- The paper introduces AudioMoG, a framework that integrates classifier-free guidance (CFG) and autoguidance (AG) to improve fidelity and diversity in audio synthesis.
- It employs hierarchical and parallel guidance methods to progressively refine audio quality and achieve superior spectral clarity, as shown by improved FAD scores.
- Experimental results demonstrate significant advancements in text-to-audio and video-to-audio tasks, reducing FAD from 1.76 to 1.38 without added computational cost.
AudioMoG: Guiding Audio Generation with Mixture-of-Guidance
Introduction
The paper introduces AudioMoG, a framework designed to improve cross-modal audio generation by leveraging a mixture-of-guidance approach. The objective is to overcome the limitations of existing guidance methods in audio generation, specifically addressing the fidelity-diversity trade-offs observed in classifier-free guidance (CFG) and autoguidance (AG). CFG enhances fidelity by emphasizing condition alignment but often sacrifices diversity, while AG improves diversity by encouraging sampling to reconstruct the target distribution faithfully. AudioMoG aims to exploit the complementary advantages of these distinct guiding principles to enhance the synthesis quality of audio generation systems, particularly for text-to-audio (T2A) and video-to-audio (V2A) tasks.
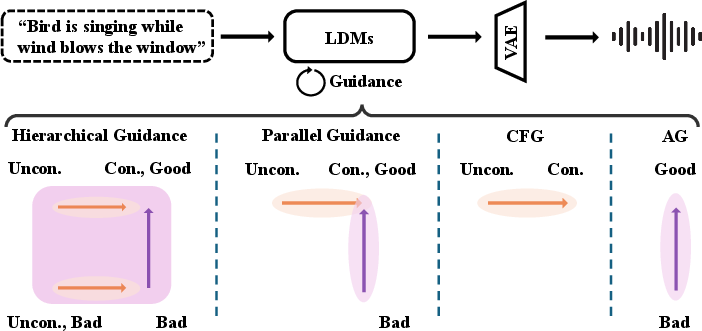
Figure 1: Overall framework of our proposed AudioMoG, which illustrates the mechanism of AudioMoG and its degraded forms—Hierarchical Guidance exploits cumulative advantages from both methods for optimal performance, Parallel Guidance introduces complementary directions, and CFG or AG provides a single-directional guidance.
Methodology
AudioMoG introduces a mixture-of-guidance framework that considers multiple guidance methods simultaneously, rather than relying on a single guiding principle. It proposes hierarchical guidance (HG) and parallel guidance (PG) as strategies to integrate different methods. HG leverages the cumulative benefits of CFG and AG, allowing for progressive refinement of generation results. This method improves upon single guidance systems by enhancing both conditional and unconditional score estimation results before applying condition alignment, thereby achieving more accurate audio generation without sacrificing sample diversity.
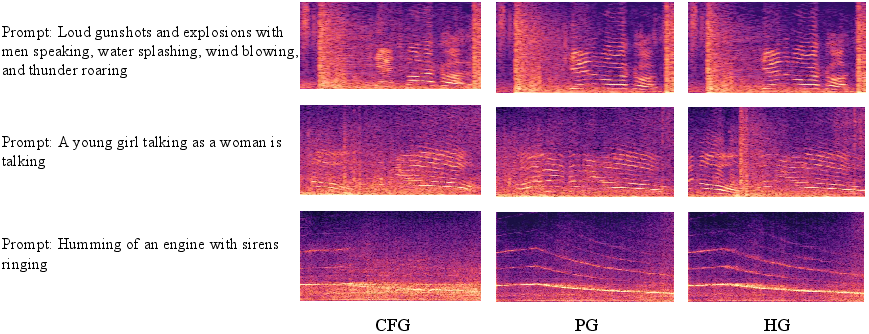
Figure 2: Case study comparing the spectrogram outputs of different guidance strategies (CFG, PG, HG) under various text prompts. HG consistently demonstrates superior harmonic structure modeling and clearer spectral patterns compared to PG and CFG. While PG shows moderate improvements, CFG often struggles to capture harmonics and yields blurrier, less structured results, particularly for complex prompts. These examples visually highlight the effectiveness of hierarchical guidance in improving fidelity and temporal structure.
Experimental Results
The experiments conducted demonstrate AudioMoG's superiority over traditional CFG and AG methods across various metrics such as Fréchet Audio Distance (FAD), Inception Score (IS), and Kullback-Leibler (KL) divergence. HG consistently outperformed both CFG and AG in generating higher-quality audio samples under the same inference speed conditions. Notably, HG improved FAD scores from 1.76 to 1.38 in T2A and similar enhancements in V2A and text-to-music generation tasks, indicating significant advancements in both fidelity and alignment accuracy.
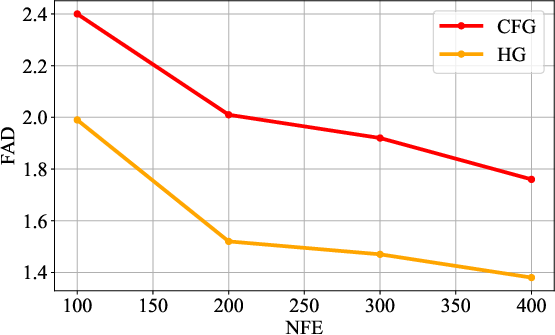
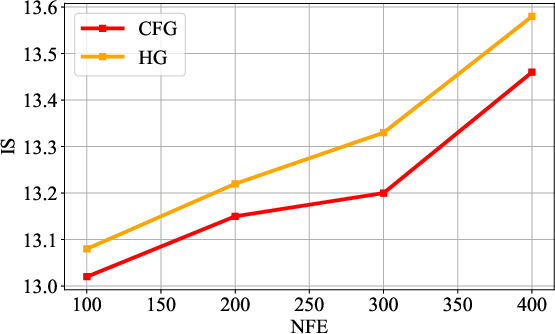
Figure 3: FAD (downarrow) under different NFEs.
Implications
The introduction of AudioMoG has significant implications for the field of audio generation, offering a path to improving synthesis quality without increasing computational costs. Its ability to utilize diverse guiding strategies simultaneously allows for enhanced audio fidelity and diversity, crucial for applications in multimedia content creation, virtual reality, and human-computer interaction. The research opens new avenues for optimizing guidance scales and further refining the framework, potentially applying it to more complex multimodal generation tasks.
Conclusion
AudioMoG presents a novel approach to guiding audio generation by synthesizing multiple guidance principles. Through its hierarchical and parallel strategies, it successfully addresses the fidelity-diversity trade-offs inherent in existing methods, setting a new standard for quality in cross-modal audio synthesis. Future research should explore tuning the guidance scales for various applications and extending the methodology to other domains such as conditional image generation, further broadening the impact of this innovative framework.