- The paper introduces a novel PPT framework that augments Decision-Pretrained Transformers with an intrinsic curiosity signal during offline pretraining.
- It employs an auxiliary predictor to generate a curiosity bonus via squared error, steering exploration in biased, static datasets.
- Experimental results on multi-armed bandit tasks show that PPT lowers regret and improves performance under out-of-distribution conditions.
In-Context Curiosity: Distilling Exploration for Decision-Pretrained Transformers on Bandit Tasks
Introduction and Motivation
The work "In-Context Curiosity: Distilling Exploration for Decision-Pretrained Transformers on Bandit Tasks" (2510.00347) directly addresses the core limitation of Decision-Pretrained Transformers (DPTs): their inability to generalize in out-of-distribution (OOD) contexts from biased offline data typical of contemporary sequence-model-based RL pipelines. DPTs, while powerful for offline imitation and in-distribution generalization, are substantially impaired when the pretraining dataset lacks diversity or is highly biased—conditions common in real-world offline settings. The hypothesis of this paper is that incorporating exploration bias during the offline pretraining stage can partially mitigate this failure mode.
To this end, the authors introduce in-context curiosity, implemented through a lightweight intrinsic reward proxy into the pretraining phase, resulting in the Prediction-Powered Transformer (PPT) framework. PPTs augment the pretraining pipeline with a learned reward predictor whose prediction error serves as a curiosity signal, biasing the policy toward uncertain or under-explored actions.
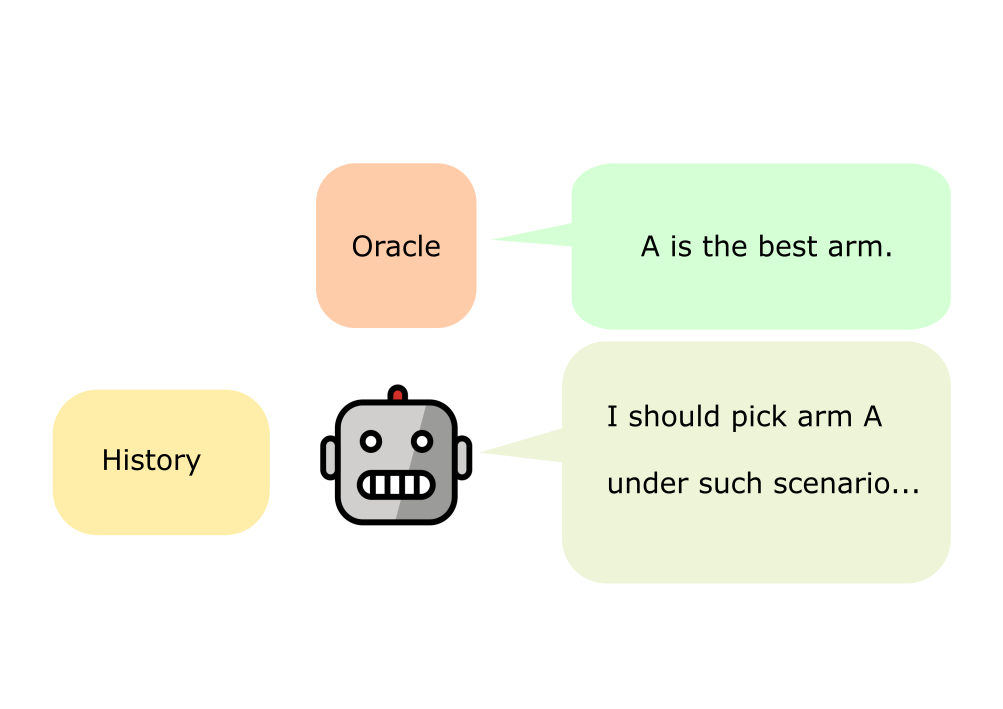
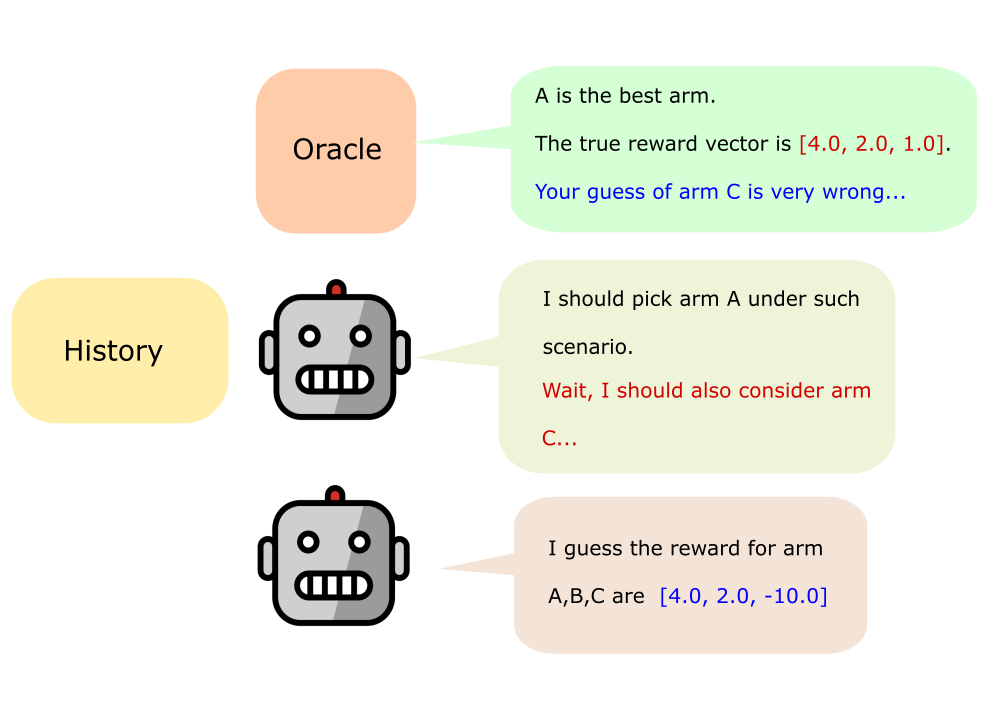
Figure 1: Diagrammatic overview of standard DPT (left) and DPT with in-context curiosity regularization (right), introducing an additional round of prediction and self-reflection during pretraining.
Methodology: In-Context Curiosity and the PPT Framework
Exploration Distillation
