Learning to Reason as Action Abstractions with Scalable Mid-Training RL
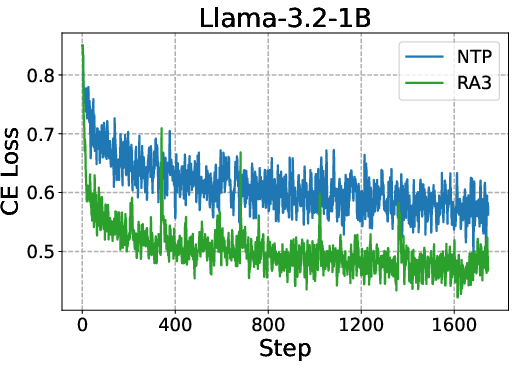
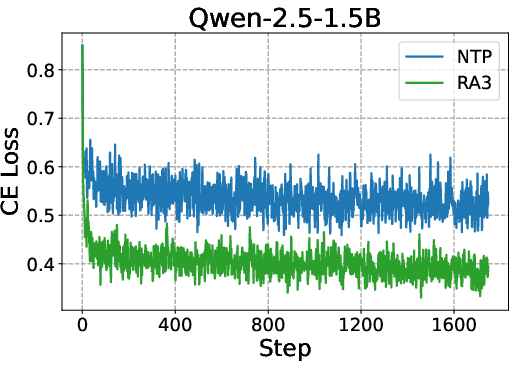
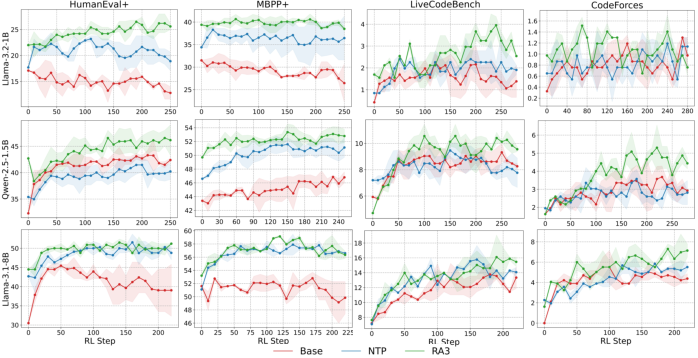
Abstract: LLMs excel with reinforcement learning (RL), but fully unlocking this potential requires a mid-training stage. An effective mid-training phase should identify a compact set of useful actions and enable fast selection among them through online RL. We formalize this intuition by presenting the first theoretical result on how mid-training shapes post-training: it characterizes an action subspace that minimizes both the value approximation error from pruning and the RL error during subsequent planning. Our analysis reveals two key determinants of mid-training effectiveness: pruning efficiency, which shapes the prior of the initial RL policy, and its impact on RL convergence, which governs the extent to which that policy can be improved via online interactions. These results suggest that mid-training is most effective when the decision space is compact and the effective horizon is short, highlighting the importance of operating in the space of action abstractions rather than primitive actions. Building on these insights, we propose Reasoning as Action Abstractions (RA3), a scalable mid-training algorithm. Specifically, we derive a sequential variational lower bound and optimize it by iteratively discovering temporally-consistent latent structures via RL, followed by fine-tuning on the bootstrapped data. Experiments on code generation tasks demonstrate the effectiveness of our approach. Across multiple base models, RA3 improves the average performance on HumanEval and MBPP by 8 and 4 points over the base model and the next-token prediction baseline. Furthermore, RA3 achieves faster convergence and higher asymptotic performance in RLVR on HumanEval+, MBPP+, LiveCodeBench, and Codeforces.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Learning to Reason as Action Abstractions with Scalable Mid-Training RL: In Simple Terms
Let's explore this academic paper using simple language and ideas that a 14-year-old can understand.
Overview of the Paper
The paper talks about a way to make smart computer programs, known as LLMs, even smarter. These models need to learn how to make good decisions by taking "actions." The research suggests that helping these models learn the right actions in the middle of their training makes them better at tasks after training.
Key Objectives
The researchers wanted to find out:
- How can we help LLMs make better decisions by teaching them during their mid-training?
- What type of training helps them learn quickly and effectively?
