- The paper introduces CaRT, a framework that uses hard negative counterfactuals and verbal reasoning to teach LLM agents optimal termination.
- It formulates the stopping problem as a sequential decision process in both interactive (medical diagnosis) and internal (math reasoning) settings.
- Ablation studies show that both counterfactual data and reasoning traces are essential for enhanced generalization and robustness in decision-making.
CaRT: Teaching LLM Agents to Know When They Know Enough
Introduction and Motivation
The paper addresses a critical deficiency in current LLM-based agents: the inability to reliably determine when sufficient information has been gathered to terminate reasoning or interaction. This limitation manifests as both overthinking (wasting compute and risking distraction by spurious context) and premature termination (leading to suboptimal task performance). The authors formalize the termination problem in both explicit (interactive, e.g., medical diagnosis) and implicit (internal reasoning, e.g., math problem solving) information-seeking settings, and introduce CaRT (Counterfactuals and Reasoning for Termination), a fine-tuning framework that leverages counterfactual data augmentation and explicit reasoning traces to teach LLMs to identify optimal stopping points.
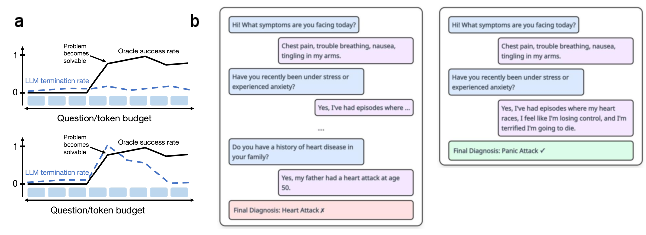
Figure 1: A schematic illustration of the termination behavior of models with and without CaRT, highlighting the improved ability to identify optimal stopping points.
The termination problem is cast as a sequential decision process, where at each step the agent must choose between continuing to seek information or terminating and producing a final answer. The objective is to maximize expected task reward, discounted by the cost of additional computation or interaction. The policy π(at∣x,z0:t,o0:t) must balance the value of further exploration against the risk of overfitting or wasted effort. The authors formalize this as a POMDP, with the optimal policy requiring accurate estimation of the value of both acquired and missing information.
The CaRT Methodology
Hard Negative Counterfactuals
A key insight is that naive SFT on termination labels is insufficient due to confounding factors (e.g., conversation length, superficial confidence cues). CaRT constructs hard negative counterfactuals by minimally perturbing successful trajectories to create near-identical contexts where the optimal action flips from terminate to continue (or vice versa). This isolates the true causal features that determine information sufficiency, breaking spurious correlations and providing a dense, contrastive learning signal.
Verbal Reasoning Traces
Each training example is augmented with a reasoning trace, generated by prompting a strong LLM to explain the rationale for the termination decision. This serves as an implicit, verbalized value function, encouraging the model to internalize the utility of both available and missing information. The reasoning traces also regularize the model, improving generalization and interpretability.
Training and Implementation
The approach is instantiated via SFT on the constructed counterfactual+reasoning dataset. In the medical setting, additional RL (GRPO) is applied with a binary reward for correct termination decisions. The method is evaluated in two domains: multi-turn medical diagnosis (explicit information seeking) and math problem solving (implicit, chain-of-thought reasoning).
Experimental Results
Medical Diagnosis
CaRT is evaluated on a dataset of GPT-4o-simulated doctor-patient conversations, with diagnostic accuracy labeled by an external reward model. The termination model is trained to decide when to stop asking questions and produce a diagnosis. CaRT outperforms both the base model and SFT baseline across all termination metrics, including free-response question success rate (FRQ SR) and optimal termination rate.