Classical RL achieves effective exploration primarily via online intrinsic-reward mechanisms such as the Intrinsic Curiosity Module (ICM), where agents are rewarded for visiting unpredictable states. The key algorithmic innovation in this work is transplanting this concept to a fully offline pretraining regime. Since pretraining is based on static trajectory datasets, the standard setup of augmenting environment rewards with intrinsic signals is infeasible. Instead, PPT integrates a curiosity bonus directly into the supervised learning objective. The curiosity signal is parameterized as the squared error between the reward predictor’s estimates and ground-truth means for each action, evaluated at each decision point in the trajectory.
Model Architecture
PPT extends DPT by introducing an auxiliary predictor qϕ alongside the standard policy model πθ. At each pretraining timestep, qϕ predicts the expected reward for each arm, which then computes a curiosity signal per arm. The policy model is conditioned not only on past observations, actions, and rewards, but also on these predicted rewards. During training, the policy is updated on a composite loss: standard negative log-likelihood of the demonstrated (optimal) action, augmented by the curiosity-weighted expected prediction error.
The loss for the policy is defined as:
Lθ=E[−logπθ(a∗∣Dj,c1:j)−λ⟨Ej,πθ(⋅∣Dj,c1:j)⟩]
where Ej is the per-arm squared error of reward prediction, and λ is a tunable exploration weight.
Experimental Study: Generalization Improvements
The empirical focus is on Gaussian multi-armed bandit (MAB) environments, chosen for their diagnostic value: the absence of temporal state transitions isolates the effect of offline exploration. Two offline pretraining dataset regimes are analyzed:
- Ideal dataset: Well-explored, low-bias data.
- Tricky dataset: Highly biased towards expert demonstrations, inducing poor coverage and challenging generalization.
Regret and Suboptimality under Distribution Shift
Across increasing test environment reward variances, PPT consistently yields lower average regret growth than baseline DPT—especially pronounced when pretraining is performed with a tricky dataset.