Research Methods
Imagine teaching a robot to solve puzzles by giving it many examples of good solutions. This study uses a similar approach. The researchers used something called "Reinforcement Learning" (RL), which is like giving the robots rewards when they make good decisions, and training it with examples. They focused on helping the model choose smart, high-level actions (like solving whole parts of a puzzle) rather than simple ones (like moving a single puzzle piece).
Main Findings
The study found:
- By teaching the models using examples of useful actions early on, the models become better at making decisions and understanding tasks later.
- When models use high-level actions (like solving complex problems in one step), they learn faster and work more efficiently.
Implications
These findings mean that smart devices, like AI assistants or coding tools, could become even more helpful. They could solve problems faster and more accurately because they've learned to think and plan better by being taught the right actions initially.
By putting these findings into practice, future tech could be smarter and more efficient, benefiting from better mid-training strategies that focus on teaching them intelligent decisions.
In summary, this paper builds an approach to make tech smarter by teaching them strategic actions, leading to improved performance in complex tasks.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, phrased as concrete, actionable items for future research.
- Formal assumptions and scope of the theoretical results are under-specified:
- Precisely state assumptions (e.g., bounded rewards, ergodicity, realizability, function class of policies) required for Theorem 1 (pruning efficiency) and Theorem 3 (RL convergence), and validate them in language-model settings.
- Clarify whether the regret decomposition holds under stochastic environments and partial observability typical of LLM agentic tasks.
- Practical measurability of the “minimal size of an ε‑optimal action subset” remains unaddressed:
- Develop methods to estimate or bound for real code and language domains, and empirically test how it correlates with sample complexity and performance.
- Missing connection between RA3 and the pruning efficiency bound:
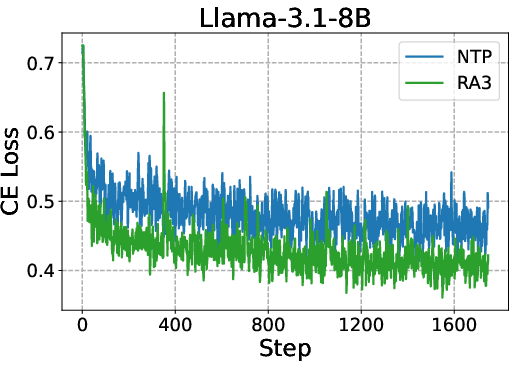
- Provide theoretical or empirical evidence that RA3 actually reduces pruning error (i.e., approximates a near-optimal action subset) relative to NTP, beyond observed CE loss and benchmark scores.
- Convergence analysis misalignment with the RLVR setting:
- Theorem 3 analyzes multi-step MDPs, yet RLVR is formulated as single-step outcome reward; quantify how temporal abstractions affect convergence and sample efficiency in single-step RLVR where the external horizon is 1 but the internal generation horizon is long.
- Limited latent space design:
- The implemented latent space is restricted to two tags (“act” as newline and “think” as comment). Investigate richer, multi-level action abstractions (e.g., options with initiation/termination sets, subroutine graphs, semantic blocks) and compare their impact on pruning and RL convergence.
- Option termination and initiation are not explicitly learned:
- Introduce and evaluate learned termination conditions and initiation sets for latent actions so that options can persist across variable-length spans in generation, rather than relying on a single “act” token to implicitly terminate “think”.
- Prior design for latents is heuristic and static:
- Explore adaptive or learned priors (instead of fixed delta-plus-uniform) and study how prior misspecification affects temporal consistency, interpretability, and training stability.
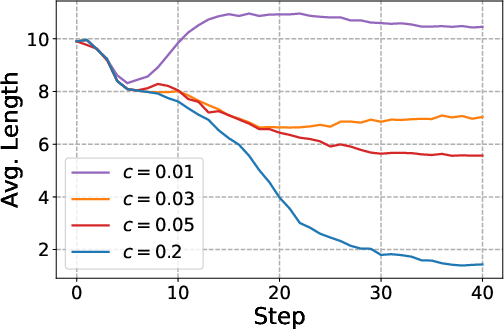
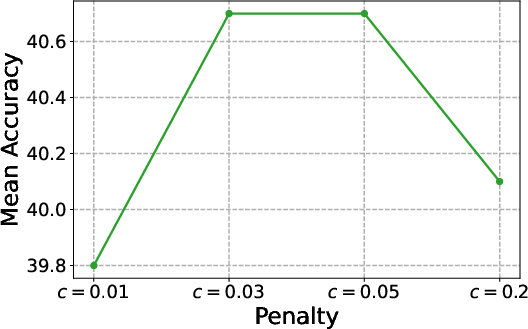
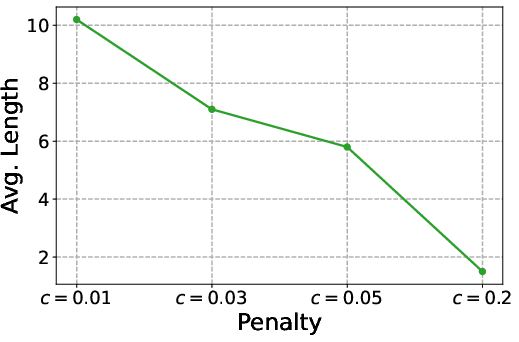
- Reward shaping and penalty selection lack principled calibration:
- Derive or learn the penalty (or ) adaptively based on return, likelihood gains, or information-theoretic criteria; evaluate sensitivity across tasks and model scales, and provide guidelines for robust tuning.
