- The paper introduces AR3PO, which employs adaptive rollout and response reuse to significantly enhance sampling efficiency in reinforcement learning with verifiable rewards.
- It dynamically allocates computational resources based on prompt difficulty, reducing generation cost by approximately 4.2 times compared to previous methods.
- Experimental results show that AR3PO surpasses traditional approaches like GRPO and matches or exceeds DAPO performance on challenging mathematical reasoning tasks.
Improving Sampling Efficiency in RLVR through Adaptive Rollout and Response Reuse
Introduction
The emergence of LLMs has significantly advanced the field of artificial intelligence, particularly in reasoning domains such as mathematics, coding, and scientific analysis. Reinforcement Learning with Verifiable Rewards (RLVR) has become a pivotal framework for refining LLMs post-training. Traditional algorithms like Group Relative Policy Optimization (GRPO) have been extensively utilized; however, they suffer from limitations in their reward computation strategies, which can result in vanished advantages when responses within groups receive identical rewards.
The paper introduces Adaptive Rollout and Response Reuse Policy Optimization (AR3PO), a novel approach focusing on improving sampling efficiency and computational cost without compromising performance. AR3PO integrates two key innovations: adaptive rollout and response reuse, addressing efficiency and training signal acquisition issues.
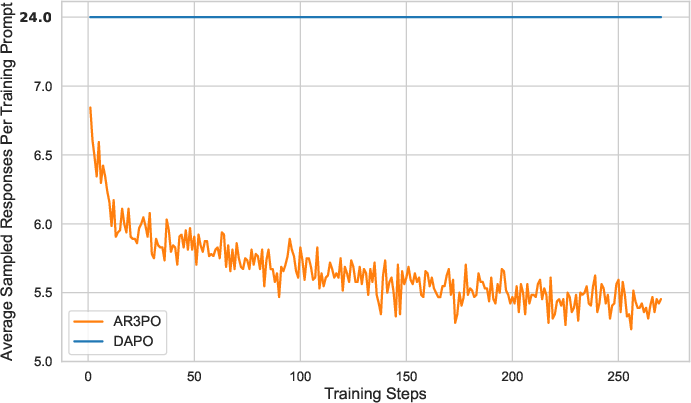
Figure 1: Comparison of the average number of sampled responses per training prompt between DAPO and our AR3PO algorithm. By leveraging our proposed adaptive rollout and response reuse techniques, AR3PO requires fewer responses as training progresses, with a final average of 5.7, reducing generation cost by approximately 4.2\times compared to DAPO.
Algorithm and Methodology
Preliminaries
The RLVR framework uses a verifier to provide rewards based on rule-based criteria. For example, in mathematical problem solving, a binary reward indicates whether a response is correct. GRPO computes advantages by normalizing rewards within response groups, but this approach falters when the grouped responses receive identical rewards, resulting in zero advantages.
DAPO addresses this by dynamically sampling until variance in rewards is achieved, raising computational costs substantially. AR3PO seeks a more efficient alternative, namely adaptive rollout and response reuse.
Adaptive Rollout
Adaptive rollout strategically allocates computational resources by dividing the response generation process into multiple stages. Prompts without correct responses proceed to successive stages, ensuring more responses are directed to challenging prompts, while easier prompts consume fewer resources.
Response Reuse
AR3PO incorporates response reuse by utilizing previously generated correct responses for prompts that fail to produce a correct response in the current step. This is achieved by maintaining a replay buffer of correct responses, addressing inefficiencies in on-policy sampling methodologies prevalent in GRPO and DAPO.
Experimental Results
AR3PO was evaluated against GRPO and DAPO on mathematical reasoning tasks with two base models: Qwen2.5-7B and Llama-3.1-8B-Instruct. Findings show AR3PO consistently surpasses GRPO and matches or exceeds DAPO while significantly reducing generation costs, exemplified by improved sampling efficiency up to 4.2 times.