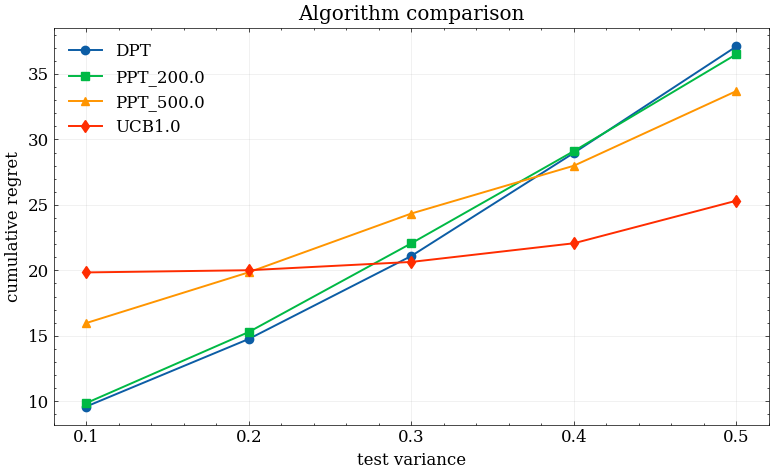
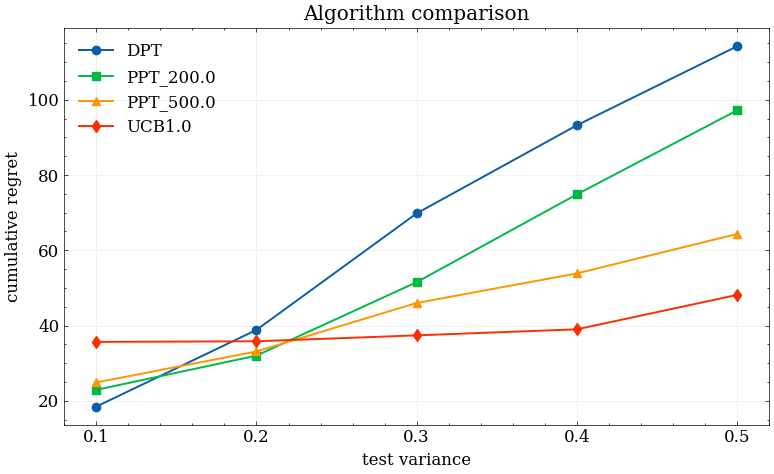
Figure 2: Average regret across rising test environment variance σtest2, contrasting DPT (steeper increase) and PPT (slower degradation). Left: ideal, right: tricky pretraining data.
Qualitatively, this reflects that the exploration bias during training makes the deployment policy less susceptible to spurious correlations learned from biased