- Self-supervised RL with log-likelihood reward may learn spurious “explanations”:
- Assess whether latents actually capture causal, transferable skills versus post-hoc rationalizations; introduce diagnostics (e.g., counterfactual interventions, mutual information tests) to validate the utility of learned abstractions.
- Credit assignment design is truncated and unexamined:
- The RL step uses a 5-step truncated return; study the effect of longer/shorter horizons, alternative advantage estimators, and variance reduction techniques on learning quality and compute cost.
- Scalability claims need quantified compute and throughput analysis:
- Report precise training FLOPs, wall-clock time, memory usage, and inference-time overhead of rollouts versus NTP; analyze how temporal consistency reduces rollout frequency and quantify the net cost at corpus scales beyond 1B tokens.
- Generalization beyond Python code remains unexplored:
- Evaluate RA3 across domains (math, natural language reasoning, tool-using agents, multi-modal tasks), other programming languages, and varied formatting constraints to test the purported benefits of action abstractions.
- Impact on output format and compatibility constraints is not analyzed:
- Examine whether inserting comments (think) affects correctness or acceptance in strict environments (e.g., contest judges, production pipelines), and design mechanisms to suppress internal reasoning when required without losing gains.
- Data contamination and benchmark overlap are not ruled out:
- Conduct deduplication and leakage audits to ensure mid-training corpora do not overlap with HumanEval, MBPP, and RLVR training/evaluation sets; report contamination metrics.
- Limited baselines and ablations:
- Compare RA3 against additional mid-training baselines (e.g., CoT distillation, BRITE-like EM methods, supervised rationale augmentation, option discovery algorithms) and ablate key RA3 components (latent length cap, group size G, asynchronous vs batched rollouts, warmup without KL).
- Lack of statistical rigor in evaluation:
- Provide confidence intervals, hypothesis tests, and variance analyses across seeds and data splits; investigate stability and reproducibility across runs and hyperparameter sweeps.
- Missing analysis of diversity and entropy:
- Quantify how RA3 changes policy entropy and sampling diversity (pass@k dynamics), and whether improvements stem from better priors versus increased exploration variance.
- No measurement of effective horizon reduction:
- Empirically estimate the distribution of latent durations (number of steps a latent persists), and link measured to observed RLVR convergence improvements.
- Interpretability and faithfulness of learned latents:
- Evaluate whether learned “skills” (e.g., BFS, dummy head patterns) transfer across datasets and tasks, and whether latents can be inspected, edited, or constrained to guide generation reliably.
- Safety and misalignment considerations:
- Investigate whether optimizing latent rationales for likelihood introduces unwanted behaviors (e.g., unnecessary code verbosity, leakage of internal thoughts, prompt injection susceptibility), and design mitigations.
- Hyperparameter sensitivity and robustness:
- Systematically study sensitivity to , latent length limits, temperature, entropy coefficients, and batch sizes; propose robust defaults or adaptive schemes.
- Interaction with downstream RL algorithms:
- Test RA3’s impact on a broader set of post-training RL methods (e.g., PPO variants, DPO/IPO, multi-step RL with programmatic verifiers), and analyze whether certain algorithms benefit more from action abstractions.
- Theoretical extension to function approximation and large action spaces:
- Extend pruning and convergence analyses to settings with neural function approximation, partial observability, large vocabularies, and non-Markovian generation, including conditions under which guarantees degrade.
