- The paper finds that LLM-generated Java code shows a 63% overall increase in code smells compared to professional benchmarks.
- It employs automated static analysis tools to evaluate both implementation and design smells across diverse task complexities.
- The study highlights model-specific differences and the effect of task complexity on code cleanliness, underscoring maintainability concerns.
Code Quality Assessment of LLM-Generated Java Code via Code Smell Detection
Introduction
This essay synthesizes and critically discusses the systematic evaluation of code quality in program source code generated by four leading LLMs—Gemini Pro, ChatGPT, Codex, and Falcon—focusing on the prevalence, variation, and nature of code smells compared with professionally authored Java benchmarks. The methodology, rooted in scenario-based analysis, employs static code analysis tools (PMD, Checkstyle, DesigniteJava) across a large, diverse benchmark (ScenEval) with reference solutions, encompassing a spectrum of task complexities and programming topics. The empirical data supports rigorous, quantitative answers to core research questions on code quality in LLM-generated code, examining not only statistical trends but also nuances in smell type, task complexity, and correctness.
Experimental Setup
The authors adopt a datamorphic automation methodology, integrating Morphy for orchestrated code generation, solution extraction, and code smell analysis. The core system structure segregates morphisms (functional units, e.g., LLM invocation or smell analysis) from entities (data artifacts). This modular test system enables parametric and fully automated evaluation of each LLM.
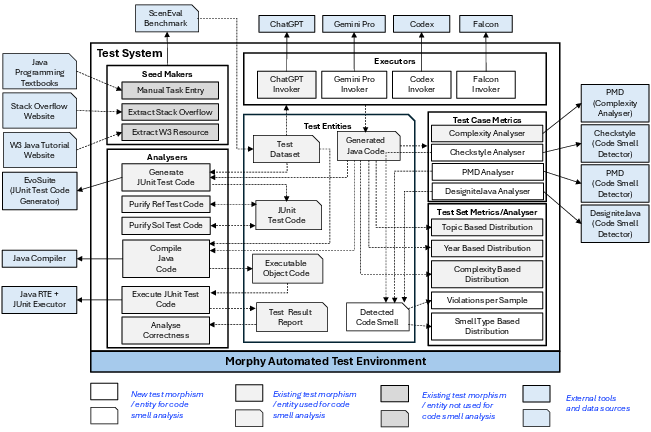
Figure 1: Schematic representation of the test system, highlighting the orchestration from task selection, LLM query, solution extraction, to code smell reporting.
The experimental pipeline comprises:
- Sampling 1,000 Java tasks (equally from textbooks and Stack Overflow) from ScenEval, spanning 25+ topics and a measured complexity distribution.
- Systematic code generation by each LLM, followed by code extraction and compilation.
- Baseline creation: code smell analysis on professionally authored solutions establishes a benchmark for violation counts by smell type.
- Automated analysis of LLM outputs using static tools with comprehensive rule sets, including both implementation (micro-level) and design (structural) smells.
- Complexity and correctness assessment using established metrics (cyclomatic complexity, cognitive complexity, lines of code) and automated test execution.
The inclusion of broad topic coverage, task complexities, and reference baseline ensures generality and robustness of conclusions.
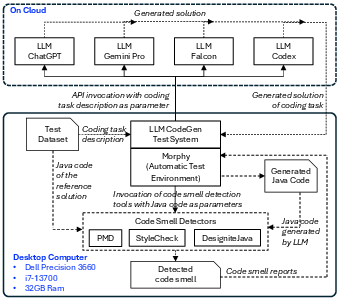
Figure 2: Illustration of the experimental setup, detailing the automated invocation of LLMs, sanity/correctness checks, and integration with static analysis tools.
Quantitative Findings
Overall Prevalence of Code Smells
LLM-generated code consistently exhibits a higher incidence of detectable code smells compared to professional reference solutions. Strong quantitative evidence includes:
- Falcon yields the lowest increase at 42.28%, while Codex reaches 84.97%.
- Average increase in smells across all LLMs: 63.34%, subdivided into 73.35% for implementation smells and 21.42% for design smells.
This magnitude of increase is statistically significant and consistent across all LLMs under test.
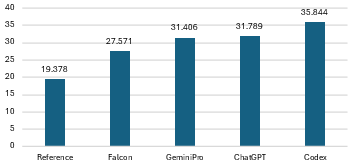
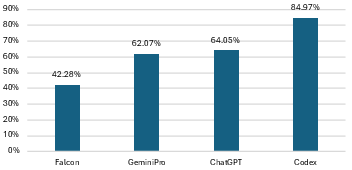
Figure 3: Baseline versus LLM-generated solution code smell violations, depicting the absolute increase for each LLM.
Variation with Task Complexity
There is robust, positive correlation between solution complexity (as measured by cyclomatic complexity, lines of code, and cognitive complexity) and the number of code smell violations. Across all metrics, Pearson coefficients exceed 0.9 (with the exception of cognitive complexity for ChatGPT), and the trend holds for both human reference and LLM solutions. However, the rate of increase in code smells relative to human code does not exhibit consistent dependence on complexity—implying that while both LLM and human code quality declines with harder tasks, the gap between machine and human code does not necessarily widen for more complex tasks.
