- The paper introduces a dynamic weighted loss function that adjusts based on domain sparsity, amplifying signals from niche interests.
- The paper employs an attention-based architecture combined with theoretical analysis to ensure convergence and stability with minimal overhead.
- The paper demonstrates significant performance improvements, achieving a 52.4% lift in Recall@10 in the Film-Noir domain, validating its approach for sparse data.
Adaptive Weighted Loss for Sequential Recommendations on Sparse Domains
Introduction
The paper "Adaptive Weighted Loss for Sequential Recommendations on Sparse Domains" (2510.04375) addresses a critical challenge in the field of recommendation systems: catering effectively to "power users" in domains characterized by data sparsity. Traditional single-model architectures often struggle with diluting signals from niche domains due to the dominance of generic data. The paper proposes a novel approach that introduces an adaptive Dynamic Weighted Loss function, designed to enhance recommendation accuracy in sparse domains without requiring separate domain-specific models.
Methodology and Architecture
The core innovation of this paper lies in its dynamic loss weighting mechanism. Rather than employing a fixed weight as done in previous models like PinnerFormerLite [1], this approach dynamically adjusts weights based on domain sparsity. The sparsity of a domain is computed using metrics such as inverse domain frequency, user ratio, and entropy of interactions. This computation ensures that domains with fewer interactions contribute a significant weight to the overall loss, amplifying the learning signal from rare interests. The architecture processes user sequences through attention mechanisms and applies the computed dynamic weights to the loss function.
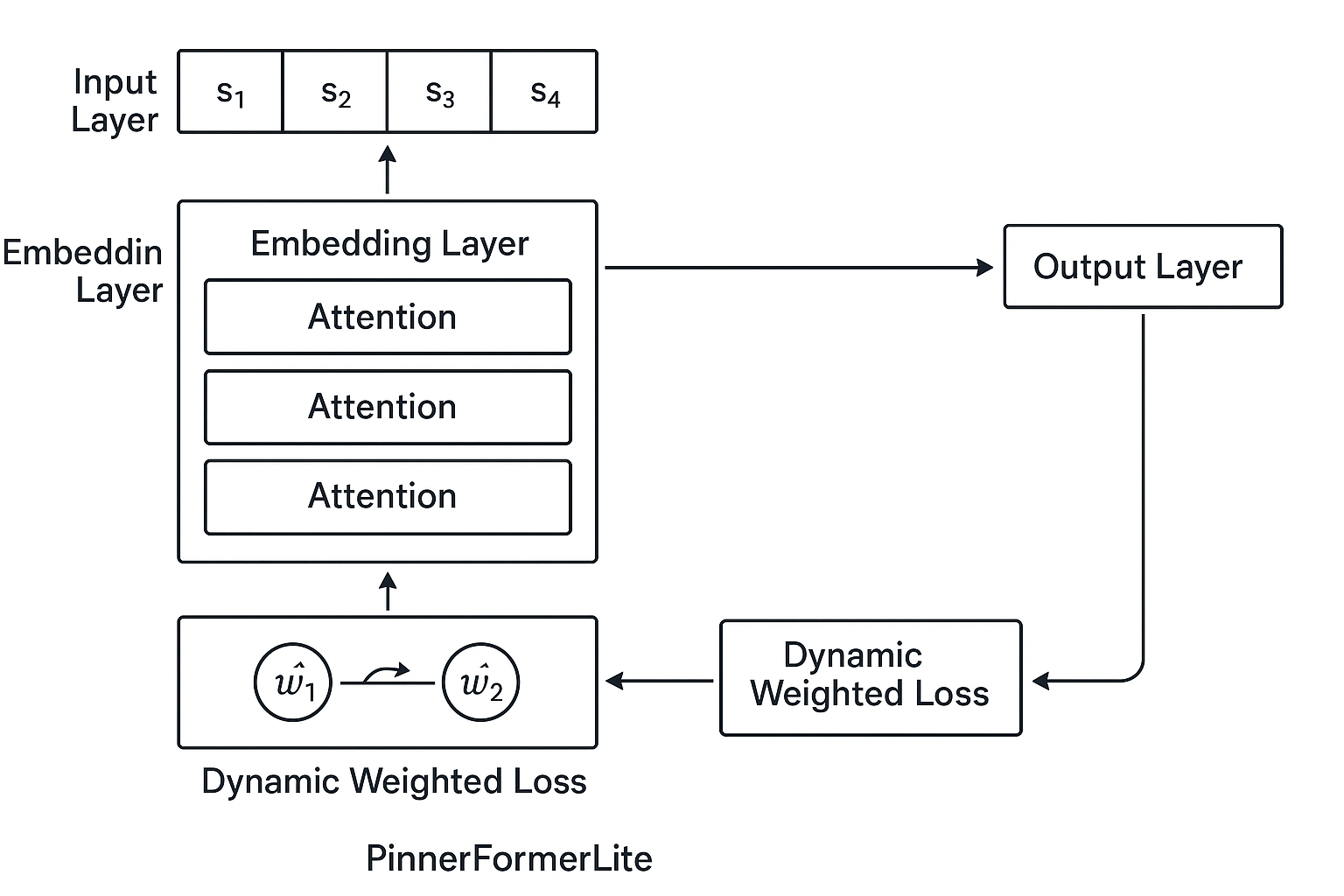
Figure 1: PinnerFormerLite Architecture with Dynamic Domain-Specific Weighting.
Theoretical Foundations
The researchers provide a rigorous theoretical analysis to support their dynamic weighting approach. The convergence and stability of the model are ensured through the exponential moving average update rule. The complexity analysis highlights the minimal overhead introduced by dynamic calculations, while bounds analysis confirms that weights are managed within a stable range, ensuring effective training without inducing instability.
Experimental Validation
Extensive empirical validation was conducted across diverse datasets including MovieLens, Amazon Electronics, Yelp Business, and LastFM Music. The results demonstrate substantial improvements in Recall@10 and NDCG@10 metrics for sparse domains under the dynamic weighting scheme compared to state-of-the-art baselines. Notably, the model achieved a 52.4% lift in Recall@10 for the sparse Film-Noir domain, illustrating its superiority in handling data sparsity.
Implications and Future Work
By successfully addressing data sparsity at the loss function level, this approach avoids the need for cumbersome domain-specific models, allowing for scalable deployment. The implications for future advancements in recommendation systems are significant, with potential extensions into multi-objective optimization frameworks that incorporate dynamic weighting schemes. Future work could explore hybrid architectures that integrate transfer learning and real-time adaptation to further enhance performance.
Conclusion
This paper presents a compelling advancement in recommendation systems through adaptive loss weighting, effectively transforming the capability of single-model architectures to cater to sparse domains. The theoretical analysis and empirical validation provide robust support for its potential to enhance recommendation accuracy across diverse applications. The adaptive approach not only improves precision but also maintains diverse recommendation outcomes, marking a significant step forward in the domain of sequential recommendations.