- The paper introduces the Variator agent that leverages LLM inconsistency to boost Pass@k performance.
- It employs a probabilistic framework with variant generation to statistically improve solution success rates, validated on datasets like APPS.
- Empirical results reveal that this method outperforms traditional repetition, offering new insights for robust AI system design.
The study titled "Leveraging LLM Inconsistency to Boost Pass@k Performance" investigates the peculiar inconsistency of LLMs and turns this limitation into an asset. By understanding and leveraging the inconsistency found within LLM outputs, the researchers have developed a method to enhance model performance, particularly under the Pass@k metric.
Introduction to Inconsistency and the Variator Agent
The paper addresses the problem of inconsistency in LLMs, where small changes in input prompts can result in significant variations in model output. Traditional approaches often regard this inconsistency as a drawback, aiming to mitigate its effects. However, this paper proposes a unique perspective—using the inconsistency to improve performance. The authors introduce the "Variator" agent, which generates multiple semantically equivalent variants of a task and processes each to output a solution, relying on LLM inconsistency as a benefit rather than a flaw.
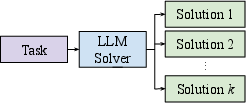
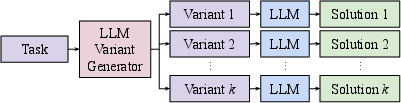
Figure 1: The baseline Repeater agent for a Pass@ task generates k candidate solutions by sampling k responses from the LLM.
The approach is grounded in the Pass@k metric, which measures success by considering correct solutions among k attempts, making it applicable to domains like coding where solution correctness can be tested programmatically.
Theoretical Framework and Analysis
The authors build a theoretical framework, utilizing a probabilistic model to validate their method. The crux of the theoretical argument lies in exploiting variance among the equivalent variants of a problem. By generating k variants and ensuring each variant can be autonomously processed by the LLM, the probability of at least one successful outcome is increased beyond the traditional "Repeater" method.
They demonstrated that this diverse variant generation causes a statistical advantage, as improvements in model performance are amplified due to the Pass@k metric's nature.
Empirical Evaluation
Empirical evaluations were conducted on both public datasets like APPS and private datasets. The experiments revealed a consistent improvement in Pass@k performance when using Variator over the Repeater baseline. Notably, the results on the APPS dataset suggest that Variator effectively mitigates issues arising from model memorization on public benchmarks.
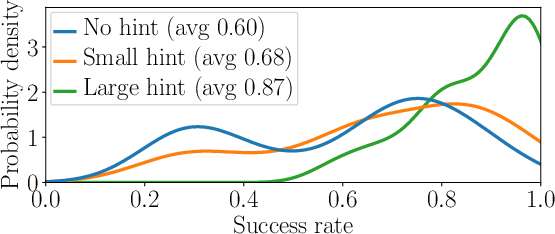
Figure 2: Distributions of success rates for 25 variants of the same challenge, with three guidance levels. The considerable overlap illustrates the significant performance impact of variants.
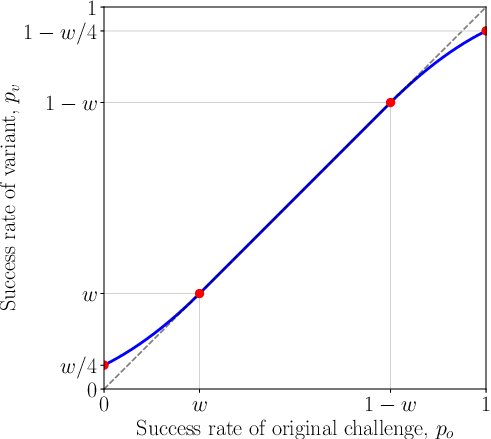
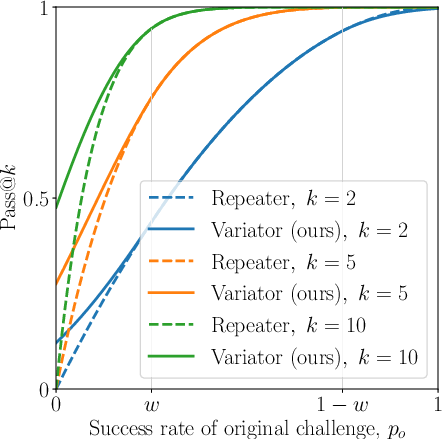
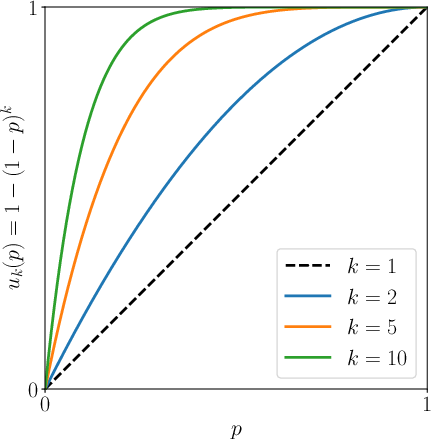
Figure 3: Expected variant success rate as a function of the original challenge success rate.
Comparisons were drawn between Variator's performance on challenges initially unseen by models, further validating that LLMs' sensitivity to prompt variations is a substantial factor impacting their efficacy and general applicability in real-world tasks.
Implications and Future Directions
This work extends beyond mere performance enhancement; it provides insights into designing future AI systems. By incorporating methods that leverage inherent model inconsistency, the study proposes an adaptive approach to AI design that transforms perceived shortcomings into strategic advantages.
For future research, the authors suggest refining variant generation processes and exploring automatic equivalence verification. There is also potential to investigate the inclusion of these methods as part of LLM training regimens to naturally encode robustness to input variation. Further, understanding the mechanisms behind LLM inconsistency at a deeper level could open pathways to not only leverage this effect but mitigate negative impacts comprehensively.
Conclusion
The paper presents a novel method of engaging with LLM inconsistency by employing a variant generation strategy to enhance Pass@k performance. By extending the utility of LLMs in tasks requiring multiple solution attempts, this research may lead to more efficient and effective LLMs in sophisticated AI applications.