- The paper demonstrates that matching covariance rather than mean between synthetic and target data significantly reduces generalization error in high-dimensional linear models.
- The authors propose a covariance matching algorithm that iteratively minimizes the Frobenius norm difference using pre-trained CLIP features and PCA projection.
- Empirical results on datasets like CIFAR-10, ImageNet-100, and RxRx1 reveal that covariance alignment outperforms traditional center-based and diversity-based filtering methods.
High-dimensional Analysis of Synthetic Data Selection
The paper "High-dimensional Analysis of Synthetic Data Selection" (2510.08123) explores how synthetic data can influence the performance of classifiers, especially in high-dimensional settings. By examining linear models, the paper highlights that while covariance shifts between target and synthetic data distributions can impact generalization error, mean shifts do not. This study extends to deep neural networks and generative models, proposing that matching the covariance of synthetic and target data boosts performance across various architectures and datasets.
Theoretical Insights
Covariance vs. Mean Shift
The core finding of the research is that covariance misalignment affects generalization error, unlike mean shift. This result is underpinned by extensive theoretical analysis of linear models using high-dimensional regression. In practical terms, this means that when incorporating synthetic data for training predictive models, attention should be focused on matching covariance rather than mean.
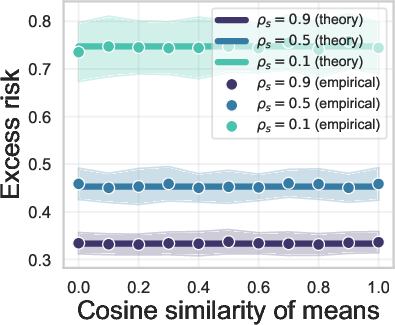
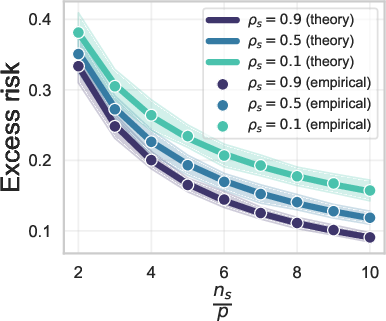
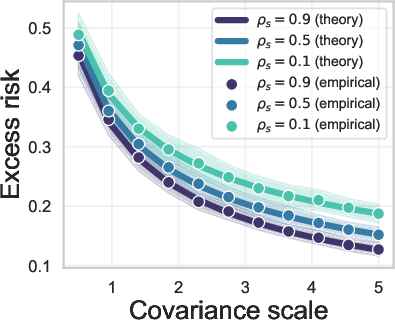
Figure 1: Aligning the means
Optimal Synthetic Data Selection
The authors introduce an optimization framework that guides synthetic data selection based on covariance alignment. Through rigorous under- and over-parameterized analyses, the paper demonstrates that optimal performance corresponds to covariance matching (Σs∝Σt), where Σs and Σt are the covariances of synthetic and target data, respectively.
Practical Implementation
Synthetic Data Selection Algorithm
The paper provides a covariance matching algorithm that iteratively selects synthetic data samples to minimize the Frobenius norm of covariance differences. This is done using pre-trained CLIP features, projected into a lower-dimensional PCA space for efficient computation.
Empirical Validation
Extensive validation across diverse datasets (e.g., CIFAR-10, ImageNet-100, RxRx1) and models (ResNets, Transformers) confirms the approach's effectiveness. These experiments demonstrate that covariance matching outperforms several baselines, including center-based and diversity-based filtering methods.


Figure 2: CLIP-based algorithms
Applicability and Implications
The implications of the research extend beyond theoretical interest, offering practical guidance for datasets requiring synthetic augmentation. By focusing on covariance, data engineers can better harness generative models to create effective synthetic datasets, potentially improving training outcomes in data-scarce applications.
Conclusion
The paper sheds light on the importance of covariance in the selection of synthetic data, challenging traditional emphasis on data closeness in terms of mean alignment. Through a mix of theoretical derivation and empirical testing, it provides a robust framework for optimizing synthetic data usage, with promising results for various machine learning applications. Future research might explore extensions to non-linear settings and complex data distributions, considering modeling shifts and other dynamic factors in synthetic data generation.