- The paper introduces an unsupervised method that learns a discrete and interpretable facial expression dictionary using 3DMM features and a transformer-based RVQ-VAE pipeline.
- It demonstrates superior performance over AU-based and deep learning baselines on tasks such as stress and depression detection by achieving higher cosine similarity and diversity in token representations.
- The framework enhances interpretability through visualization of token effects and ablation analyses that validate the importance of sparsity, orthogonality, and multi-stage quantization.
Discrete Facial Encoding: Data-driven Unsupervised Tokenization for Facial Display Discovery
Introduction
"Discrete Facial Encoding: A Framework for Data-driven Facial Display Discovery" (2510.01662) introduces an unsupervised method for learning a compact, interpretable, and discrete dictionary of facial expression components by leveraging 3D Morphable Model (3DMM) features and Residual Vector-Quantized Variational Autoencoders (RVQ-VAE). This work builds on concerns with canonical facial expression coding systems, specifically the Facial Action Coding System (FACS), which are limited by rigid manual annotations, reduced coverage, and notable performance bottlenecks in computational AU detectors under uncontrolled conditions. The proposed Discrete Facial Encoding (DFE) approach discards manual supervision and automatically mines reusable deformation patterns on the basis of dense 3D facial geometry, thereby generating interpretable token sequences that directly reflect compositional, localized, and task-useful facial behaviors. The merits of DFE are established empirically through superiority over AU and deep self-supervised learning baselines on reconstruction accuracy, feature diversity, and psychological inference tasks.
Methodology
DFE operates in two main stages. First, expressive facial features are extracted using EMOCA, a 3DMM-based emotion-driven face reconstruction system, to yield identity- and pose-invariant expression parameters. These parameters isolate the facial expression manifold from confounders, ensuring the interpretability and semantic correspondence of downstream decomposition.
Second, these 3DMM parameters are encoded via a transformer-based RVQ-VAE pipeline (Figure 1). The encoder maps the input expression vector to a latent representation; residual vector quantization then converts this vector into a compositional sequence of discrete codewords/tokens from a learned codebook. The decoder, a minimal MLP, reconstructs the input by additive aggregation of the selected codewords. During training, the objective is the sum of a reconstruction loss, a commitment (VQ) loss, codebook sparsity, and orthogonality regularization. The sparsity term encourages local, non-global deformation specializations per codeword, while the orthogonality term maximizes non-redundancy and disentanglement in the learned dictionary.
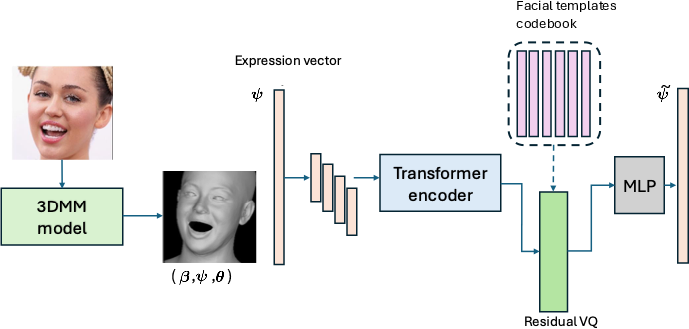
Figure 1: Overview of the proposed expression coding framework, depicting quantization of 3DMM-derived expressions into interpretable discrete tokens via RVQ-VAE.
The resulting encoding is a sequence of discrete tokens, each corresponding to a specific facial deformation template, enabling compositional representation of complex expressions.
Visualization and Interpretability
Direct interpretability is a central component of DFE. Each token's effect is visualized by applying its corresponding codeword in the 3DMM and rendering the deviation from a neutral template as a color-coded deformation heatmap (Figure 2). The learned templates span a range of localized expressive regions, respecting the anatomical modularity of face musculature, and can be interpreted as analogues or generalizations of classic AUs.

Figure 2: Deformation heatmaps visualize the spatial contribution of each discrete token to a facial deformation.
DFE’s learned vocabulary includes both global and highly localized patterns, uncovering both symmetric motions and asymmetric, culturally or individually specific variants (Figure 3).

Figure 3: Example expression templates discovered by the system, illustrating localized and distinct deformation patterns.
For an input image, DFE decomposes it into a combination of tokens whose additive synthesization reconstructs the input expression with high precision (Figure 4).

Figure 4: Real facial images and their corresponding additive token decompositions as produced by the proposed system.