- Domain-specific granularity choices remain ad hoc:
- Compare action granularity (token-, line-, block-, function-level) and identify regimes where each is optimal; provide criteria for selecting granularity based on task structure and model capacity.
- Long-term maintenance of abstractions across training stages:
- Study how RA3 latents persist or drift through subsequent supervised fine-tuning and RLVR; propose mechanisms (e.g., regularization, distillation) to preserve useful abstractions.
- Missing diagnostics for pruning error versus RL error contributions:
- Build instruments to empirically decompose end-to-end improvements into pruning efficiency and RL convergence effects, validating the regret decomposition with measurements.
Glossary
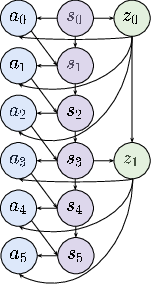
- Action abstractions: Temporally extended, high-level actions that summarize sequences of primitive actions to compact the decision space and shorten planning. "operating in the space of action abstractions rather than primitive actions."
- Action subspace: A selected subset of the overall action space used for planning or learning after pruning or abstraction. "an action subspace that minimizes both the value approximation error from pruning and the RL error during subsequent planning."
- Action-set pruning error: The approximation loss incurred by restricting the action set to a subset during mid-training. "action-set pruning error"
- Advantage: A baseline-normalized measure of action utility used in policy gradient methods to reduce variance. "the advantage is calculated within the group :"
- Bellman backup: The dynamic programming update that propagates value estimates via the Bellman operator. "each Bellman backup jumps across steps in one shot"
- Bernoulli KL: The Kullback–Leibler divergence between two Bernoulli distributions, often used as a regularizer. "The KL decomposes into a Bernoulli KL regularizer and an entropy term."
- Dirac delta function: A distribution concentrated at a single point, used to enforce persistence of a latent across time. " is the Dirac delta function"
- Effective planning horizon: The number of decisions effectively needed during planning, reduced by temporally extended actions. "shortens the effective planning horizon"
- Evidence Lower Bound (ELBO): A variational lower bound on log-likelihood used to learn latent variables and model parameters. "we derive a sequential Evidence Lower Bound (ELBO) for the NTP objective:"
- Expectation–Maximization (EM): An iterative procedure alternating between inferring latents (E-step) and optimizing parameters (M-step). "in an Expectation–Maximization (EM) manner."
- Group Relative Policy Optimization (GRPO): A policy optimization algorithm that computes advantages relative to a group of samples. "Group Relative Policy Optimization (GRPO)"
- Imitation learning: Learning a policy by matching expert behavior, typically via maximizing action likelihood. "Next-token prediction (NTP) during mid-training can be viewed as imitation learning on an offline expert dataset "
- KL divergence: A measure of discrepancy between probability distributions, used here to regularize latent policies. "the KL divergence enforces temporal consistency, ensuring that the latents function as coherent action abstractions."
- Markov Decision Process (MDP): A formal framework for sequential decision-making defined by states, actions, rewards, and a discount factor. "A task is an MDP"
- Markov options: Temporally extended actions (options) within MDPs that encapsulate policies, initiation, and termination conditions. "Action abstractions are defined analogously to Markov options"
- Next-token prediction (NTP): An objective that maximizes the likelihood of the next token given the context. "The next-token prediction objective in \eqref{eq_ntp} is lower bounded by"
- Policy prior: The inductive bias or initial distribution over actions that guides and stabilizes subsequent RL. "the strengthened policy prior, often established through mid-training"
- Pruning efficiency: How effectively mid-training removes suboptimal actions from the decision space with finite expert data. "pruning efficiency, which determines the initial RL policy prior"
- Pruning error: The performance gap introduced by restricting the action space during mid-training. "the pruning error in Lemma \ref{lemma_r} satisfies"
- Regret decomposition: A breakdown of RL regret into pruning-induced approximation error and post-training RL error. "Regret Decomposition"
- Reinforcement Learning with Verifiable Reward (RLVR): An RL setup where rewards are given by a verifier that checks solution correctness. "In RLVR, a common setup is to formulate the problem as a single-step MDP with a binary, outcome-based reward"
- Temporal abstractions: High-level actions that persist over multiple time steps, reducing decision frequency. "learning temporal action abstractions during mid-training"
- Temporal consistency: The property that a latent (high-level action) remains constant across its duration to form a coherent abstraction. "the temporal consistency of the latents"
- Temporal variational lower bound: An ELBO formulated for sequences to learn temporally consistent latent structures. "we derive a temporal variational lower bound for the next-token prediction (NTP) objective."
