- The paper introduces TR2-D2, which integrates Monte Carlo Tree Search with off-policy reinforcement learning to optimize trajectories for discrete diffusion models.
- It leverages a weighted denoising cross-entropy loss to fine-tune models for both single and multi-objective tasks, ensuring convergence to reward-tilted and Pareto-optimal distributions.
- Empirical results in DNA and peptide design demonstrate state-of-the-art performance with high predicted activities and improved binding affinities.
Tree Search Guided Trajectory-Aware Fine-Tuning for Discrete Diffusion: TR2-D2
Introduction and Motivation
The TR2-D2 framework introduces a principled approach for reward-guided fine-tuning of discrete diffusion models, specifically targeting the challenges of trajectory optimization in high-dimensional, discrete state spaces. Standard reinforcement learning (RL) approaches for diffusion fine-tuning are limited by the quality of trajectories sampled from the current policy, often reinforcing suboptimal solutions due to the rarity of high-reward samples in low-density regions. TR2-D2 addresses this by integrating Monte Carlo Tree Search (MCTS) to systematically explore and exploit the search space, constructing a replay buffer of optimized trajectories for off-policy RL. This decoupling of search and learning enables efficient trajectory-aware fine-tuning, with theoretical guarantees for both single and multi-objective reward optimization.
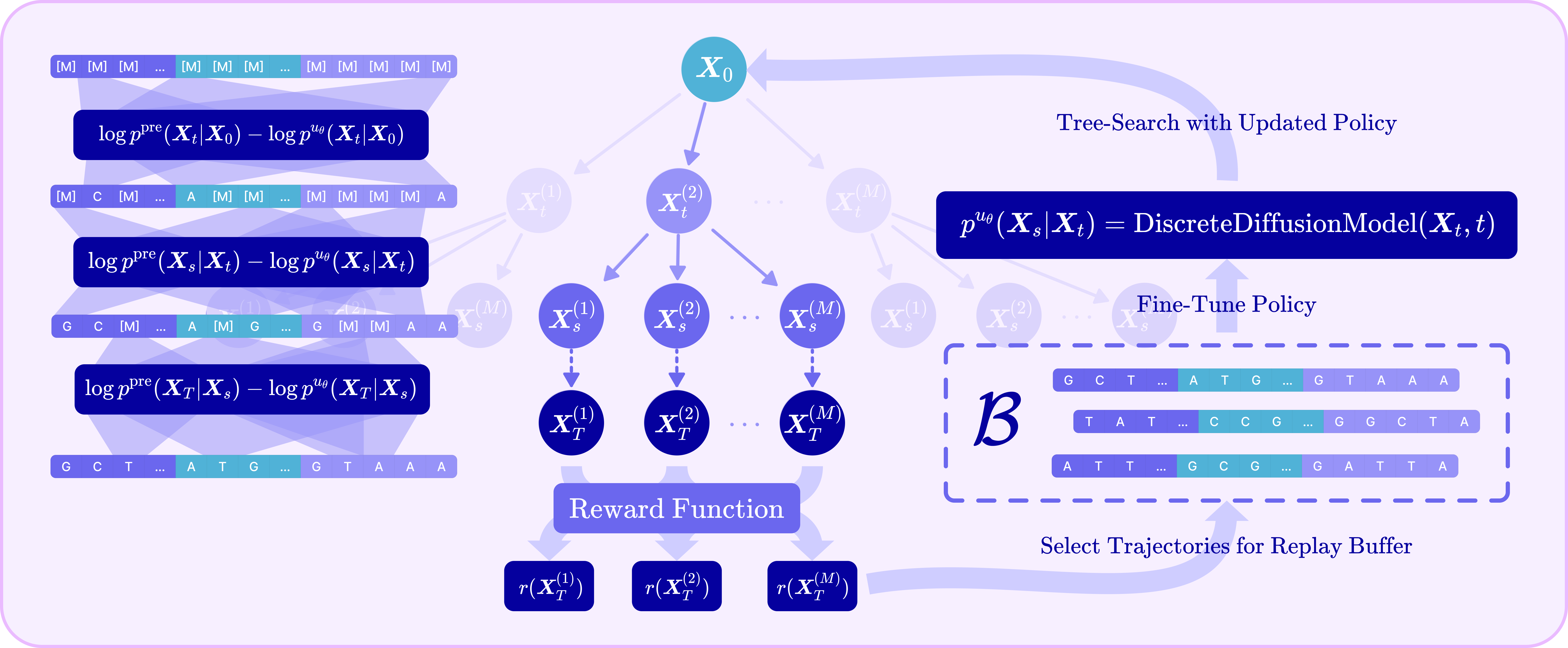
Figure 1: TR2-D2 framework: MCTS generates a replay buffer of reward-optimized diffusion trajectories, which are then used for off-policy RL fine-tuning of the discrete diffusion model.