Comparative Analysis: Accuracy, Diversity, and Downstream Utility
Expression Accuracy: DFE’s retrieval-based evaluation benchmarks its representational granularity against AU-based encoders. With a large set of Aff-Wild2 video frames, DFE tokens achieve markedly higher cosine similarity and lower Euclidean distance in retrieving visually expression-matched samples, as quantified both by 3D morphable model-based ground truth and self-supervised face encoder features (Figure 5).

Figure 5: Qualitative retrieval comparison between DFE and AU-based encoding; DFE retrieves exemplars with finer expression matches.
Expression Diversity: Quantitative entropy and normalized mutual information (NMI) analyses demonstrate that DFE's token space is more uniformly utilized and less redundant compared to AU activations, even when the AU features are extracted automatically. DFE tokens are highly independent and encode substantially more diverse and task-relevant expressive units.
Downstream Psychological Inference
DFE tokens are evaluated as compact video-level features for multiple high-level tasks:
- Stress Identification: On StressID, DFE outperforms both FACS and advanced video/image encoders (VideoMAE, FaceMAE, MARLIN) in binary and tri-class stress prediction, as measured by F1 and balanced accuracy.
- Depression Detection: On AVEC 2019, DFE tokens improve RMSE and CCC for regression, as well as AUC and accuracy for classification.
- Personality Trait Prediction: On ChaLearn First Impressions, DFE tokens yield superior performance for all Big Five traits, both in accuracy and CCC, compared to non-interpretable deep features and state-of-the-art FACS or data-driven baselines.
Smile Type Classification and Interpretability: On SmileStimuli, the discrimination of reward, dominance, and affiliation smiles benefits from the unique spatial compositionality of DFE tokens. The most informative tokens for each class are visualized (Figure 6).
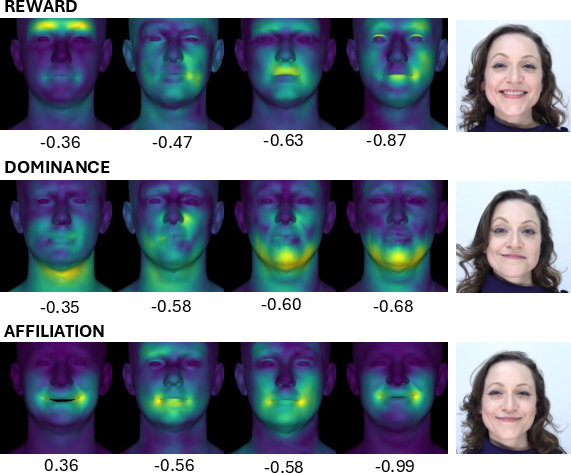
Figure 6: Top discriminative DFE expression templates for smile classification.
Ablation: Architectural Design
The design of the token codebook is critical. Removing orthogonality or sparsity regularization reduces diversity and local specialization, as visualized in the learned region overlap and mesh deformation (Figure 7). Insufficient quantization (single-stage VQ-VAE) degrades the model’s capacity to encode combinatorial expression patterns.

Figure 7: Model ablation visualizations reveal the necessity of orthogonality, sparsity, and multi-stage quantization for non-redundant and interpretable tokens.
Distributional analysis of the mesh vertex displacements (Figure 8) shows DFE enforces more localized, less scattered deformations than non-regularized or under-quantized variants.