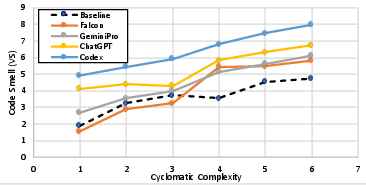
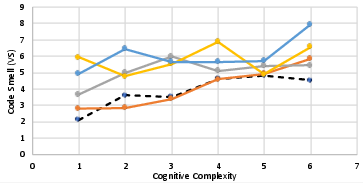
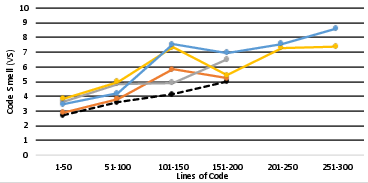
Figure 4: Relationship between code smell prevalence and task complexity (cyclomatic, cognitive, lines of code) for each LLM.
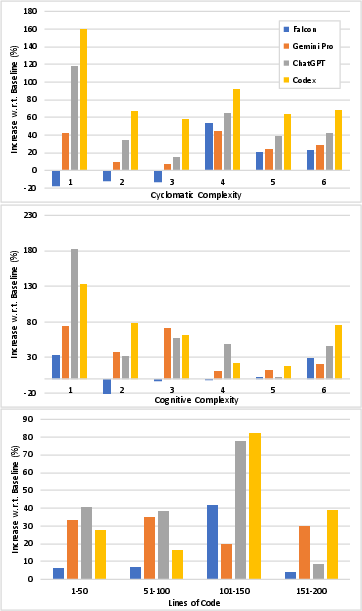
Figure 5: Rate of code smell increase over baseline as a function of complexity; lines are flat, indicating no strong correlation.
Topical and Scenario-Based Variation
Prevalence and types of code smells are highly topic-dependent, as demonstrated by both standard deviation increases and per-topic analysis:
- Topics such as Basic Exercise and String Manipulation have the lowest smell increases, while Encapsulation, Array Handling, Polymorphism, Inheritance, and other advanced topics exhibit the highest increases (up to 165%).
- Occasionally, LLM-generated code surpasses the baseline (i.e., shows improvement) for narrow task domains such as Regular Expressions, but this is an exception.
Crucially, code topics with high baseline smells in human code are strongly correlated with those in LLM code (Pearson > 0.7 across models), but there is no such correlation for the increase rate, indicating that LLMs may excel or fail disproportionately depending on the topic.
Specificity of Code Smell Types
Implementation smells—especially Magic Number, Documentation, and Improper Alignment/Placement—dominate both the baseline and LLM outputs, although the latter significantly outpace the former in raw violation counts. Smells involving Incompleteness, Inconsistent Naming, and Redundancy have the lowest baseline rates but the highest proportional increases in LLM code.
For design smells, all LLMs demonstrate a modest average increase (21.42%), with Falcon again the least affected. Encapsulation smells are consistently well-controlled in LLM-generated code, while modularity, hierarchy, and abstraction suffer from greater model-to-model variability.
Code Smells and Correctness
Analysis stratified by code correctness yields nuanced findings:
Theoretical and Practical Implications
The study demonstrates that while LLMs are capable of generating functionally correct programs, their outputs frequently violate static code quality standards at both implementation and design levels—violations which are observable and quantifiable at higher rates than in human-authored solutions, particularly as solution complexity or abstraction increases.
From a software engineering perspective, these results underscore several implications:
- Higher maintenance costs: LLM-generated code, being more "smelly", portends higher technical debt and effort for downstream maintenance, refactoring, and onboarding.
- Risk amplification in advanced domains: The exponential growth of code smells in OOP and advanced topics signals an urgent need for improved prompt engineering, LLM retraining, or post-hoc code improvement pipelines in nontrivial software domains.
- Automated code smell feedback: Integrating automated code smell detection into the LLM-assisted development lifecycle provides actionable feedback for iterative code refinement—suggesting practical utility for static analysis as a first-line quality check for machine-generated code.
- Limitation of LLMs: lack of holistic context: Many design smells arise from insufficient architectural context; an area currently outside the reach of prompt-based code generation, but pertinent to future research into multi-file, context-aware code synthesis.
- Model selection and tuning: Substantial differences among models (e.g., Falcon vs. Codex) suggest that model selection, fine-tuning, or even hybridization could be tailored to code quality requirements in different development scenarios.
Potential for Future Work
Remaining limitations include: lack of code smell thresholding for "acceptable" quality, evaluation limited to Java, and a modest fraction of multi-class or architectural code in the test set. The results motivate:
- Extension to multi-language and multi-LLM benchmarks for broader generalization;
- Integration of runtime and security analysis to couple static quality metrics with functional/performance characteristics;
- Iterative or in-the-loop code smell minimization via LLM prompting informed by static tool feedback;
- Definition and community standardization of code quality thresholds, enhancing interpretability and practical adoption.
Conclusion
Systematic, scenario-based analysis of LLM-generated code using state-of-the-art static smell detectors reveals that, while functionally viable, such code frequently falls short of professional standards for maintainability, readability, and modifiability—especially as task complexity and abstraction increase. Model selection dictates the scale and character of deficits, and the path forward lies in integrating static code quality assessment with automated, iterative generation and refinement workflows. The confluence of LLM-driven synthesis and robust static analysis constitutes a practical framework for elevating the usable quality of automatically generated code.