- Truncated return: A credit assignment strategy that sums rewards over a fixed, short future horizon. "we replace the -horizon objective with a $5$-step truncated return"
- Value approximation error: The discrepancy between the optimal value and the value achievable under a restricted action set. "the value approximation error from pruning"
- Value iteration: A dynamic programming algorithm that iteratively applies the Bellman optimality operator to compute optimal values. "Our result is based on value iteration due to its simplicity."
- Variational posterior: An approximate distribution over latent variables used to optimize the ELBO. "a parametric variational posterior "
- Verifier: A function that automatically checks the correctness of an output to produce a reward signal. ""
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that leverage the paper’s findings and RA3 method to deliver value now.
- Software (Code Assistants): RA3 mid-training for code LLMs to improve pass@k and accelerate RLVR
- What: Insert “think/act” latents (e.g., newline vs. comment line) during mid-training to learn skill-like abstractions (e.g., BFS, dummy-head patterns), then fine-tune and optionally run RLVR with unit-test verifiers.
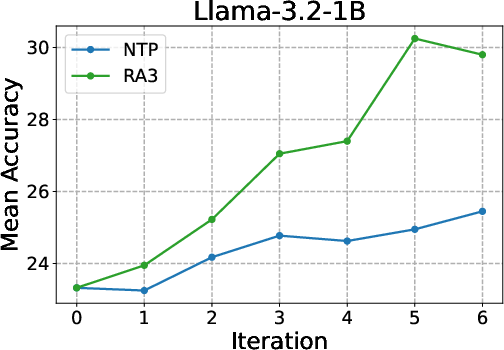
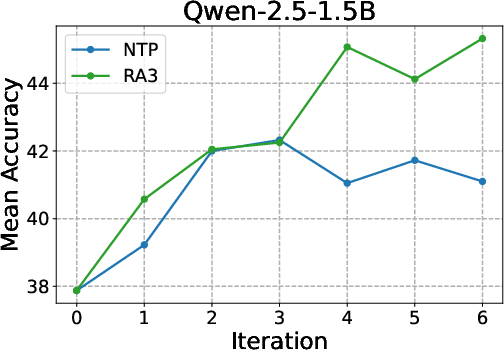
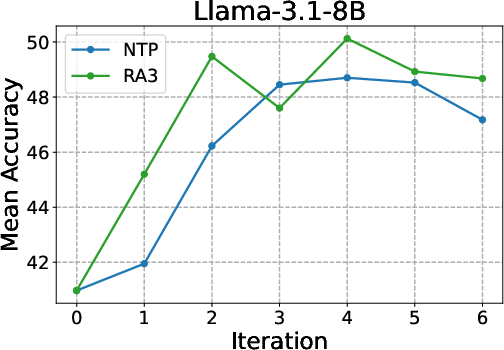
- Why: The paper shows consistent gains over next-token prediction (NTP): +4 avg points vs. NTP and +8 over base; faster and higher RLVR asymptotes on HumanEval+, MBPP+, LiveCodeBench, Codeforces.
- Tools/workflows: BigCode evaluation harness, SGLang asynchronous rollouts, GRPO for RLVR, CI-driven verifiers (pytest), IDE plug-ins that toggle “visible rationale” or keep it as hidden comments.
- Assumptions/dependencies: Availability of expert code data and verifiable test suites; compute for EM iterations; legal/ethical code data use.
- Software (Agentic Web Automation): Learn reusable web “skills” as action abstractions
- What: Mid-train browser agents on demonstrations to discover temporally-extended actions (login, search, checkout) and reduce reasoning overhead while improving success rates.
- Why: Theoretical results favor compact action sets and shorter effective horizons, improving planning and RL convergence.
- Tools/workflows: Playwright/Selenium traces as expert demos; verifiers (DOM state checks, end-to-end success criteria); GRPO-based RLVR.
- Assumptions/dependencies: Well-instrumented demos and reliable task verifiers; sandboxing and safety policies.
- Customer Support (Industry Operations): Structured resolution flows with minimal reasoning
- What: Abstract actions like “clarify,” “retrieve policy,” “issue refund,” and “close ticket,” learned from support transcripts/logs.
