- The paper presents a method to infer dynamic physical properties like elasticity, viscosity, and friction from video data using specialized readout mechanisms.
- It introduces the PhysVid dataset containing synthetic and real-world videos annotated with ground-truth values to rigorously evaluate model performance.
- Results reveal that video foundation models outperform MLLMs yet still lag behind oracle methods, especially when addressing domain shifts.
Inferring Dynamic Physical Properties from Video Foundation Models
Introduction
The paper "Inferring Dynamic Physical Properties from Video Foundation Models" (2510.02311) addresses the challenge of estimating dynamic physical properties—specifically elasticity, viscosity, and dynamic friction—from video data. Unlike static visual attributes, these properties are only inferable through temporal dynamics, requiring models to reason about motion, deformation, and interaction over time. The work introduces the PhysVid dataset, a comprehensive benchmark with both synthetic and real-world video sequences annotated with ground-truth physical property values. The study systematically evaluates three classes of models: classical computer vision oracles, video foundation models (generative and self-supervised), and multimodal LLMs (MLLMs), providing a rigorous analysis of their capabilities and limitations in physical property inference.

Figure 1: Examples from the PhysVid dataset, illustrating the diversity of physical properties and domain shifts across synthetic and real-world splits.
The PhysVid dataset is designed to probe the ability of models to infer physical properties that are not directly observable in single frames. For each property—elasticity, viscosity, and friction—the dataset contains 10,000 synthetic training videos, 1,000 synthetic test videos from the same distribution (test-1), 1,000 synthetic test videos with distribution shift (test-2), and 100 real-world test videos (test-3). The synthetic data is generated using the Genesis physics simulator, while real-world data is collected via controlled experiments or sourced from the internet.
- Elasticity: Videos of balls dropped and bouncing, with elasticity quantified as the ratio of rebound to impact velocity, or equivalently, the square root of the bounce-to-drop height ratio.
- Viscosity: Videos of liquids poured onto a surface, with viscosity inversely related to the rate of area expansion.
- Friction: Videos of objects sliding on surfaces, with dynamic friction coefficient proportional to the observed deceleration.
The evaluation is conducted in two settings: absolute value prediction (regression) and relative value comparison (binary classification between video pairs). The dataset is explicitly constructed to test generalization under nuisance parameter shifts (e.g., lighting, viewpoint, object appearance) and sim-to-real transfer.
Oracle Estimation: Upper Bound via Classical Vision
The oracle methods serve as an upper bound, leveraging privileged access to segmentation masks and geometric cues to extract the relevant physical measurements.
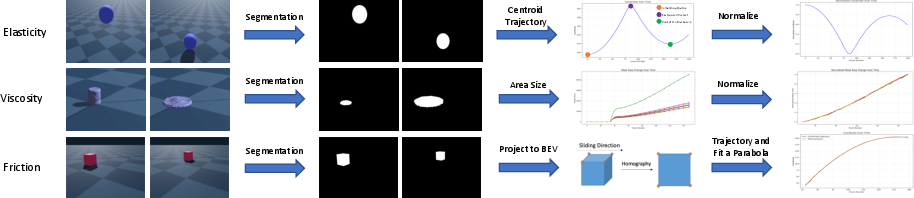
Figure 2: Oracle pipelines for elasticity, viscosity, and friction, utilizing segmentation and geometric normalization to extract property-specific cues.
- Elasticity: The centroid trajectory of the ball is extracted from segmentation masks, normalized, and processed by a GRU to regress elasticity.
- Viscosity: The area of the liquid is measured over time from segmentation, normalized by the initial contact area, and the slope of this sequence is used to estimate viscosity.
- Friction: The object's trajectory is mapped to a bird's-eye view via homography, and a quadratic fit yields the acceleration, from which the friction coefficient is derived.
These oracles achieve near-perfect performance on synthetic data and strong results on real data, demonstrating that the tasks are visually solvable given idealized cues.
