Rethinking Large Language Model Distillation: A Constrained Markov Decision Process Perspective
Abstract: We introduce a novel approach to LLM distillation by formulating it as a constrained reinforcement learning problem. While recent work has begun exploring the integration of task-specific rewards into distillation processes, existing methods typically rely on ad-hoc reward weighting. We propose a principled optimization framework that maximizes task-specific rewards while constraining the divergence from the teacher model to remain below a specified threshold. Our approach adapts constrained state augmented reinforcement learning to the distillation setting, introducing a modified reward function that maintains theoretical guarantees of constraint satisfaction without requiring state augmentation or teacher model access during deployment and without the computational overhead of the dual Lagrangian methods. Through extensive experiments on mathematical reasoning tasks, we demonstrate that our method achieves better constraint satisfaction rates and better reasoning compared to the soft Lagrangian relaxation baselines while maintaining competitive task performance. Our framework provides a theoretically grounded and practically efficient solution for reward-aware distillation in resource-constrained settings.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about teaching a smaller AI model to think well without needing as much computer power as a huge model. The authors look at “distillation,” where a small “student” model learns from a big “teacher” model. Their twist: they treat distillation like a game with points and rules. The goal is to get good scores on tasks (like solving math problems) while also staying close enough to how the teacher behaves. They show a new, efficient way to do this that gives strong results and solid guarantees.
What questions does the paper ask?
The paper focuses on three simple questions:
- How can a small model learn to solve tasks well (get high rewards) without copying the teacher too rigidly?
- Can we set a clear limit on how far the student is allowed to drift from the teacher, instead of guessing a tricky balance setting?
- Can we do this in a way that is efficient, works well for reasoning tasks, and doesn’t require access to the teacher when the student is deployed?
How did they do it? (Methods in simple terms)
Think of training the student model like playing a video game:
- You earn points for doing the task correctly (reward).
- You also must follow a rule: don’t stray too far from the teacher’s way of doing things. The “distance” between student and teacher behavior is measured using a number called KL divergence (you can think of it as “how different your choices are from the teacher’s choices”).
- There’s a “budget” (a fixed limit) for this distance. If you stay under the budget, you keep your points. If you go over it, you get a big penalty.
Here are the key ideas, with simple analogies:
- Reward-aware distillation: Instead of just copying the teacher, the student is encouraged to actually solve the task (like getting the right math answer) and gets points for that.
- A hard constraint (budget) instead of a guessy balance knob: Many past methods mix “do well on the task” and “stay close to the teacher” using a weight you have to tune (like a volume slider that’s touchy and changes with training). This paper sets a clear budget for how far you can drift—much easier to understand and control.
- Saute idea, made practical: There’s a known method (called Saute) that keeps track of how much of your “distance budget” you’ve used. But it normally needs extra tracking and access to the teacher at every step—even when the model is deployed—which defeats the point of having a stand-alone student. The authors modify the idea so:
- They don’t need extra state tracking during deployment.
- They don’t need the teacher model at test time.
- They still keep mathematical guarantees that the budget is respected.
How the penalty works:
- If you’re within budget, you get normal task rewards.
- If you go over budget, you get a large penalty—and it’s stronger if you stray more from the teacher. This teaches the student to avoid “bad” paths without shutting down exploration entirely.
Training style:
- The student tries things, gets rewards or penalties, and adjusts—this is reinforcement learning (RL) in a nutshell.
- The authors design the training so it’s stable and efficient without using heavy, expensive techniques that are hard to scale for big LLMs.
What did they find?
They tested their method on math reasoning tasks using pairs of teacher–student models (for example, a 7B-parameter teacher teaching a 1.5B student). They compared against strong baselines that:
- Only chase rewards (can get correct answers but often with flawed reasoning),
- Only mimic the teacher (stay close but often do worse on tasks),
- Or try to balance both with a tunable weight.