datasets. The effect persists, albeit less strongly, when offline data is already diverse.
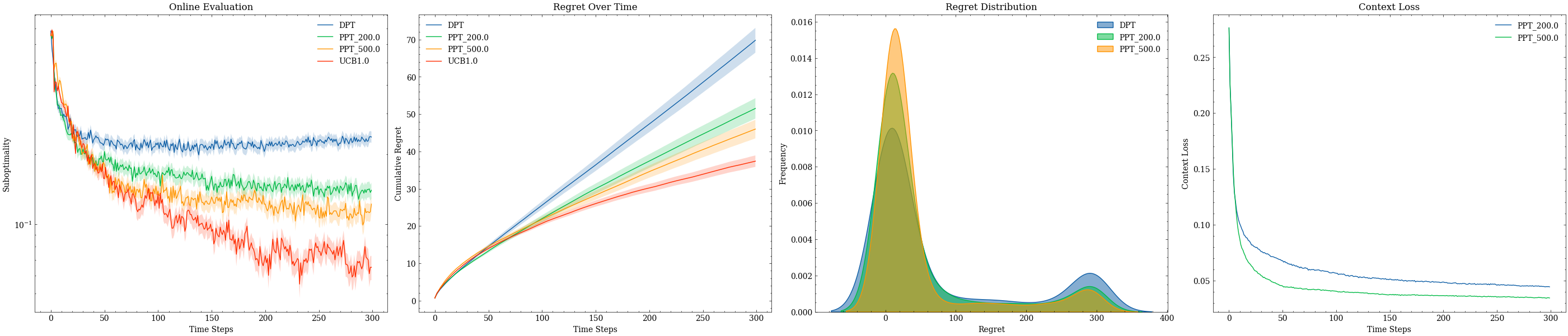
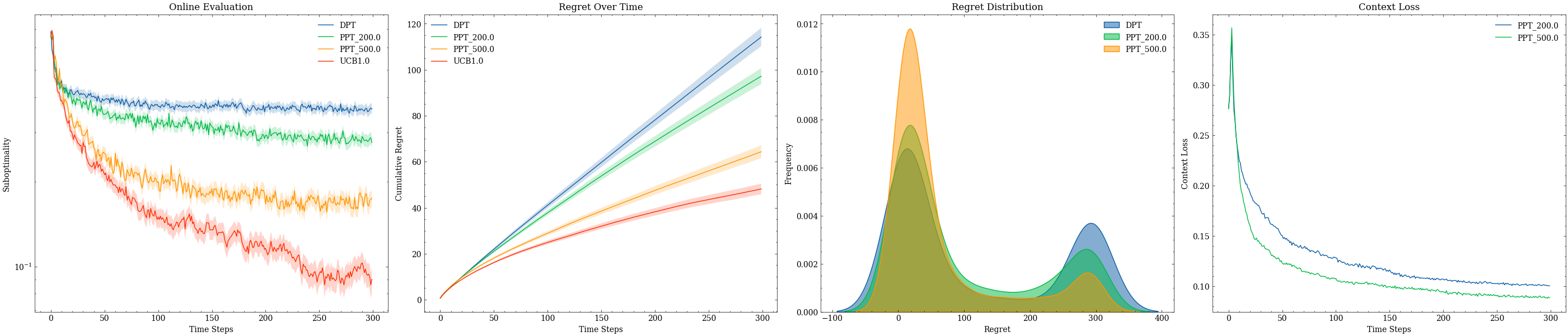
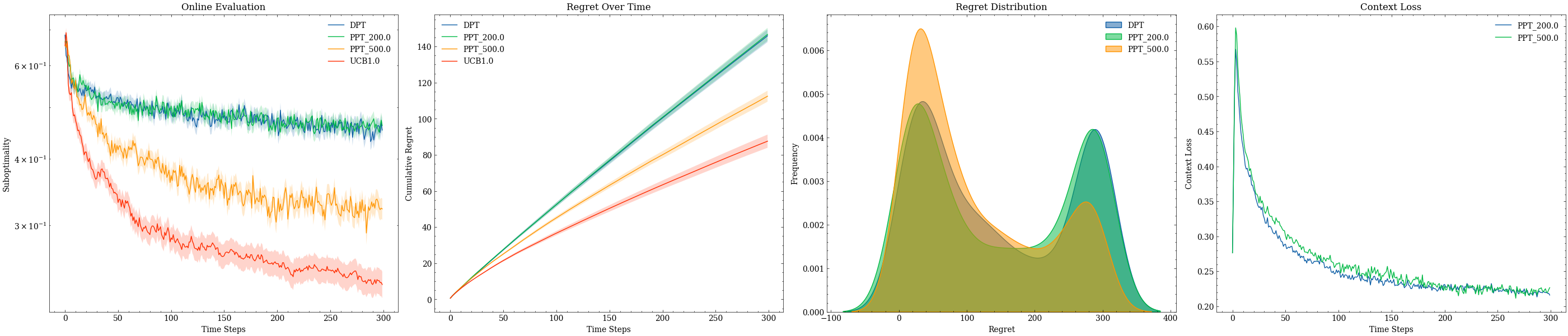
Figure 3: Per-run performance of PPT versus DPT at multiple test environment variances with tricky pretraining data; PPT maintains lower regret and tighter performance distributions across OOD environments.
