- The paper demonstrates that tuning small subnetworks (slices) in pretrained networks leverages spectral balance and task energy to improve downstream performance.
- Methodology employs block coordinate descent to dynamically update slices across layers, achieving accuracy comparable to full model fine-tuning.
- Empirical validation shows that SliceFine reduces computational overhead and matches or outperforms methods like LoRA in tasks including NLP and commonsense reasoning.
SliceFine: The Universal Winning-Slice Hypothesis for Pretrained Networks
Introduction
The paper "SliceFine: The Universal Winning-Slice Hypothesis for Pretrained Networks" presents a theoretical framework to explain why tuning small, randomly chosen subnetworks, referred to as "slices," within large pretrained models suffices for effective downstream adaptation. This concept is encapsulated in the Universal Winning-Slice Hypothesis (UWSH), which is based on two key observations: spectral balance in weight matrices and high task energy in the backbone features. These properties enable the slices to act as local winning tickets that significantly contribute to the model's performance upon fine-tuning. SliceFine, a proposed parameter-efficient fine-tuning (PEFT) method, leverages this by updating only selected slices without introducing additional parameters.
Universal Winning-Slice Hypothesis
The UWSH postulates that within a densely pretrained network, any sufficiently wide random slice of a weight matrix is a local winning ticket, capable of improving downstream task performance through its own fine-tuning. Furthermore, by tuning a small set of these slices across different layers, the model can achieve similar accuracy to full fine-tuning while modifying significantly fewer parameters. This hypothesis builds upon the spectral analysis of pretrained weight matrices, which shows that the eigenvalues are consistently distributed across different slices, ensuring comparable adaptation capacity more robustly than previous sparse network theories such as the Lottery Ticket Hypothesis.
Spectral Balance and Task Energy
Spectral balance refers to the observation that the eigenspectra of different weight matrix slices are similar, indicating uniform capacity for task-specific adjustments across slices. High task energy denotes the pretrained backbone's ability to retain task-relevant features, as indicated by the high cumulative explained variance from principal component analysis of the feature space. When these conditions hold, each slice can engage effectively with the relevant task subspace.
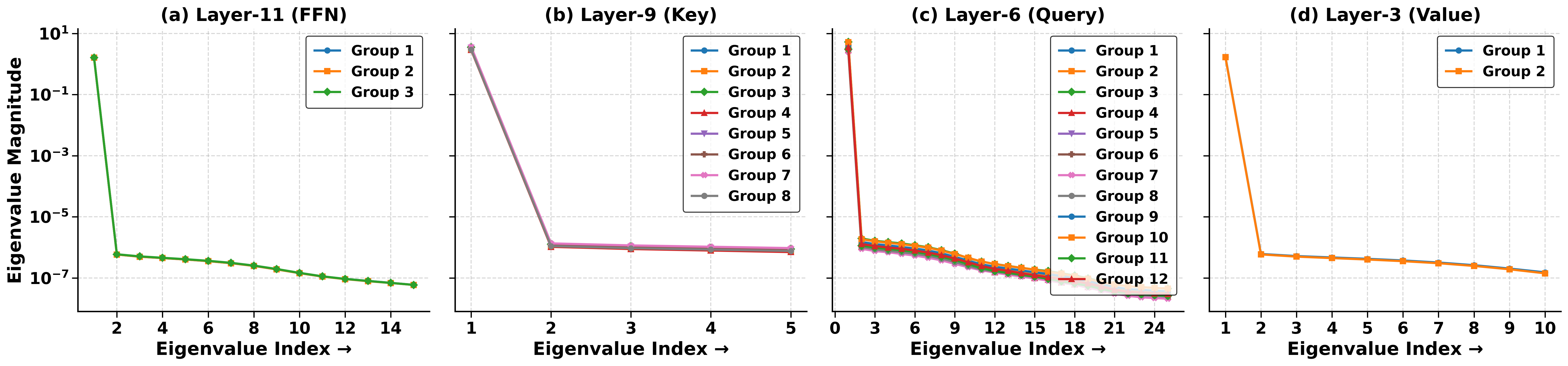
Figure 1: Eigenvalue spectra of FFN, Key, Query, and Value weight matrices from different layers of a pretrained RoBERTa-base model, demonstrating similar decay profiles and spectral balance.
SliceFine Methodology
SliceFine capitalizes on the UWSH by sequentially updating slices across layers in a specificity-efficient manner. Each slice is selected based on a preset rank, determining the number of rows or columns to be optimized. These slices dynamically shift positions during training, enabling comprehensive coverage of the parameter space without exhaustive computation. This approach is implemented through block coordinate descent, with slices being active for a fixed number of training steps before moving to a new position.