Main results and why they matter:
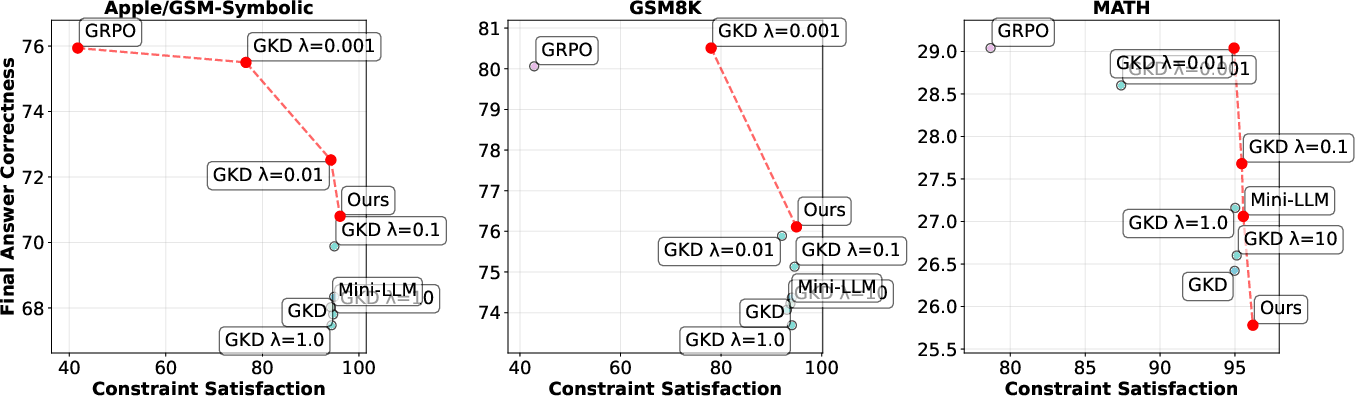
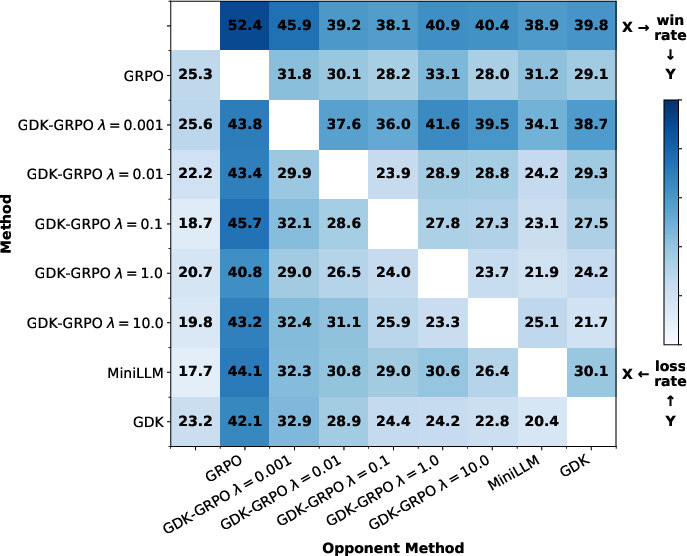
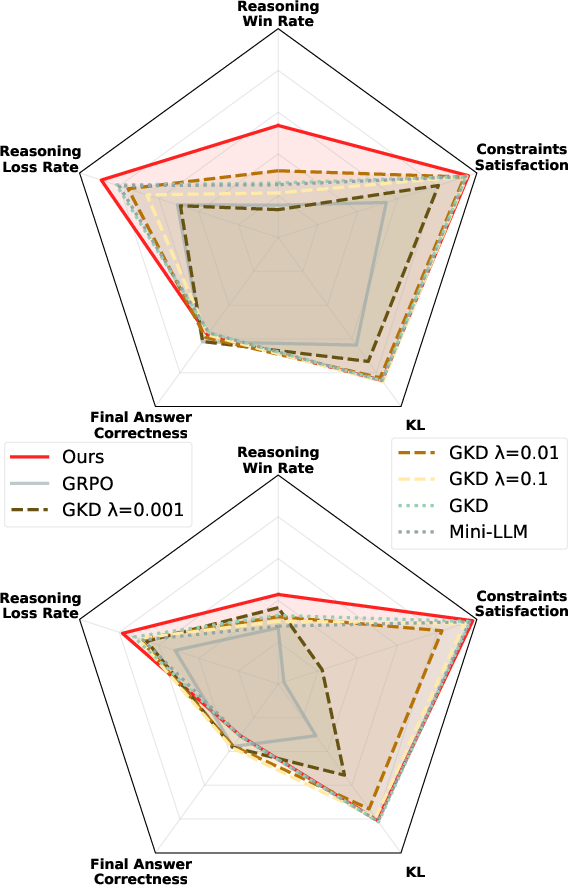
- Better reasoning quality: Their students not only get good final answers but also show clearer, more logical reasoning steps. This is important because good reasoning is more trustworthy and generalizes better.