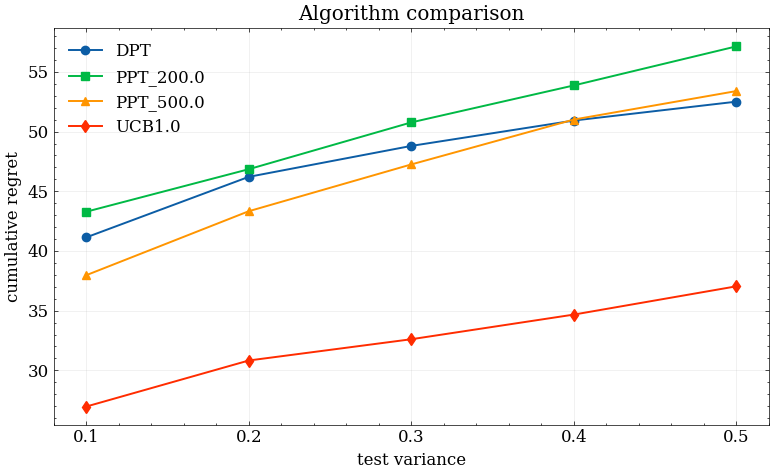
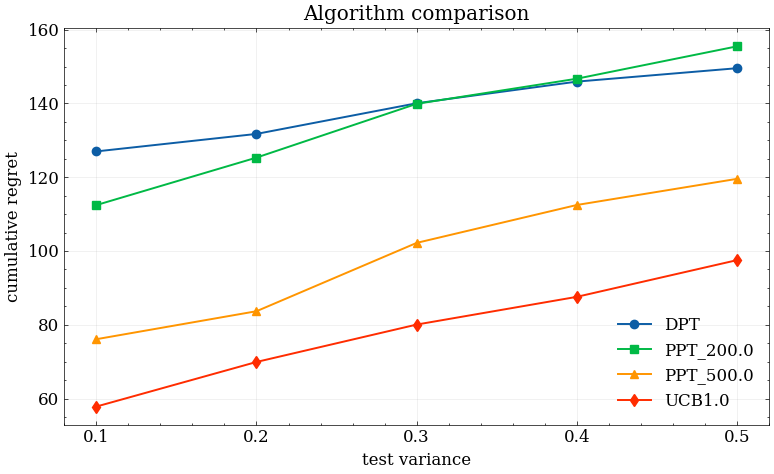
Figure 4: As test variance further increases, the difference in average regret between PPT and DPT narrows, indicating diminishing returns of curiosity distillation in highly stochastic or unstructured contexts.
Predictor-Policy Dynamics and Proxy Contexts
Analysis of training dynamics demonstrates that the predictor and policy losses track each other closely, indicating that the auxiliary reward predictor can be efficiently co-optimized with the policy. When using approximated, empirical reward estimates (rather than ground-truth environment means) as the context/proxy, the policy demonstrates no substantial loss in performance, suggesting the framework is applicable without privileged information.
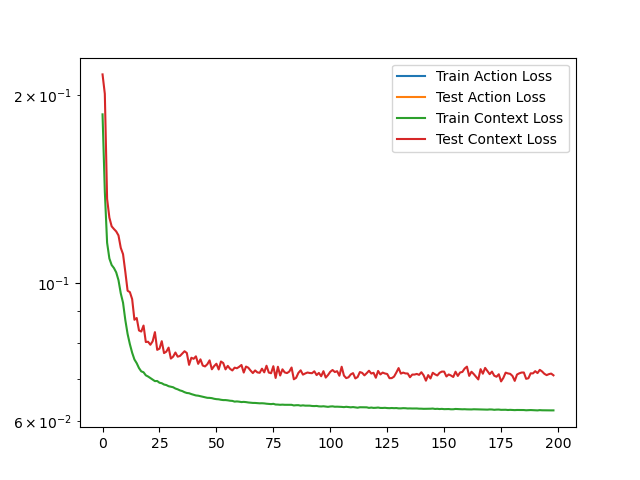
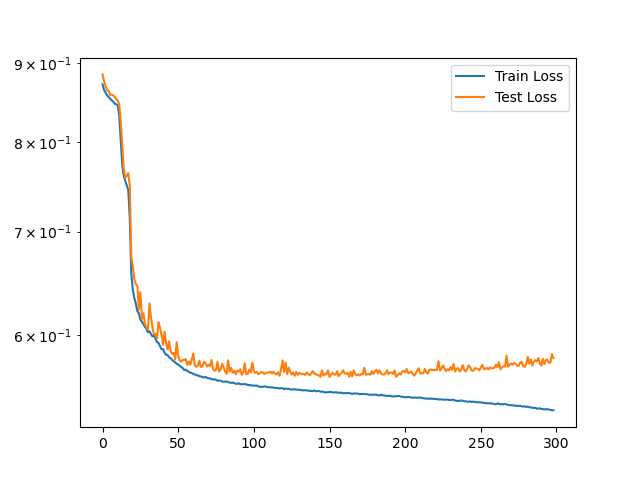
Figure 5: Synchronous evolution of the policy and predictor loss metrics during joint pretraining.
