- The paper introduces a Bayesian framework that replaces unstable Pass@k metrics with a robust estimator using a Dirichlet prior.
- The framework leverages closed-form posterior mean estimates and calibrated uncertainty intervals to yield reliable performance rankings.
- Empirical validations demonstrate faster convergence and statistically significant differences in LLM outputs compared to traditional methods.
Don't Pass@k: A Bayesian Framework for LLM Evaluation
Introduction to the Framework
The paper presents a Bayesian evaluation framework designed to improve upon traditional Pass@k metrics used for evaluating LLMs. The framework addresses common issues in LLM evaluation, such as instability and misleading rankings, especially when resources are limited. By modeling outcomes with a Dirichlet prior, this Bayesian approach offers posterior estimates of a model’s success probability and credible intervals, aiming to yield more stable rankings and transparent significance testing.
Limitations of Pass@k and Bayesian Advantages
Pass@k metrics are popular but suffer from high variance, particularly when the number of trials is close to the total number of model outputs. This can lead to unstable rankings and a lack of clarity about the significance of observed differences, particularly for small datasets. To overcome these limitations, the paper proposes a Bayesian framework that models evaluation outcomes categorically, with a Dirichlet prior conferring closed-form expressions for both the posterior mean and uncertainty. This framework not only supports binary outcomes but also extends naturally to graded/rubric-based evaluations.
The Bayesian method's primary contributory mechanisms include the incorporation of prior evidence to strengthen analysis robustness and the provision of a principled uncertainty estimation, which aligns closely with average accuracy yet retains analytical supremacy when trials are limited.
Results Matrix: The method begins by considering a results matrix R with outcomes modeled as categorical, allowing scores that can be expressed using any weighted rubric.
Bayesian Estimator: By using a Bayesian optimal estimator, the posterior distribution of a model's success probability considers both newly observed data and prior evidence, which result in more meaningful evaluations even in small N scenarios.
Convergence and Confidence Intervals: The proposed method accelerates convergence to a true ranking with fewer samples compared to conventional approaches. It provides confidence intervals that naturally express comparison significance—crucially, non-overlapping intervals denote statistically significant performance differences.
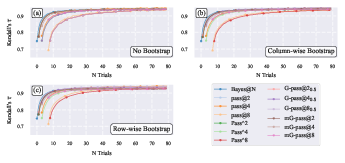
Figure 1: Kendall's tau rank correlation for various evaluation methods compared to the true ranking of 11 sets of biased coins.
Empirical Validation and Case Studies
Simulations reveal that the Bayesian framework converges faster than Pass@k, while providing clear indications of statistically significant differences in model capabilities. The empirical robustness of the method is validated using LLM evaluation benchmarks such as AIME and BrUMO datasets, where the Bayesian procedure yields greater rank stability.

Figure 2: Probability of correctly ranking various LLM methods.
Practical Implications and Future Directions
The introduction of this Bayesian framework has broad implications for LLM evaluation, recommending a shift from Pass@k to more computationally efficient, theoretically substantiated strategies. By integrating categorical outcome evaluations with a Bayesian approach, this method paves the way for more granular and multifaceted evaluation of LLM reasoning tasks.
A significant future direction is refining the incorporation of prior information to further enhance evaluation efficiency and reliability. Understanding biases in prior choice and addressing them with systematic approaches will be crucial to harnessing the full potential of Bayesian frameworks.
Conclusion
The Bayesian framework introduced in this paper significantly improves the reliability and efficiency of LLM evaluation by offering stable, interpretable rankings with explicit uncertainty quantification. This approach aligns evaluation practices with robust statistical inference principles, offering a compute-efficient alternative that promises to enhance the transparency and reliability of LLM evaluations across diverse contexts.