- More reliable closeness to the teacher: Their method meets the “distance budget” more often than other approaches. This gives you a predictable “trust region” around the teacher’s behavior.
- Competitive task performance: Even while honoring the constraint, the student still does well on getting correct final answers.
- Reward alone isn’t enough: They show that reward-only methods might accidentally land on the right final answer while using incorrect steps (like rounding mistakes). Their method reduces that kind of “lucky but wrong reasoning.”
In short: They hit a better balance—good answers, good reasoning, and a controlled distance from the teacher.
Why it matters
- Easier to control: Setting a clear “distance budget” is simpler and more interpretable than tuning a fuzzy balancing weight.
- Practical deployment: The student doesn’t need the teacher at test time, saving compute and making real-world use easier.
- Stronger reasoning in small models: You can get small, efficient models that keep more of the teacher’s reasoning skill, which is crucial for tasks like math, code, and planning.
- Theoretical guarantees: They back their method with proofs that the constraint will be respected as a rule, not just a suggestion.
Takeaway
The paper rethinks how to shrink big LLMs into smaller ones without losing their thinking skills. By turning distillation into a “get points but obey the rules” RL setup—with a clear budget for how far the student can deviate from the teacher—they deliver students that are:
- Reasonable (good logical steps),
- Reliable (stay within a controlled distance from the teacher),
- And practical (no teacher needed at deployment).
This gives a principled, efficient path to building capable small models for devices and settings where compute and memory are limited.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper—each item is phrased to be directly actionable for future work.
- Threshold selection for the KL budget d: the paper sets d=0.35 via preliminary KL-only experiments without a principled calibration. Develop a data-driven or adaptive schedule for d (e.g., validation-based calibration, risk-constrained tuning, or automated trust-region selection) and study sensitivity across tasks and training stages.
- Penalty magnitude n and boundary tolerance ε: the guarantees rely on n→∞ and an ε boundary treatment, but practical training uses finite n and unspecified ε. Report exact values, conduct ablations on n and ε, and quantify their effects on feasibility, stability, and final performance.
- Penalty shaping term φ design: only KL appears to be used; no ablation across f-divergences (e.g., JS, χ², reverse/forward KL). Systematically compare φ choices and prove (or refute) that adding φ preserves optimal-value equivalence and feasibility guarantees beyond the n→∞ limit.
- Metric mismatch between theory and evaluation: the theoretical constraint uses a cumulative (discounted) per-state divergence sum, while experiments measure “constraint satisfaction” as a per-sample KL below d. Align the metric with the theory (e.g., sequence-level cumulative KL) or justify the discrepancy with empirical/analytical evidence.
- Precise KL computation protocol is under-specified: clarify whether KL is per-token, averaged across tokens, weighted by position, or computed over entire sequence distributions; evaluate how each choice affects constraint satisfaction and learning dynamics.
- Discount factor γ and horizon handling: γ is not reported and interactions with variable-length sequences are unclear. Specify γ, analyze sensitivity, and study how horizon length and discounting influence constraint enforcement and reward maximization.
- Assumption A2 (existence of a feasible optimal policy): the paper assumes feasibility but does not test when the constraint is too tight (no feasible policy). Provide diagnostics for infeasibility, strategies to relax constraints, and empirical checks across datasets and d values.
- History-observability assumption and context truncation: removing state augmentation hinges on reconstructing the budget from full histories. Analyze failure modes when context windows truncate earlier tokens, and quantify how truncation affects z reconstruction and feasibility in long sequences.