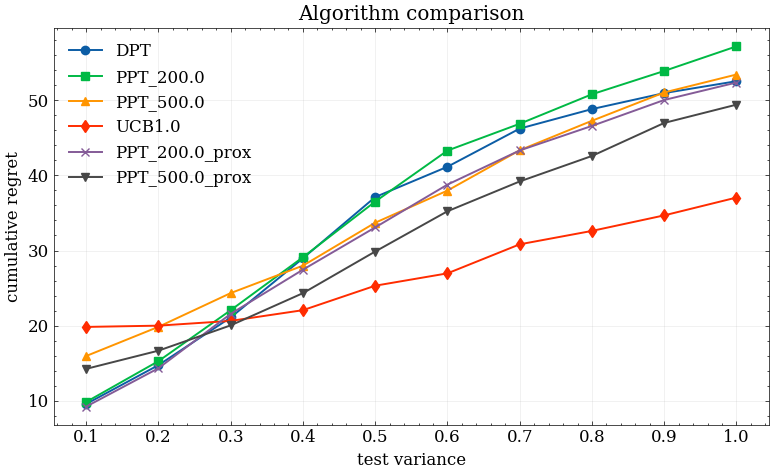
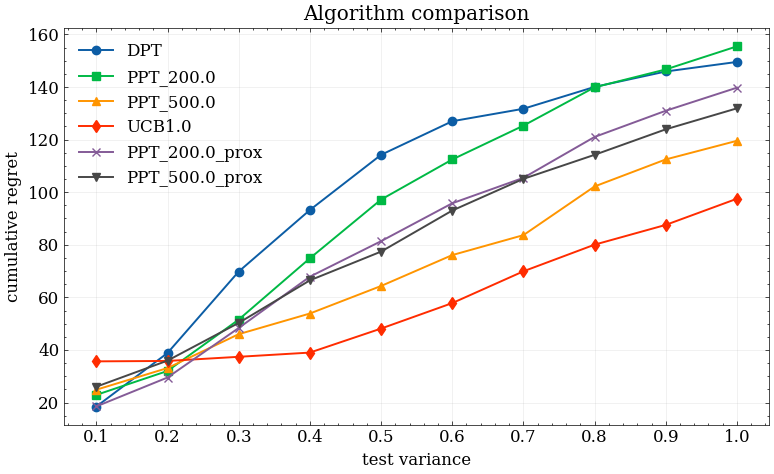
Figure 6: Regret performance when trained on ideal dataset using empirical reward estimates as context.
Theoretical and Practical Implications
The core contribution of the paper is to show that intrinsic-exploration-inspired regularization during offline supervised pretraining confers measurable robustness to sequence-model RL agents facing OOD environments, and does so with minimal disruption to the standard DPT pipeline. The auxiliary predictor module acts as a source of epistemic uncertainty, with the curiosity-driven bonus steering the policy toward actions where the baseline model is likely to under-generalize due to data coverage gaps.
However, the augmentation is not a substitute for true online or Bayesian exploration. In the high-variance regime, or with extremely poor pretraining coverage, the performance of PPT converges toward standard DPT. The fundamental limitations imposed by offline data remain binding, and the methodology does not address modeling epistemic uncertainty about the environment in the spirit of posterior sampling. Access to ground-truth or high-quality empirical reward estimates is also a practical requirement that may be non-trivial in real-world settings, but initial evidence points to the possibility of bypassing this with empirical proxies.
Future Developments
Future work should consider extending the in-context curiosity approach to Markov decision processes (MDPs) with temporal state transitions, necessitating new forms of uncertainty estimation (e.g., forward and inverse dynamic models for state evolution). It is also important to seek more robust or theoretically grounded adaptive schedules for λ (the curiosity coefficient), and to formalize principled mechanisms for integrating empirical and epistemic uncertainty. Finally, integrating with Bayesian policy sampling or amortized uncertainty quantification may provide a path toward optimal offline exploration in sequence-model-based RL.
Conclusion
This work establishes that in-context curiosity, operationalized as exploration-inspired regularization during DPT pretraining, lessens the consequences of offline dataset bias in multi-armed bandit tasks. The Prediction-Powered Transformer reliably improves OOD robustness across a range of evaluation regimes, provided sufficient data coverage for reward prediction. While not a complete solution, it advances offline RL pretraining practices and opens new directions for exploration-efficient, generalizable RL agent design.