Video Foundation Models: Generative and Self-Supervised Approaches
The core contribution is a unified, lightweight readout mechanism for extracting physical properties from pre-trained, frozen video foundation models:

Figure 3: Architectures for property prediction: (left) video generative model (DynamiCrafter), (middle) video self-supervised model (V-JEPA-2), (right) MLLM prompting.
- Generative Backbone: DynamiCrafter, a video diffusion model, is used as a feature extractor. A learnable query vector attends to multi-scale U-Net features via cross-attention, followed by MLP aggregation.
- Self-Supervised Backbone: V-JEPA-2, a ViT-based model, provides spatiotemporal tokens. The same query-based attentive pooling and MLP readout are applied.
For both, the backbone is frozen; only the query and MLPs are trained on synthetic data. The models are supervised with L1 or log-L1 loss for regression, and binary cross-entropy for relative comparison. To mitigate the sim-to-real gap, a red circle is overlaid on each frame to localize the relevant object or region, acting as a weak visual prompt.
Multimodal LLMs: Prompting Strategies
MLLMs (Qwen2.5-VL-Max, GPT-4o, Gemini 2.5 Pro) are evaluated via prompt engineering, with several strategies:
- Baseline: Direct question about the property, with frames as input.
- Black Frames: Separation of video pairs for relative tasks.
- Few-Shot Examples: Providing labeled examples to calibrate the model.
- Frame Indexing: Supplying frame indices to enhance temporal reasoning.
- Oracle Estimation Teaching: Step-by-step guidance mimicking the oracle's process.
Ablation studies show that few-shot examples are most effective for absolute prediction, while oracle estimation teaching improves relative comparison. However, MLLMs consistently underperform compared to video foundation models, especially on synthetic data, likely due to their reliance on semantic priors rather than low-level motion cues.
Experimental Results
- Relative Comparison (ROC AUC): Oracles achieve AUC ≈ 1.0 on synthetic splits and >0.8 on real data. Video generative and self-supervised models perform comparably on synthetic data (AUC > 0.9), but generalization to real data is property-dependent. For elasticity and viscosity, sim-to-real transfer is reasonable (AUC ≈ 0.8–1.0), but friction is challenging (AUC drops to 0.47–0.58 without domain adaptation).
- Absolute Prediction (Pearson Correlation): Oracles yield correlations >0.95 on synthetic and >0.8 on real data. Video models show strong synthetic performance (correlation >0.7), but real-world performance is significantly lower, especially for elasticity and friction. Domain adaptation (fine-tuning on real data) substantially improves friction estimation.
MLLMs lag behind, with correlations near zero or negative on synthetic data, but improved results on real data, reflecting their training distribution bias.
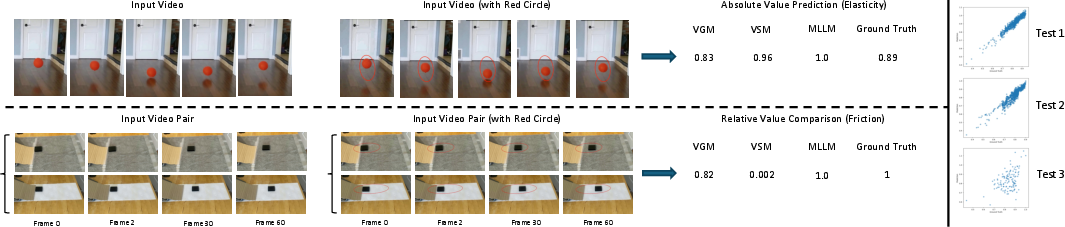
Figure 4: Qualitative results for elasticity (absolute) and friction (relative) tasks, with model predictions and scatter plots illustrating performance degradation under domain shift.
Qualitative Analysis
- Elasticity: Video models and MLLMs can approximate ground-truth values in simple cases, but fail under complex motion or occlusion.