- Deployment-time feasibility without teacher access: although teacher is not required at test time, there is no proxy to detect or control KL violations during deployment. Investigate proxies (e.g., entropy, self-consistency, calibration) and methods to monitor/maintain the trust region post-distillation.
- Training-time compute and cost claims: the method still requires teacher logits at every step; efficiency is claimed relative to dual Lagrangian methods, but compute/memory/throughput comparisons are not reported. Provide wall-clock, FLOPs, GPU hours, and memory vs. strong constrained-RL baselines (e.g., CPO, Lagrangian PPO).
- Limited task coverage: experiments focus on mathematical reasoning; generality to other domains (code generation, tool use, summarization, dialogue, safety/alignment) is untested. Extend to diverse tasks and analyze whether constraint satisfaction and reasoning gains transfer.
- Model scaling: only 1.5–3B students and 7–11B teachers are studied. Evaluate scalability to larger/smaller models, longer contexts, and multi-turn interactions; profile performance, stability, and cost at scale.
- Robustness and OOD generalization: constraint satisfaction and reasoning quality are not evaluated under distribution shift. Test on out-of-domain prompts and adversarial cases to assess trust-region robustness and reasoning preservation.
- Reasoning evaluation via LLM-as-a-Judge: reliance on a single judge (DeepSeek-R1-Distill-Qwen-32B) without human validation or calibration raises bias concerns. Add human evaluation, multiple judges, style normalization, and statistical testing (CIs, significance) across multiple seeds.
- Variance and reproducibility: results lack confidence intervals, seed variance, and detailed training curves. Report multiple seeds, learning curves, statistical significance, and release code/configs for replication.
- λ-baseline fairness: the Lagrangian relaxation baseline (GKD-GRPO) is grid-searched over λ, but d and n are not similarly tuned. Provide parallel sweeps of d and n for fairness and a more complete Pareto comparison.
- Interaction with process-level supervision: the method uses final-answer rewards; integration with step-level/process rewards (e.g., correctness of intermediate steps) is unexplored. Study combined objectives and their effects on reasoning fidelity and constraint adherence.
- Off-policy vs. on-policy training: GRPO uses on-policy trajectories; potential benefits of off-policy teacher trajectories or mixed sampling for reducing teacher compute are not examined. Evaluate off-policy variants and cached-logit strategies.
- Multi-teacher distillation: extension to multiple teachers (ensembles) and how to aggregate constraints (e.g., via max, average, or weighted f-divergences) is not addressed. Propose and test multi-teacher constrained formulations.
- Temperature and decoding consistency: teacher/student temperature settings and sampling strategies can affect KL and reasoning style; these choices are not detailed or ablated. Standardize and analyze their impact on constraint satisfaction and FAC/RWR.
- Boundary-case theory for explicit-dependence gradient: the derivation uses a limiting sub-gradient near the feasibility boundary, but convergence and variance properties are not empirically validated. Measure gradient variance, add baselines/critics, and test convergence under different φ and ε.
- Quantifying exploration benefits: the paper claims penalty shaping improves exploration among violating trajectories, but offers no exploration metrics. Instrument and report exploration measures (e.g., token-level diversity, state coverage, trajectory novelty).
- Practical feasibility checks: propose lightweight deployment-time checks of closeness to teacher (e.g., rank correlation with teacher logits on a small probe set) and study whether such probes predict reasoning degradation or constraint violations.
- Safety and alignment implications: treating KL as a hard constraint may transfer undesirable biases or unsafe behaviors from the teacher. Evaluate safety benchmarks, toxicity, and bias to understand alignment trade-offs under constrained distillation.
Glossary
- Almost surely: A probability term meaning an event occurs with probability 1. "then is also an optimal policy for the original constrained MDP and satisfies the constraint almost surely."