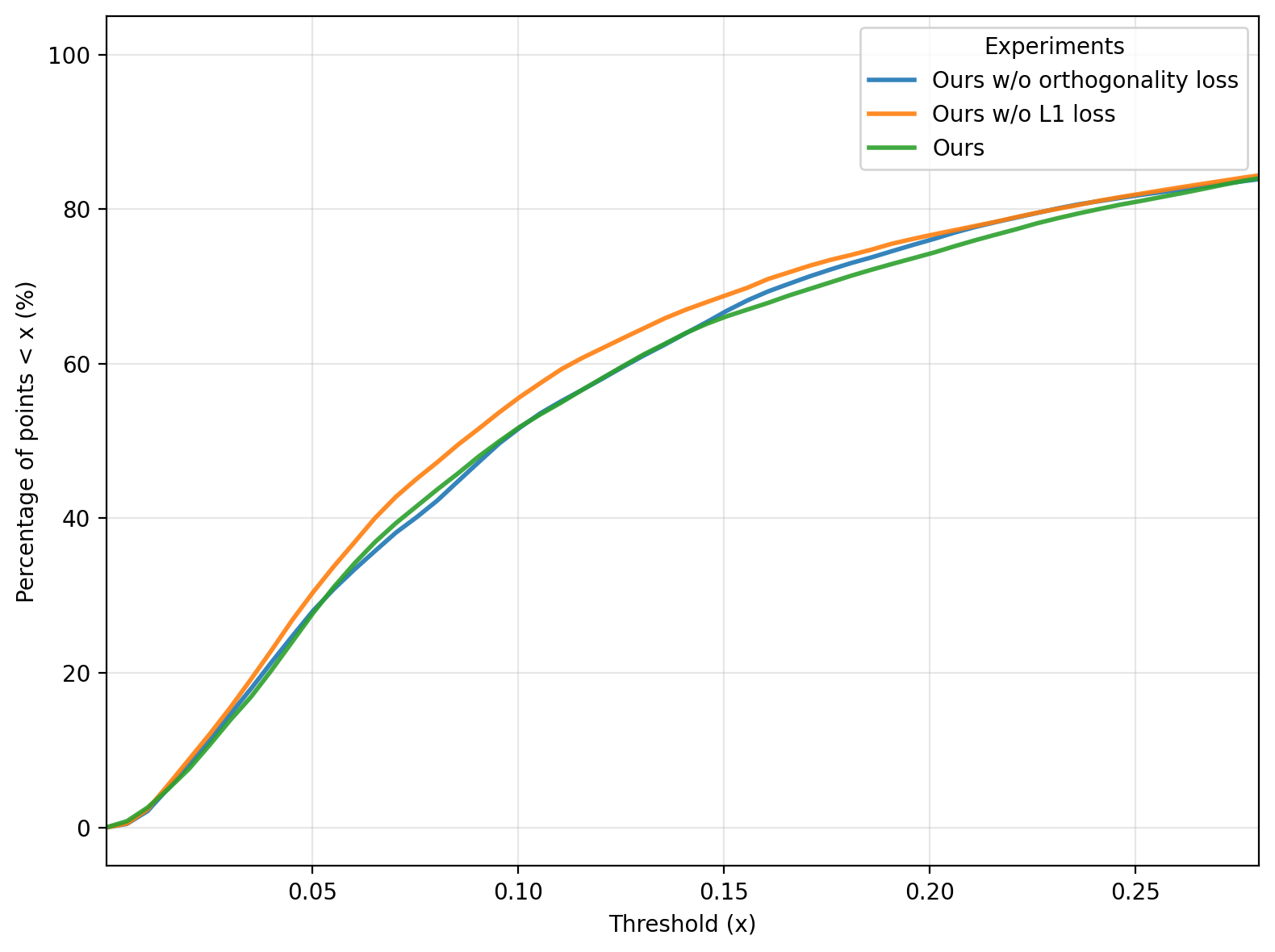
Figure 8: Percentile curve analysis of mesh vertex displacements, indicating sparsity and locality of DFE-induced deformations.
The final codebook comprises a rich set of expressive templates spanning both canonical emotions and subtle, previously unannotated micro-expressions (Figure 9).
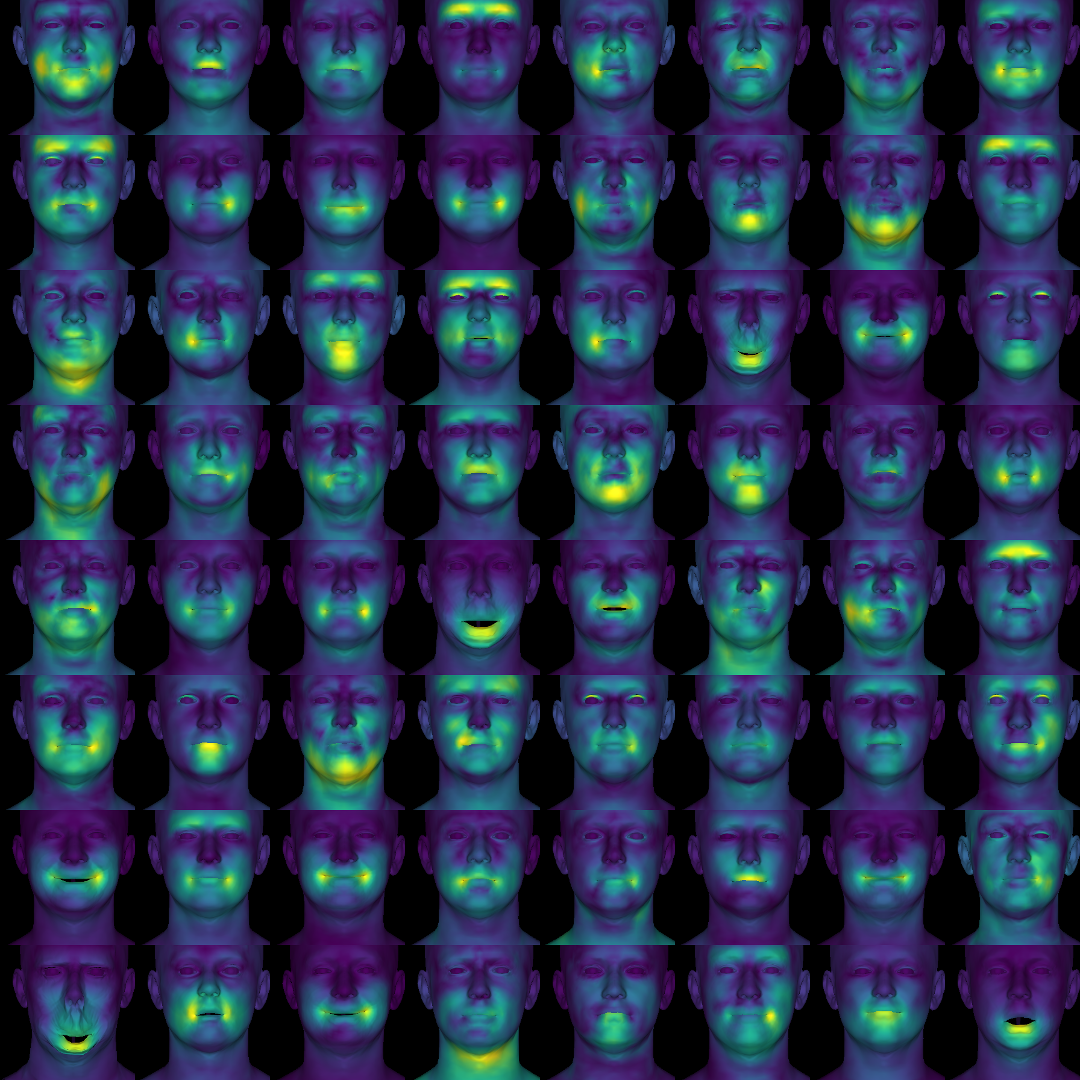
Figure 9: Visualization of the complete learned codebook, illustrating the high-frequency and compositional spectrum of facial deformations.
Practical and Theoretical Implications
DFE provides a scalable alternative to FACS for robust facial analysis in uncontrolled ("in-the-wild") applications, eliminating the cost of manual annotation and bypassing the generalization failures of contemporary AU detectors. The fact that discrete tokens outperform FACS-based and deep representation learning systems—even in challenging inference tasks—underscores the informativeness of a data-mined geometric encoding space. DFE broadens the operational expressivity of machine facial analysis beyond human-intuitive muscle groupings and aligns more closely with the actual manifold structure of facial motion.
From a theoretical standpoint, the architecture demonstrates that compositional and unsupervised tokenization in the 3DMM space affords interpretable, robust, and generalizable units for behavioral modeling. The framework opens new avenues for extending data-driven, interpretable representations to temporal and multi-modal facial behavior, for instance by integrating gaze and audio-visual context or adapting to domain shifts and demographic variation.
Limitations and Future Work
- The expressivity of DFE is contingent on the input 3DMM; inherent bias or residual identity leakage in the 3DMM propagates to the learned codebook.
- The current framework operates on static frames; temporal extension is necessary for capturing the full repertoire of dynamic facial displays.
- Variability across cultures or individual trait differences not present in training data may not be comprehensively represented.
- DFE focuses exclusively on geometry, thus ignoring color-based affective signals and non-expression behavioral cues such as gaze or posture.
Addressing these limitations—especially identity disentanglement, temporal modeling, and multi-modal integration—presents clear avenues for further research.
Conclusion
DFE defines a new paradigm for unsupervised, discrete, and interpretable facial display discovery. By leveraging 3DMM geometry and RVQ-VAE compositional encoding, it yields a practical and effective alternative to FACS, matching or outperforming existing systems in expressive precision, feature diversity, and high-level psychological inference. DFE provides a foundation for principled, interpretable, and scalable facial behavior analysis with robust generalization under real-world conditions.