Discrete Diffusion and RL Fine-Tuning
Discrete diffusion models, such as Masked Discrete Diffusion Models (MDM), operate over a finite state space XL and are parameterized to learn the generator of a continuous-time Markov chain (CTMC). The forward process injects noise by masking tokens, while the reverse process iteratively unmasks tokens conditioned on the current sequence. Fine-tuning these models for reward-tilted distributions ptarget(X)∝pdata(X)exp(r(X)/α) is formulated as an entropy-regularized stochastic optimal control (SOC) problem, where the objective is to maximize expected reward while minimizing KL divergence from the pre-trained model.
The off-policy RL approach leverages the weighted denoising cross-entropy (WDCE) loss, which uses importance sampling over trajectories generated by a reference policy. The Radon-Nikodym derivative between the optimal and reference path measures provides the importance weights, enabling unbiased estimation of the reward-tilted objective even in the absence of i.i.d. samples from ptarget.
Structured Search with Monte Carlo Tree Search
TR2-D2 employs MCTS to generate high-reward trajectories for buffer population. Each node in the search tree represents a partially unmasked sequence, with child nodes corresponding to possible unmasking actions. The selection strategy balances exploitation of high-reward paths and exploration of diverse trajectories, using a selection score that incorporates both reward and visitation statistics. Expansion is performed by sampling child sequences from the current policy, perturbed with Gumbel noise for diversity. Rollouts complete the unmasking process, accumulating log-probabilities and rewards, while backpropagation updates the reward statistics along the path.
This search-driven buffer generation is decoupled from the RL fine-tuning step, allowing the use of arbitrary search and off-policy RL algorithms. The buffer is periodically regenerated, and the policy is updated over multiple epochs using the WDCE loss, amortizing the computational cost of search and reinforcing the ability to generate high-reward sequences.