- Bellman equation: A fundamental recursive relation defining optimal value functions in dynamic programming/RL. "a) the Bellman equation is satisfied in $\widehat{\mathcal{M}_d$;"
- Constrained Markov Decision Process (CMDP): An MDP with constraints on cumulative costs (e.g., divergence) in addition to maximizing reward. "we can constrain the divergence between the teacher and student policy, following the constrained MDP formulation "
- Constrained reinforcement learning (CRL): RL that optimizes a reward while satisfying explicit constraints (e.g., safety, fidelity). "Constrained reinforcement learning (CRL) addresses the problem of optimizing a primary objective while satisfying constraint requirements (e.g., safety)"
- Dual Lagrangian optimization: A method that transforms constrained problems into saddle-point max–min forms using Lagrange multipliers. "Solving our new constrained RL problem follows standard methods for constraint optimization in which we write a dual Lagrangian optimization problem"
- f-divergence: A family of divergences measuring differences between probability distributions, generalizing KL and JS. "We define as any -divergence, including and JensenâShannon divergence, between the student and teacher at "
- Jensen–Shannon divergence: A symmetric, smoothed divergence between distributions, related to KL. "including and JensenâShannon divergence"
- Kullback–Leibler (KL) divergence: A measure of how one probability distribution diverges from a reference distribution. "often using metrics such as Kullback-Leibler (KL) divergence."
- Lagrangian relaxation: Turning hard constraints into penalties weighted by multipliers to obtain an unconstrained problem. "This corresponds to the standard Lagrangian relaxation of our constrained problem in Eq.~(\ref{eq:lag}), with as the balancing hyperparameter"
- Markov Decision Process (MDP): A formal model for sequential decision making with states, actions, transitions, and rewards. "It relaxes the constrained optimization problem by formulating a new state-augmented Markov Decision Process (MDP) with a reformulated reward function."
- On-policy: A learning paradigm where data is collected using the current policy being optimized. "On-policy reverse KL divergence minimization~\citep{minillm}, accounting for the long-term effects of actions on KL"
- Pareto front: The set of nondominated solutions balancing multiple objectives where improving one worsens another. "to demonstrate that our method identifies a notable point on the Pareto front balancing divergence minimization, reward maximization, and reasoning quality."
- Policy gradient theorem: A result giving the gradient of expected return with respect to policy parameters via likelihood ratios. "We compute following the policy gradient theorem~\cite{sutton1999policy} under the following minimal assumptions:"
- REINFORCE: A Monte Carlo policy gradient algorithm using the likelihood-ratio estimator. "We use GRPO rather than the REINFORCE-style update of \citet{agarwal2024policy} for consistency."
- Reverse KL divergence: KL computed as D_KL(student || teacher), often used to align student distributions to a teacher. "whose objective is to minimize the reverse KL divergence $D_{\mathrm{KL}(\pi_\theta \,\|\, \mu)$"
- State augmentation: Extending the state with auxiliary variables (e.g., remaining budget) to enforce constraints. "without requiring state augmentation or teacher model access during deployment"
- Saute: A state-augmentation method for enforcing constraints via an auxiliary budget-tracking variable. "Instead, we adopt a state augmentation method known as Saute \citep{sootla2022saute,sootla2022enhancing,ji2025almost}."
- Transition kernel: The function defining probabilities of moving from one state to another given an action. " is the transition kernel,"
- Trust-region constraint: A bound on policy divergence to ensure stable updates and fidelity to a reference. "A more robust alternative is to treat the KL divergence as an explicit trust-region constraint and solve the resulting constrained-RL problem"
- Upper semicontinuous: A topological property of functions where the function value at a point is at least the limit superior nearby. "The reward function is bounded, measurable, and upper semicontinuous on ;"
- Weakly continuous: A form of continuity for stochastic kernels where integrals against continuous bounded functions vary continuously. "The transition kernel is weakly continuous on ;"
Practical Applications
Overview
The paper presents a constrained reinforcement learning framework for LLM distillation that maximizes task-specific rewards while enforcing a trust region constraint (e.g., KL divergence to a teacher) without requiring state augmentation or dual Lagrange optimization. It demonstrates improved reasoning quality and constraint satisfaction compared to baselines, with practical efficiency for resource-constrained deployment. Below are actionable applications derived from these findings, organized by immediacy and linked to relevant sectors, tools, and workflows. Each application notes assumptions or dependencies that affect feasibility.