- Why: Pruned action sets can reduce exploration and increase consistency; KL penalty limits unnecessary explanations.
- Tools/workflows: CRM integration (Zendesk, Salesforce), outcome verifiers (first-contact resolution, QA audits).
- Assumptions/dependencies: Access to high-quality logs and accurate success labels; strong governance for customer data.
- Data/Analytics (ETL and SQL Generation): Template-and-emit abstractions for program synthesis
- What: Learn options like “design transformation” (think) followed by “emit SQL/Dataframe code” (act) using unit-test verifiers.
- Why: Temporally consistent latents produce reusable plan-then-code patterns, improving reliability.
- Tools/workflows: dbt tests, Great Expectations verifiers; CI pipelines with automatic regression checks.
- Assumptions/dependencies: Test coverage; curated expert datasets.
- Education (Programming Tutors): Minimal, targeted hints before code
- What: RA3 discovers concise, reusable hint patterns followed by code emission; tutors can reveal or hide “think” comments.
- Why: Empirically reduces cross-entropy and improves task accuracy; aligns with pedagogical “explain then do” workflows.
- Tools/workflows: Sandboxed graders, hidden-unit tests for automated feedback; LMS integration.
- Assumptions/dependencies: Verifiable exercises; educational data sharing agreements.
- MLOps (Training Efficiency Controls): Reasoning budget via KL penalty
- What: Use the α/c penalty (or fixed cost) to cap rationales and control inference/training cost at mid-training scale.
- Why: The KL acts as a knob to trade off compute vs. reasoning performance; temporal consistency reduces rollout frequency.
- Tools/workflows: Training orchestrators (Kubernetes, Ray), cost monitoring, dynamic penalty schedules.
- Assumptions/dependencies: Ability to adjust training pipelines; telemetry to measure “reasoning frequency.”
- Academia (Methodology and Benchmarks): Evaluate mid-training through action-subspace quality and RL convergence
- What: Adopt the paper’s regret decomposition, pruning efficiency, and convergence metrics to study mid-training designs.
- Why: First formalization connecting mid-training to post-RL via action-set pruning and effective-horizon shortening.
- Tools/workflows: Reproduce RA3 with open RL frameworks; report |Z̄| proxies, effective horizon, and pass@k.
- Assumptions/dependencies: Public datasets with expert demos; compute to run EM and RLVR baselines.
- Daily Productivity (Spreadsheets, Scripting): Hidden “reason-then-act” for formulas and small scripts
- What: Learn short “planning” abstractions before emitting final formulas/scripts; keep rationale hidden by default.
- Why: Better correctness with minimal token overhead; aligns with “explainable when needed.”
- Tools/workflows: Excel/Sheets add-ins, Notebook extensions (VS Code/Jupyter) with test cells as verifiers.
- Assumptions/dependencies: Small verifiable test cases; privacy-preserving local or on-device options.
- Policy/Procurement (Tech Governance): Require verifiable RLVR and action-pruning reporting
- What: For procurement of code/agent systems, mandate verifiable reward setups and disclose pruning metrics/effective horizon.
- Why: Encourages safer, more robust LLM deployments; aligns incentives toward measurable reliability.
- Tools/workflows: Standardized evaluation checklists and reporting templates.
- Assumptions/dependencies: Sector-specific verifiers; consensus on reporting standards.
- Security and Safety (Guardrails): Reduce attack surface via pruned action sets
- What: Restrict models to vetted high-level actions (e.g., safe tool calls, safe code patterns) discovered in mid-training.
- Why: Smaller near-optimal action subsets can reduce unsafe exploration during RL and deployment.
- Tools/workflows: Policy filters, tool whitelists; red-team verifiers that act as RLVR rewards.
- Assumptions/dependencies: Defined safety policies and reliable detection/verifier infrastructure.
Long-Term Applications
These opportunities build on the paper’s theory and RA3 approach but need further research, domain data, or scaling.
- Robotics (Embodied Control)
- What: Learn reusable manipulation options (grasp→place, open→insert) to shorten planning horizons and improve sample efficiency.
- Sectors: Robotics, Manufacturing, Logistics.
- Tools/products: ROS/MoveIt pipeline; simulators (Isaac, MuJoCo); “options library” for robot skills.
- Assumptions/dependencies: High-quality expert demos; verifiable rewards from sensors; sim2real transfer; safety certification.