Multi-Objective Fine-Tuning and Pareto Optimization
TR2-D2 extends naturally to multi-objective optimization, where the reward function is vector-valued and the goal is to approach the Pareto frontier of non-dominated solutions. During MCTS, selection and buffer updates are performed using Pareto dominance criteria, ensuring that the buffer contains only non-dominated trajectories. Theoretical analysis guarantees that the hypervolume of the buffer's reward vectors is non-decreasing and converges to the Pareto frontier under sufficient exploration.
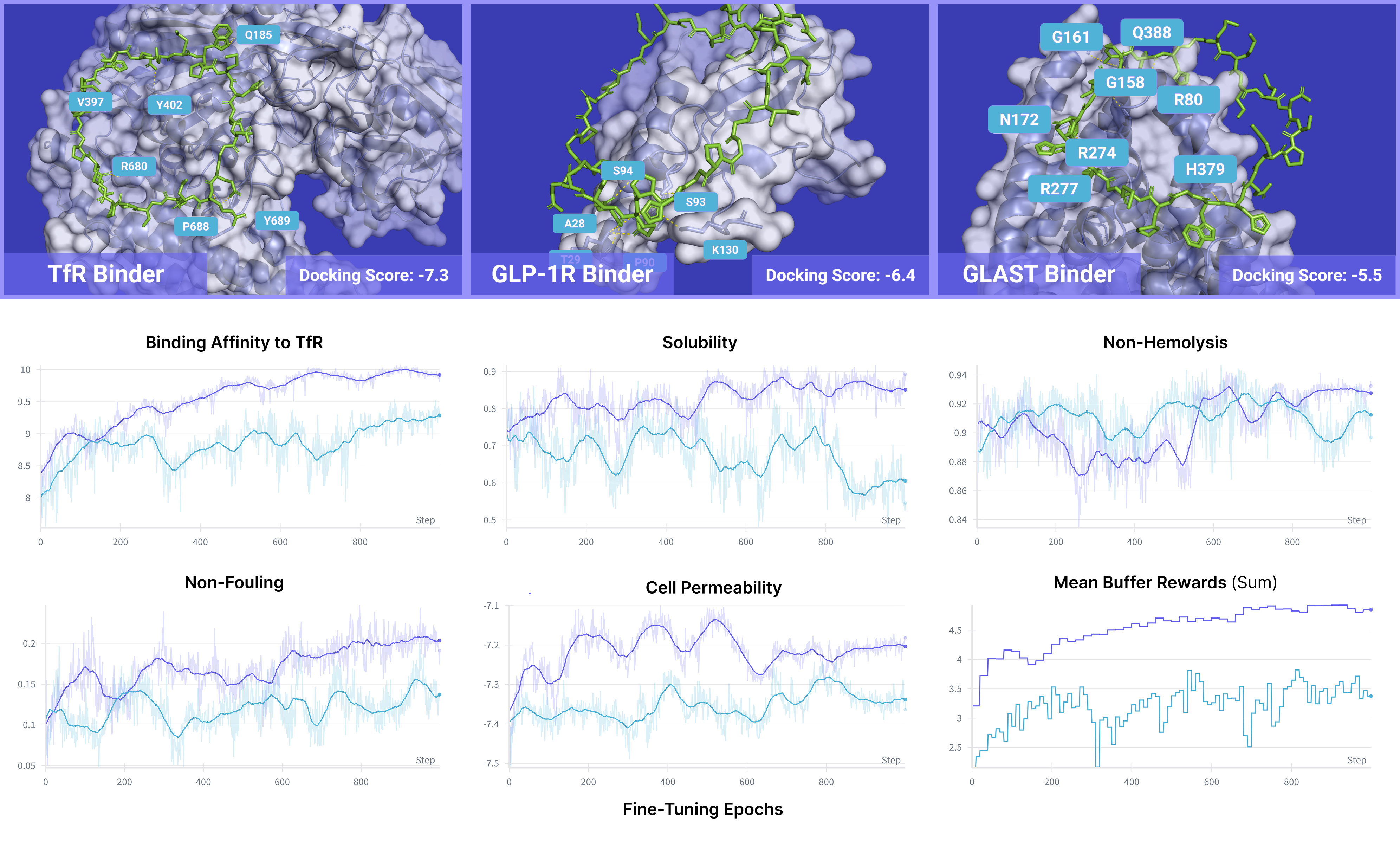
Figure 2: Multi-objective peptide docking and reward optimization: TR2-D2 with MCTS achieves superior docking scores and multi-reward values compared to non-search baselines.
Figure 3: Multi-objective reward curves for fine-tuning toward high binding affinity to diverse protein targets, demonstrating effective optimization across all objectives.
Empirical Results
Regulatory DNA Sequence Design
TR2-D2 achieves state-of-the-art performance in enhancer DNA design, outperforming both guidance and fine-tuning baselines on predicted activity and chromatin accessibility. With strong KL regularization (α=0.001), TR2-D2 attains a median predicted activity of $9.74$ and near-perfect ATAC-Acc (99.9%), exceeding previous methods. Increasing α improves 3-mer correlation, indicating better preservation of natural sequence statistics.
Multi-Objective Peptide Design
In multi-objective peptide generation, TR2-D2 surpasses inference-time guidance methods (PepTune) across binding affinity, solubility, non-hemolysis, non-fouling, and permeability for multiple protein targets. Notably, TR2-D2 achieves these results with a single diffusion pass, whereas PepTune requires extensive inference-time search. Ablation studies confirm the critical role of MCTS in buffer generation, with performance improving as the number of children and iterations increases.
Figure 4: Ablation on MCTS iterations: increasing Niter steadily improves buffer reward values during fine-tuning.