Immediate Applications
These applications can be deployed now using the described method with current open-source models and standard RL fine-tuning stacks.
- Enterprise “trust-region” distillation pipelines for domain-specific assistants
- Sector: software; applicable to finance, legal, customer support
- What: Build smaller, on-prem or edge-deployable assistants distilled from a stronger in-house or open model, enforcing a KL budget to preserve teacher fidelity while optimizing task rewards (e.g., compliance answers, report drafting).
- Tools/Workflow: GRPO-based training; define a KL threshold d; combine external task rewards (accuracy, format adherence) with the constrained reward; monitor constraint satisfaction and reasoning win rates; deploy student without teacher access.
- Assumptions/Dependencies: Access to teacher during training; well-defined reward functions; vetted teacher quality; student capacity sufficient for task.
- On-device math and structured reasoning tutors
- Sector: education; consumer devices
- What: Distill compact math/logic tutors (e.g., Qwen/Llama students) that retain teacher reasoning quality while running on mobile or low-power hardware.
- Tools/Workflow: Use datasets like GSM8K/MATH; apply constrained RL distillation; include LLM-as-a-judge in evaluation; ship lightweight inference packages.
- Assumptions/Dependencies: Reward fidelity (FAC and process-level scoring); generalization beyond benchmark tasks; privacy-compliant data.
- Model governance and safety guardrails via divergence budgets
- Sector: MLOps/model governance
- What: Introduce explicit KL budget thresholds as deployment criteria: reject checkpoints or routes that violate teacher-proximity constraints; track “constraint satisfaction rate” as an operational safety metric.
- Tools/Workflow: Training dashboards for KL budget tracking; acceptance tests for constraint satisfaction; alerts for degradation in reasoning quality despite high FAC.
- Assumptions/Dependencies: A reliable teacher reference; calibrated divergence metrics versus task shifts; legacy compliance policies mapping to trust-region bounds.
- Controlled fine-tuning for compliance and style preservation
- Sector: marketing, legal, enterprise communications
- What: Distill students that preserve tone, style, and safe behaviors of an approved teacher under a KL constraint while optimizing task reward (e.g., formatting, policy adherence).
- Tools/Workflow: Style/classification rewards; constrained distillation with tuned penalty n and phi (e.g., KL); evaluation of hallucination and formatting stability.
- Assumptions/Dependencies: Quality of stylistic teacher; domain reward design; monitoring for bias preservation.
- Faster, more stable distillation without dual optimization overhead
- Sector: research/engineering
- What: Replace Lagrangian-based reward+KL balancing with the proposed unaugmented constrained method to reduce variance and compute while achieving interpretable trust-region control.
- Tools/Workflow: GRPO implementation with explicit penalty term phi; standard policy gradient; Pareto analysis (FAC vs constraint satisfaction).
- Assumptions/Dependencies: Differentiable phi-divergence; training stability at chosen d; task-relevant reward signals.
- Reasoning-focused evaluation harness
- Sector: QA systems, educational products
- What: Integrate pairwise LLM-as-a-judge (process supervision) into CI pipelines to score reasoning quality and detect shallow strategies that “game” final answers.
- Tools/Workflow: Pairwise RWR/RLR evaluation workflows; guardrails to prefer checkpoints with higher reasoning quality under a fixed KL budget.
- Assumptions/Dependencies: Reliability of the judge; domain-specific rubric; risk of judge biases.
- Edge/IoT task assistants with teacher-free inference
- Sector: IoT, energy, retail devices
- What: Distill task-specific assistants (inventory explanations, device troubleshooting) that run locally and respect a trust region around a vetted teacher, eliminating teacher calls at inference.
- Tools/Workflow: Specify domain reward (task success, brevity, factuality); enforce KL budget in training; deploy compact students on devices.
- Assumptions/Dependencies: On-device memory and latency limits; teacher must encode safe policies; reward shaping for non-textual contexts.
Long-Term Applications
These applications require further research, scaling, domain adaptation, or standardization before broad deployment.