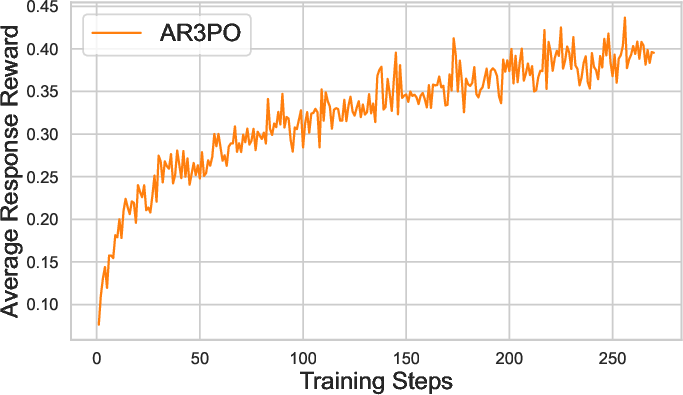
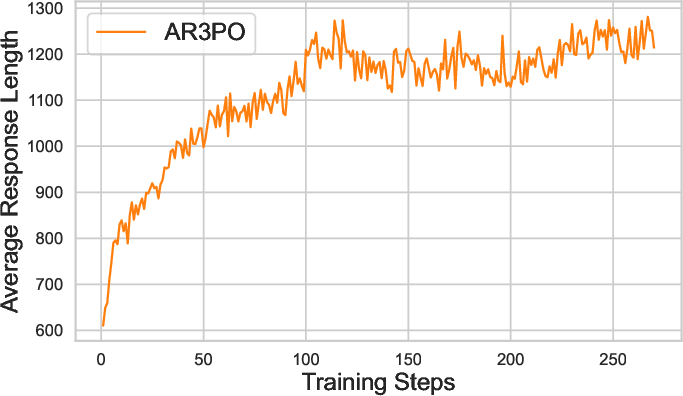
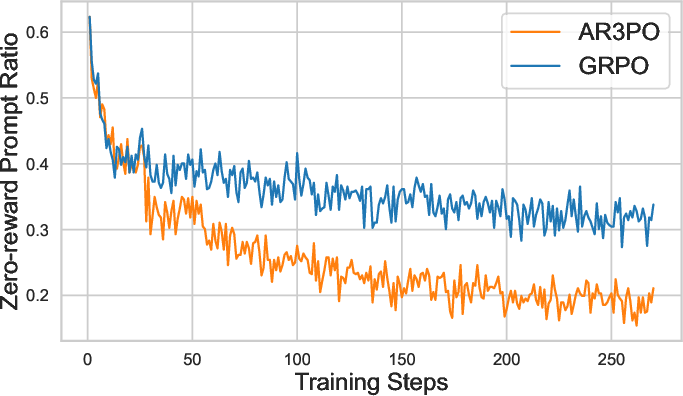
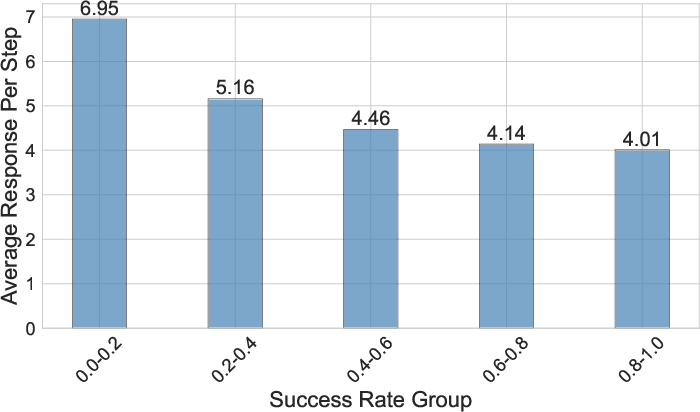
Figure 2: Reward score.
Analysis confirms that AR3PO's adaptive rollout effectively reallocates resources based on prompt difficulty, improving overall efficiency and model performance. Furthermore, the implementation of response reuse substantially enhances training signal retention from challenging prompts.
Implications and Future Work
AR3PO's reduced computational cost and enhanced efficiency suggest significant potential in practical applications, especially for scaling model sizes without proportional increases in computational resources. The innovative techniques can be further adapted and refined for broader LLM applications beyond RLVR frameworks.
Future directions could explore extending AR3PO's efficacy to LLM agent settings and optimizing trajectory sampling, potentially informing more sophisticated exploration strategies in reinforcement learning environments.
Conclusion
This paper presents a robust RLVR mechanism that successfully addresses computational inefficiencies seen in traditional post-training algorithms like GRPO and DAPO. By employing adaptive rollout and response reuse techniques, AR3PO enhances sampling efficiency and reduces necessary computational expenditures, paving the way for scalable, high-performance LLM applications in complex reasoning tasks.
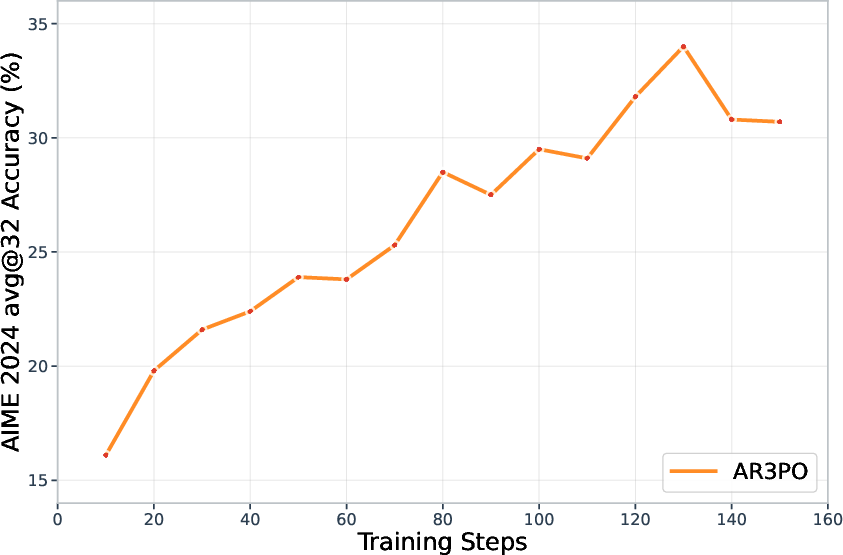
Figure 3: AIME 2024 accuracy of AR3PO with the Qwen2.5-32B base model. Our method achieves 34.0\% accuracy at step 130, comparable to the performance reported by DAPO around 130 training steps (see Figure~1 in~\citet{yu2025dapo}).