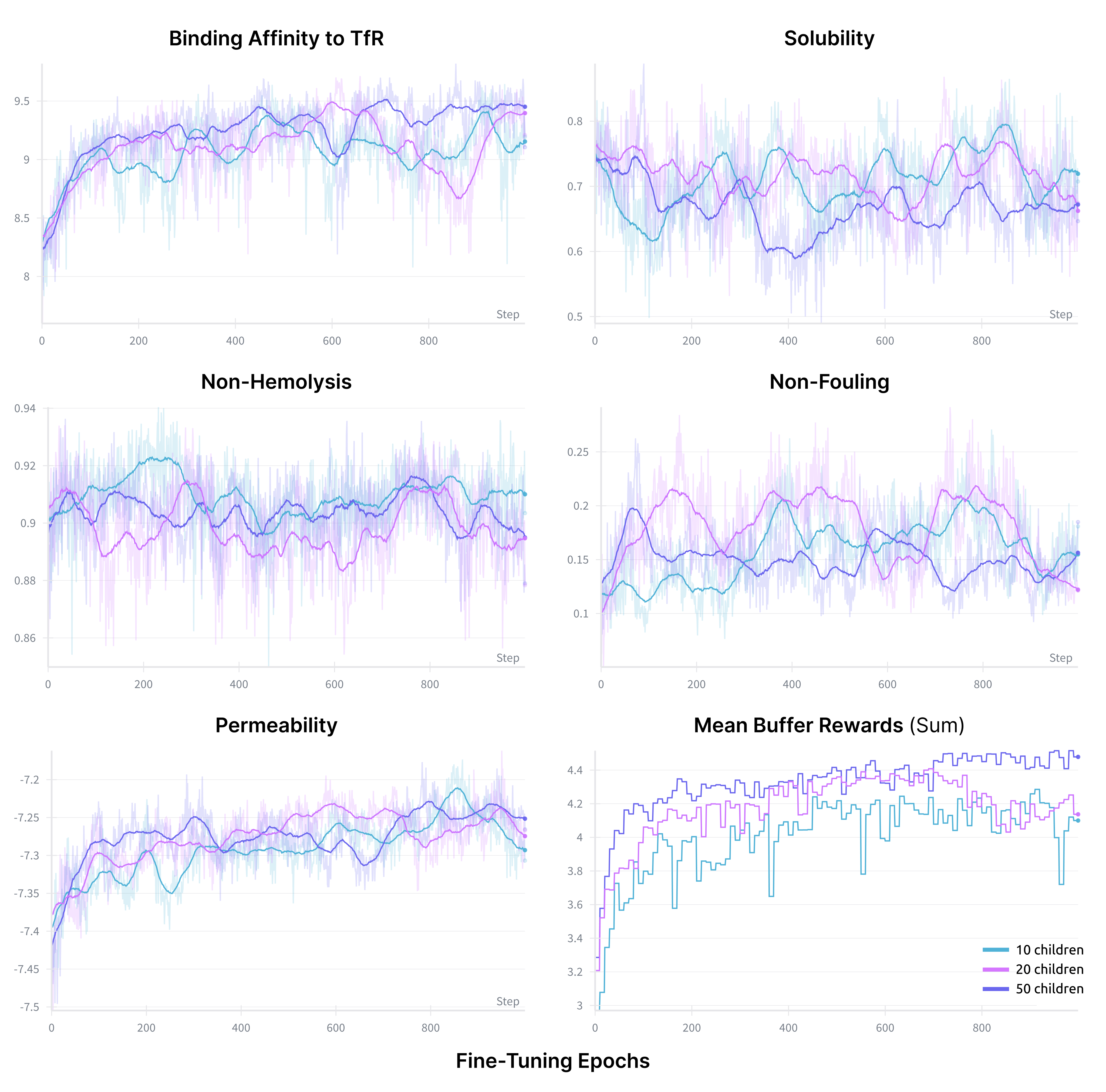
Figure 5: Ablation on number of children M: larger M yields higher mean buffer rewards, indicating more effective exploration.