- Safety-critical assistants with multi-constraint distillation (beyond KL)
- Sector: healthcare, legal, autonomous systems
- What: Extend the framework to include multiple constraints (e.g., factuality, toxicity, hallucination rates, action-level safety) alongside KL, producing verifiably safe students for clinical/operational use.
- Tools/Workflow: Multi-constraint reward design; formal safety instrumentation; human-in-the-loop audits; process supervision on intermediate reasoning.
- Assumptions/Dependencies: Validated domain rewards; regulatory approval; rigorous out-of-distribution robustness.
- Regulatory frameworks codifying divergence budgets and feasibility guarantees
- Sector: policy/governance
- What: Use the KL budget and constraint satisfaction rates as auditable metrics in AI compliance standards (e.g., students must operate within a trust region of certified teachers).
- Tools/Workflow: Certification protocols; standardized divergence measures; reporting templates for audits.
- Assumptions/Dependencies: Agreement on metrics and thresholds; sector-specific norms; auditing infrastructure.
- Multi-teacher constrained distillation for composite capabilities
- Sector: enterprise AI, education
- What: Distill from multiple teachers (e.g., math, coding, safety) under per-teacher divergence budgets to produce composite students with balanced capabilities.
- Tools/Workflow: Mixture-of-teachers training; per-context KL budgets; curriculum scheduling of constraints.
- Assumptions/Dependencies: Teacher diversity and quality; conflict resolution across teachers; scalable training.
- Adaptive trust-region control and competence-aware constraints
- Sector: research/advanced engineering
- What: Dynamically adjust the KL budget d based on student competence or task difficulty, balancing innovation and fidelity over time.
- Tools/Workflow: Competence estimators; adaptive controllers; meta-RL for constraint scheduling.
- Assumptions/Dependencies: Reliable competence signals; stability under dynamic constraints; careful monitoring for drift.
- Constrained distillation for tool-using agents and robotics planners
- Sector: robotics/automation
- What: Apply the method to high-level planning and tool use, adding action-space constraints (e.g., safety, cost, energy) alongside KL to preserve safe and interpretable reasoning.
- Tools/Workflow: Hybrid symbolic–LLM reward functions; simulation-to-real pipelines; safety certification.
- Assumptions/Dependencies: Robust task rewards for planning; integration with controllers; extensive validation.
- Federated/private distillation at scale
- Sector: privacy-preserving AI, healthcare, finance
- What: Distributed constrained distillation where local nodes learn students that remain within trust regions of a central teacher without sharing raw data.
- Tools/Workflow: Federated orchestration; privacy-preserving divergence estimates; secure aggregation.
- Assumptions/Dependencies: Legal/privacy constraints; accuracy of distributed KL measurement; communication overhead.
- Standardized reasoning audits and benchmarks
- Sector: academia/industry consortia
- What: Establish public reasoning benchmarks and “reasoning audit” protocols that evaluate process quality alongside final accuracy under trust-region constraints.
- Tools/Workflow: Shared datasets; judge calibration; inter-rater reliability studies; challenge sets for chain-of-thought robustness.
- Assumptions/Dependencies: Consensus on rubrics; judge reliability; community adoption.
Cross-cutting Assumptions and Dependencies
- Access to a high-quality teacher model during training and permission to compute divergences.
- Well-defined, task-relevant reward functions that correlate with desired reasoning quality; risk of reward hacking.
- Student capacity must be sufficient to meet constraint satisfaction while achieving target rewards; otherwise, d must be relaxed or tasks simplified.
- The phi divergence (e.g., KL) must be differentiable and numerically stable; careful handling of probability floors.
- Guarantees depend on large penalties (n) and feasibility assumptions; practical implementations approximate n→∞ with finite values.
- Reasoning quality measurements via LLM-as-a-judge introduce potential biases; human verification may be required in safety-critical settings.
- Distillation preserves teacher biases and failure modes inside the trust region; governance should include bias and fairness audits.
- Domain transfer beyond mathematical reasoning requires tailored reward design and evaluation.
Collections
Sign up for free to add this paper to one or more collections.