- Healthcare (Clinical Pathways as Options)
- What: Encode care pathways (history→labs→diagnosis→therapy) as temporal abstractions; constrain exploration to guideline-consistent actions.
- Products/workflows: Decision support that proposes pathway steps with transparent, minimal reasoning.
- Assumptions/dependencies: Strict data governance, bias audits, offline evaluation before prospective trials; outcome verifiers are challenging.
- Finance (Trading/Operations Workflows)
- What: Multi-step abstractions (signal validation→order routing→risk hedge→post-trade) to reduce horizon and stabilize RL.
- Products: Copilots for operations and compliance workflows; strategy research assistants.
- Assumptions/dependencies: Robust simulators/backtests; risk, compliance, and audit requirements; delayed/implicit rewards.
- Energy and Smart Grids (Hierarchical Control)
- What: Options for scheduling and dispatch (e.g., 5–15 minute control loops), enabling faster convergence in long-horizon operations.
- Products: Grid and building energy optimizers; DER orchestration assistants.
- Assumptions/dependencies: High-fidelity simulators; safety-critical verification; regulatory approval.
- Scientific Discovery and Lab Automation
- What: Experiment “protocol options” (prepare→measure→analyze) as abstractions to guide planning and reduce exploration burden.
- Products: Automated method planners integrated with lab robots and ELNs.
- Assumptions/dependencies: Programmatic lab interfaces; accurate success verifiers; data scarcity.
- Multi-Agent Systems (Shared Skill Libraries)
- What: Learn a common set of action abstractions that multiple agents reuse across tasks/domains.
- Products: Enterprise agent platforms with pluggable skills; coordination via higher-level options.
- Assumptions/dependencies: Inter-agent protocols; skill versioning; credit assignment across agents.
- Foundation Model Training (Cross-Modality Action Abstractions)
- What: Extend the temporal ELBO to multi-modal settings (vision, speech) to learn general-purpose skills during mid-training.
- Products: Multimodal assistants that “plan-then-act” efficiently with minimal reasoning verbosity.
- Assumptions/dependencies: New latent designs/tokenization; large-scale curated demos; compute budgets.
- Tool Use and API Orchestration (Macro-Actions)
- What: Define API macro-calls (search→retrieve→summarize→file) as options; verify success with task-specific checks.
- Products: Workflow builders where models select from audited macro-actions; reduced hallucination by constraining tools.
- Assumptions/dependencies: Tool wrappers with strong schemas; stable verifiers; observability.
- Safety, Alignment, and Auditing
- What: Use pruning to restrict models to permissible action subsets; audit effective horizon and convergence behavior.
- Products: “Action-subset” attestations in model cards; automated audits during updates.
- Assumptions/dependencies: Community metrics for pruning efficiency and effective horizon; regulator buy-in.
- Low-Resource and Domain-Specific Models (Data Efficiency)
- What: Apply RA3 to reduce expert data needs by focusing on compact near-optimal action sets in specialized domains (law, chem, CAD).
- Products: Niche assistants with strong priors; faster adaptation with limited data.
- Assumptions/dependencies: Availability of expert demonstrations; domain verifiers; careful generalization studies.
- Benchmark and Standards Development
- What: Create standardized measures for pruning efficiency (|Z̄| proxies), effective horizon (γ̄), and RL convergence under action abstractions.
- Products: Public leaderboards reporting mid-training action-space metrics, not just final accuracy.
- Assumptions/dependencies: Community consensus; shared artifacts; reproducibility tooling.
Cross-Cutting Assumptions and Dependencies
- Existence of meaningful temporal abstractions: Tasks must admit reusable, high-level “skills” that improve pruning and shorten effective horizons.
- Expert demonstrations: Mid-training relies on sufficiently representative, high-quality expert data; distribution shift can degrade outcomes.
- Verifiable rewards: RLVR benefits from robust verifiers (tests, checkers, audits); many real-world domains need proxy or delayed rewards.
- Compute and infrastructure: EM-style training with self-supervised RL requires scalable rollout and fine-tuning pipelines; cost is controllable via KL/penalty schedules.
- Safety and compliance: Pruned action spaces should be aligned with domain policies; logging and audit trails are recommended, especially in regulated sectors.
- Generalization beyond code: While code results are strong, transferring to other domains may require new priors, latent formats, or verifiers.
Collections
Sign up for free to add this paper to one or more collections.