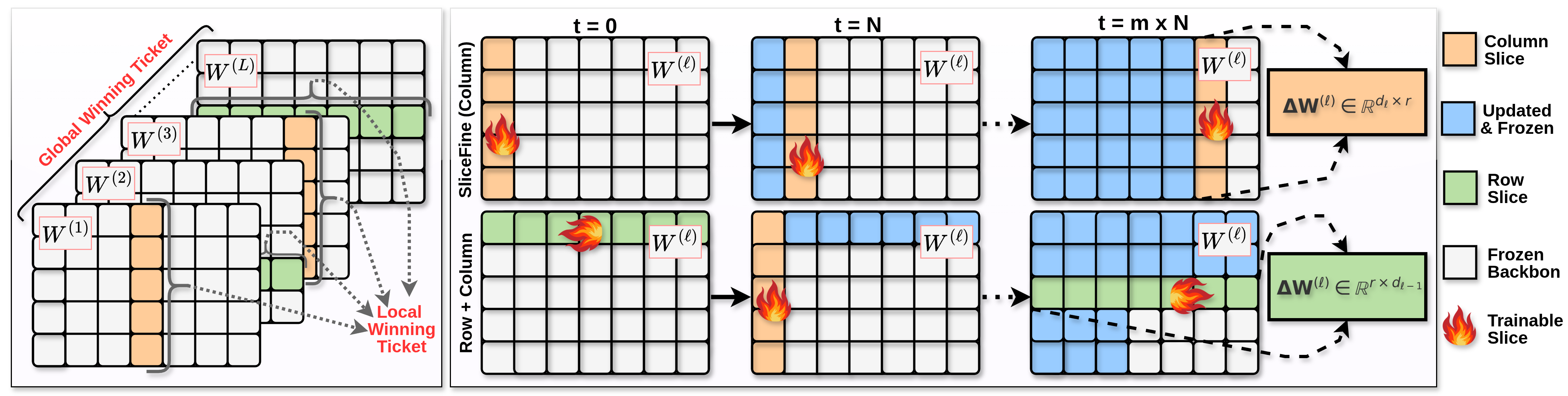
Figure 2: Illustration of the dynamic updating of slices in SliceFine, demonstrating column sweep and row-column alternation strategies.
Empirical Validation
Empirical studies across a variety of tasks, including natural language understanding, commonsense reasoning, and mathematical problem-solving, show that SliceFine matches or even outperforms existing PEFT methods such as LoRA and AdaLoRA. These results are significant given the reduction in computational resources and parameter updates required by SliceFine. Specifically, tasks with high cumulative explained variance benefit more from sparse updates, affirming the theoretical underpinnings of slice robustness.
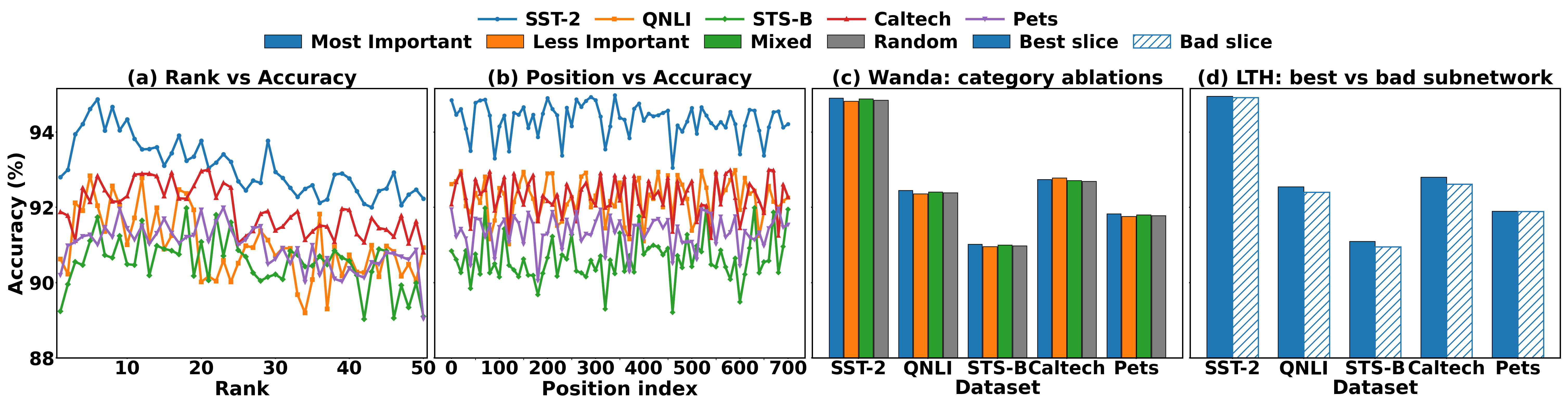
Figure 3: Demonstrating robustness and performance consistency of various slice selection strategies across tasks, underscoring the effectiveness of SliceFine's dynamic slice updates.
Conclusion
The Universal Winning-Slice Hypothesis offers profound insights into the adaptability and efficiency of pretrained networks under parameter-efficient tuning methods. By focusing on dynamically adjustable slice updates in pre-trained networks, SliceFine provides a practical and theoretically grounded approach to achieving high performance across diverse tasks with reduced fine-tuning overhead. Future work could extend these insights to further optimize slice strategies, potentially expanding the hypothesis's applicability to novel architectures and tasks.