- The paper introduces the Propensity Smelly Score (PSC) to quantify and address code smells in LLM-generated code.
- It employs a structural causal model to evaluate factors like prompt formulation and model architecture that impact code quality.
- Experimental results show that prompt-based mitigation strategies significantly improve structural code quality beyond traditional metrics.
Summary of "A Causal Perspective on Measuring, Explaining and Mitigating Smells in LLM-Generated Code" (2511.15817)
The paper investigates the systematic issues of code smell occurrences in code generated by LLMs, and proposes a structured causal framework to measure, explain, and mitigate these occurrences using a metric termed Propensity Smelly Score (PSC). It identifies key components influencing code smell generation and proposes strategies to improve code quality, integrating causal analysis and prompt-based interventions.
Introduction
LLMs have increasingly been used to automate diverse software engineering tasks ranging from code completion to test generation. However, the generated code often replicates poor coding practices, resulting in code smells that detract from readability and maintainability. Though traditional evaluations focus largely on functional correctness through similarity metrics like BLEU and CodeBLEU, these metrics fail to adequately capture structural and design quality concerns like code smells, which are pervasive due to inherited patterns from training corpora and architectural decisions.
Propensity Smelly Score (PSC)
PSC is introduced as a probabilistic metric that estimates the likelihood of LLM-generated code producing specific types of code smells. It aggregates token-level probabilities within a code snippet to provide a continuous measure of potential code smell presence. The robustness of PSC is validated through semantic-preserving transformations, ensuring it captures the inherent structural quality signal. It offers insights beyond surface-level correctness, aligning with deeper semantic evaluations of model behavior.
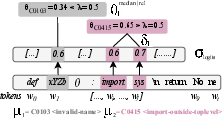
Figure 1: Propensity Smelly Score computation with examples of code smells.
Methodology
The methodology revolves around four core research questions: measuring smelly code propensity, explaining generation factors, mitigation strategies, and evaluating PSC’s practical value for developers. The structural causal model (SCM) evaluates elements like model architecture, size, generation strategy, and prompt type, quantifying their causal relationships with PSC. This informed design of prompt-based mitigation strategies to guide cleaner code generation practices.
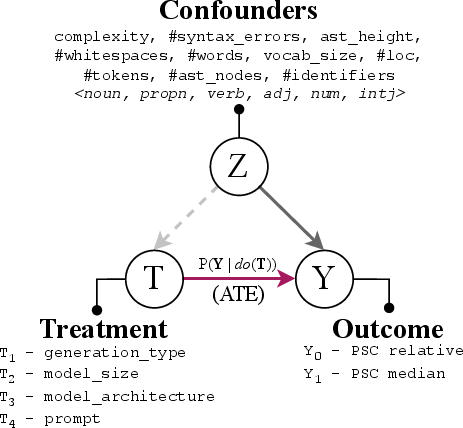
Figure 2: Structural Causal Model overviewing treatment interventions.
Experimental Results
The paper's experimental section reveals robust correlations established through PSC that are absent with BLEU and CodeBLEU scores, underscoring PSC’s superior alignment with structural quality indicators. Causal analyses identify prompt formulation and model architecture as influential factors in smell propensity, justifying prompt-based mitigation strategies as practical enhancements, while highlighting limited efficacy of model size variations.

Figure 3: Information gain results comparing PSC with traditional metrics.
Discussion
The findings detail varying impacts of prompt structure, model architecture, and decoding strategies on code quality, establishing prompt-based strategies as particularly effective. Notably, architectural adjustments are shown to influence internal token distributions, affecting structural decisions in code synthesis.
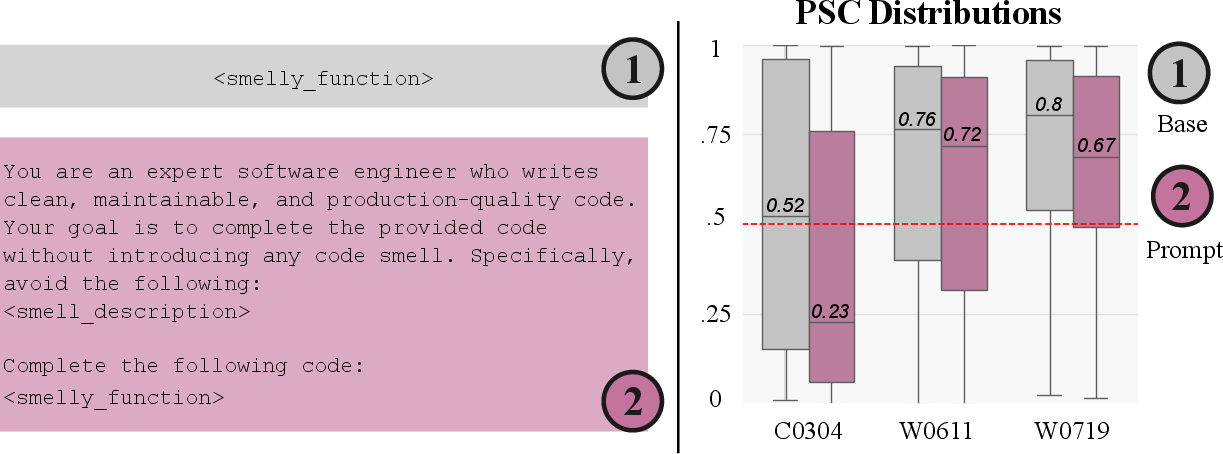
Figure 4: Results from user study indicating the practical influence of PSC on developer judgement.
Conclusions and Future Work
The study establishes PSC as a robust measure for evaluating LLM-generated code for smells and advocates for its use to guide interventions in model design and generation strategies. Future extensions should explore PSC across diverse languages and model architectures, facilitating integrated quality assessments beyond code smells, and broadening its applicability to various programming contexts.
Overall, this work contributes significantly to understanding generation-induced code quality issues and offers actionable insights for improving the structural integrity of LLM-generated software. Future efforts should prioritize extending PSC to other languages and refining mitigation strategies to encompass comprehensive, multi-dimensional code evaluations.