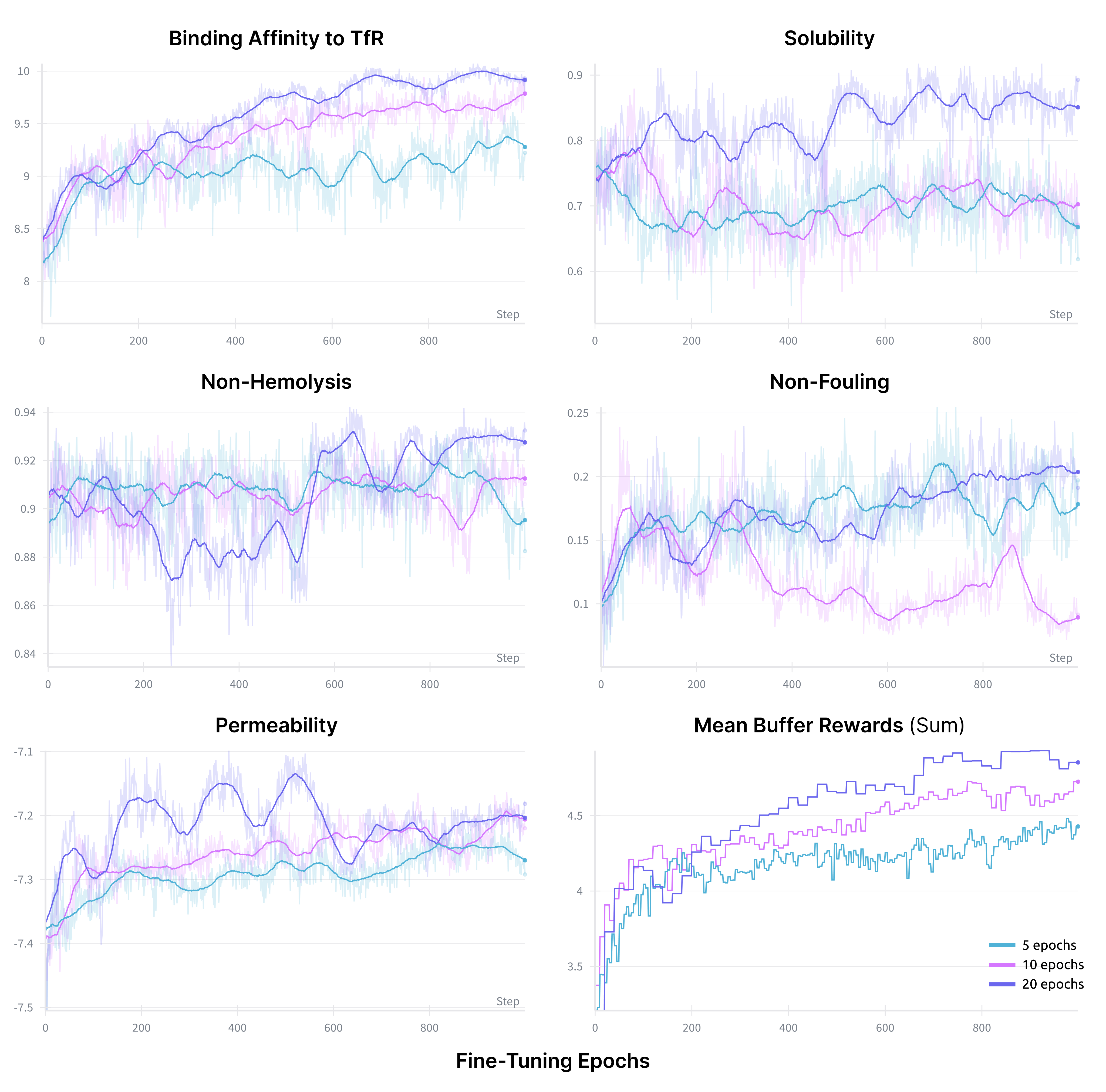
Figure 6: Ablation on buffer resampling frequency Nresample: more frequent resampling increases diversity, while less frequent resampling improves reward optimality.
Implementation Considerations
- Computational Requirements: MCTS incurs additional inference cost during buffer generation, but this is amortized by repeated training on the buffer. GPU acceleration is essential for large-scale sequence models.
- Hyperparameter Tuning: Key parameters include number of children M, MCTS iterations Niter, buffer size B, KL regularization α, and buffer resampling frequency Nresample. Trade-offs exist between reward optimality and sequence diversity.
- Scalability: The decoupled design allows scaling to larger models and more complex reward functions, including integration with experimental feedback in closed-loop pipelines.
- Limitations: The approach relies on the quality of reward oracles and may be sensitive to reward sparsity. Pareto frontier approximation is limited by buffer size and search budget.
Theoretical Implications and Future Directions
TR2-D2 provides a rigorous framework for discrete stochastic optimal control in generative modeling, with provable convergence to reward-tilted and Pareto-optimal distributions. The decoupling of search and learning opens avenues for integrating advanced combinatorial optimization and RL algorithms. Future work may explore variance reduction in trajectory weighting, adaptive search strategies, and applications to full-length protein and mRNA design with complex structural constraints.
Conclusion
TR2-D2 establishes a general and effective paradigm for trajectory-aware fine-tuning of discrete diffusion models via structured search and off-policy RL. Empirical results demonstrate superior performance in both single and multi-objective biological sequence design tasks. The framework is extensible to broader domains and offers a foundation for further theoretical and practical advances in reward-guided discrete generative modeling.