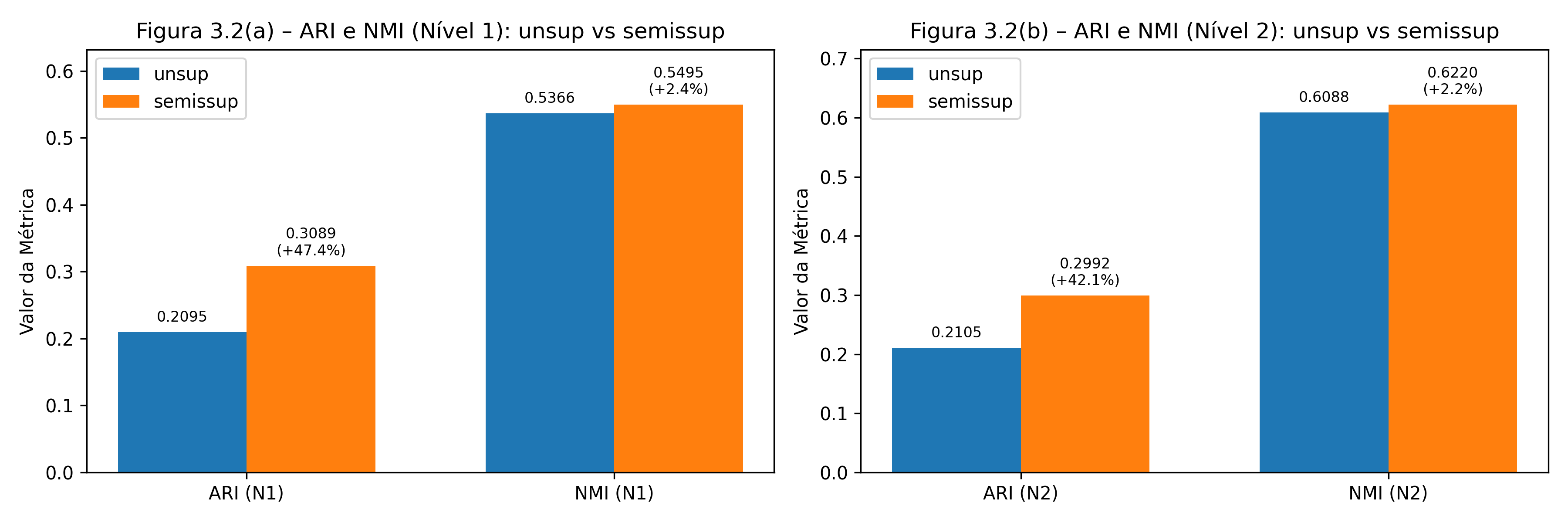
Figure 4: Métricas externas de alinhamento (ARI e NMI) nos nÃveis N1 e N2.
Discussion
Strategic and Practical Implications
The paper delineates a practical approach that can be seamlessly integrated into civic engagement platforms to automate the categorization process, significantly reducing manual workload while simultaneously ensuring high-quality information flow—vital for strategic policy formulation. This methodology supports real-time insights into emergent societal trends, such as shifts in public interest towards health or environmental concerns.
Enhancements and Future Directions
This research affirms the utility of integrating linguistic and institutional knowledge represented by specialized embeddings and official vocabularies to capture semantic complexities and alignments at scale. Future developments should focus on periodic expert review to refine seed words, ensuring model adaptability and relevance within dynamic democratic contexts.
Conclusion
This paper successfully presents a robust pipeline for transforming civic proposals into actionable intelligence for policymakers by leveraging BERTopic, specialized LLMs, and official taxonomies. While LLMs effectively automate many processes, ongoing human validation remains necessary for refining and adapting the underlying vocabularies and parameters in varied contexts. This study offers a scalable solution for enabling participatory governance, enriching public sector responsiveness and engagement with citizens.