- Friction: Generalization is poor without explicit domain adaptation, highlighting the sensitivity to visual context and geometric cues.
- Prompting: MLLMs benefit from explicit guidance and calibration, but remain limited by their inability to extract fine-grained temporal dynamics.
Implementation Considerations
- Computational Requirements: Training the readout heads is efficient, requiring only a single GPU (H100/A6000/A40). The backbone models are frozen, minimizing memory and compute overhead.
- Data Preparation: For real-world evaluation, segmentation masks and geometric annotations are required for oracle estimation. For video models, the red circle prompt is critical for sim-to-real transfer.
- Domain Adaptation: Fine-tuning on a small real-world set with disjoint objects/surfaces is effective for bridging the sim-to-real gap, especially for friction.
- MLLM Inference: Prompt engineering is non-trivial and computationally expensive, with inference cost scaling with the number of frames and prompt complexity.
Implications and Future Directions
This work demonstrates that current video foundation models encode substantial information about dynamic physical properties, but their ability to perform explicit physical reasoning is limited compared to oracles with privileged access. The gap is most pronounced in absolute value regression and under domain shift, particularly for properties requiring higher-order motion analysis (e.g., friction).
The results suggest several avenues for future research:
- Physically-Grounded Pretraining: Incorporating explicit physical supervision or inductive biases during pretraining may improve the interpretability and robustness of video representations.
- Object-Centric and Geometric Reasoning: Integrating object-centric models and geometric normalization (e.g., homography, affine invariance) can enhance generalization to real-world scenarios.
- Prompt Engineering for MLLMs: While MLLMs are flexible, their reliance on semantic priors limits their utility for fine-grained physical inference. Hybrid approaches combining visual prompting and procedural guidance may yield better results.
- Benchmarking and Dataset Expansion: The PhysVid dataset provides a rigorous testbed, but further expansion to more complex scenes, occlusions, and multi-object interactions is necessary for comprehensive evaluation.
Conclusion
The study provides a systematic evaluation of dynamic physical property inference from video, establishing strong baselines and revealing the limitations of current foundation models. While generative and self-supervised video models can extract physical cues with lightweight readouts, they fall short of oracle performance, especially in absolute prediction and under domain shift. MLLMs, despite their versatility, are not yet competitive for this class of tasks. Bridging the gap between visual perception and physical reasoning remains a central challenge for the next generation of video understanding models.
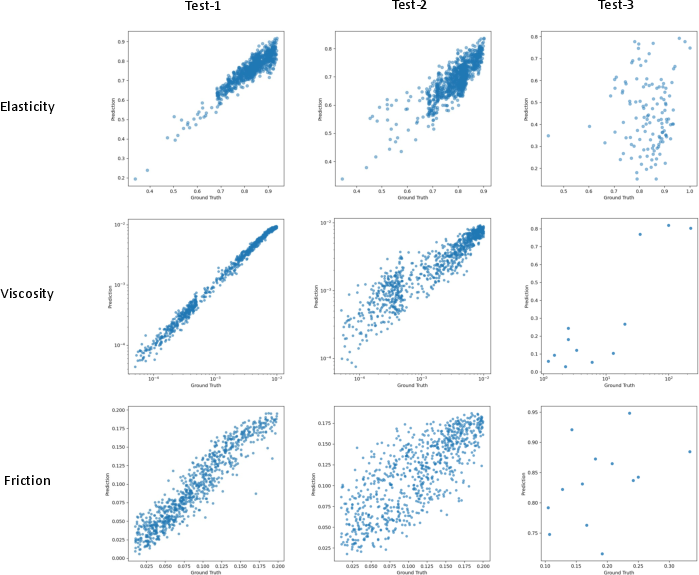
Figure 6: Scatter plots for the video generative model, illustrating the degradation in prediction accuracy from synthetic in-distribution (test-1) to out-of-distribution (test-2) and real-world (test-3) splits for elasticity, viscosity, and friction.