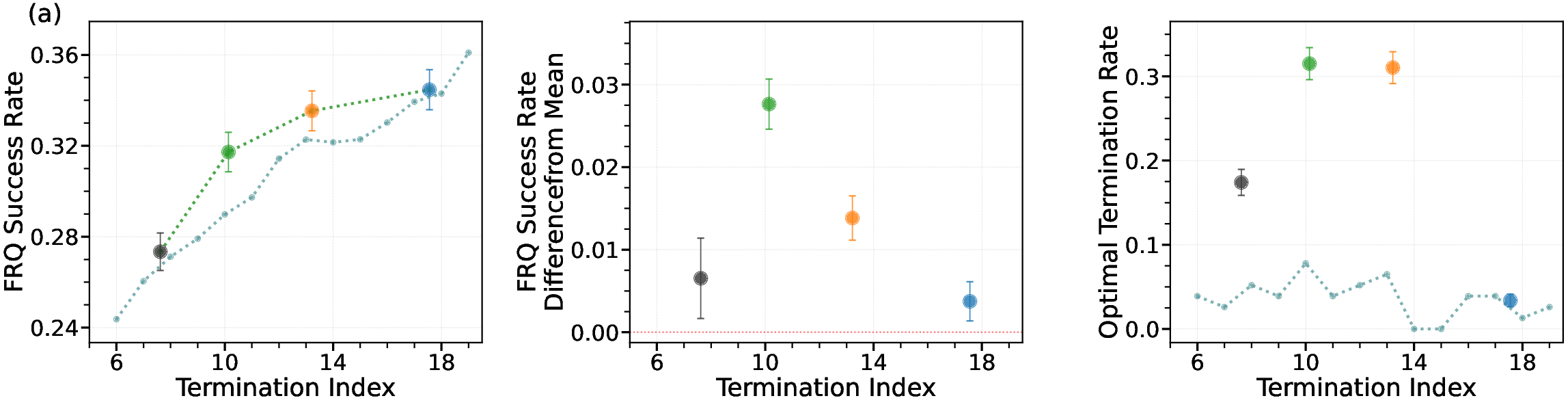
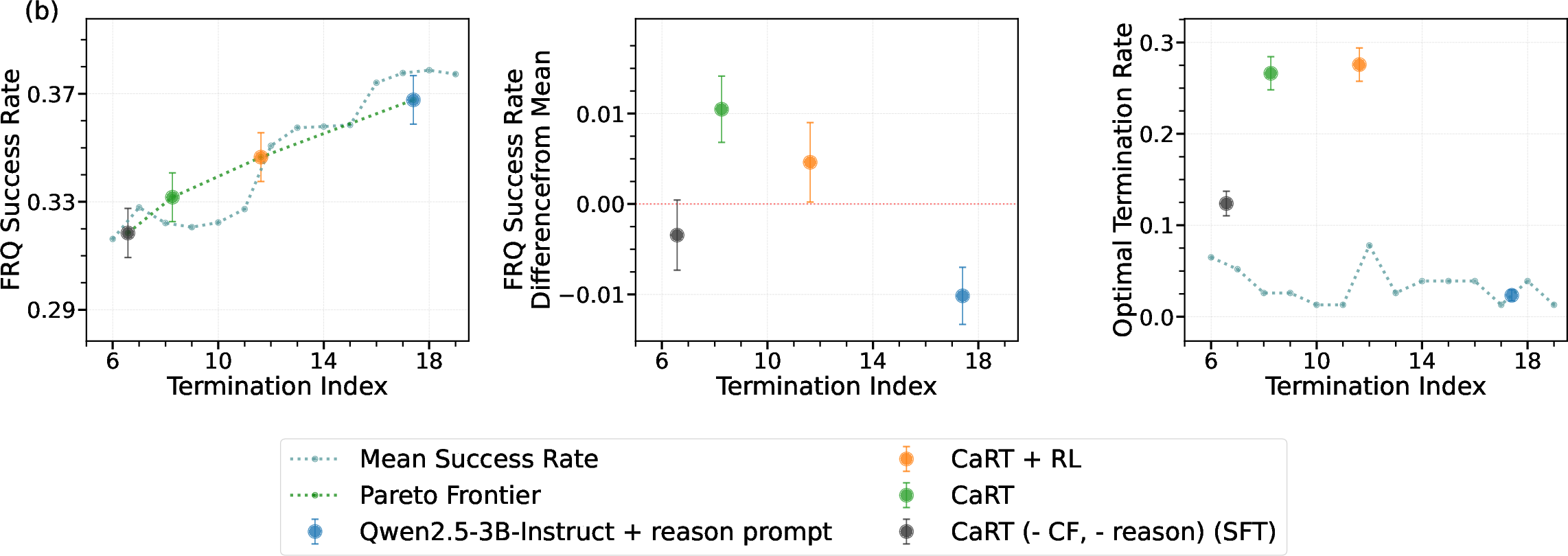
Figure 2: CaRT outperforms other termination methods for medical diagnosis, both on holdout and out-of-distribution dermatology tasks.
Notably, CaRT maintains superior performance on out-of-distribution (OOD) dermatology diagnosis tasks, whereas baselines degrade below even naive fixed-step termination. This demonstrates the robustness and generalization benefits of counterfactual and reasoning-based training.
Mathematical Reasoning
In the math domain, CaRT is trained on DeepScaleR-preview problems, with termination decisions labeled by whether stopping at a given reasoning episode yields higher success than continuing. On the AIME2025 benchmark, CaRT achieves higher FRQ SR and optimal termination alignment than both the base model and SFT, while using fewer reasoning tokens.
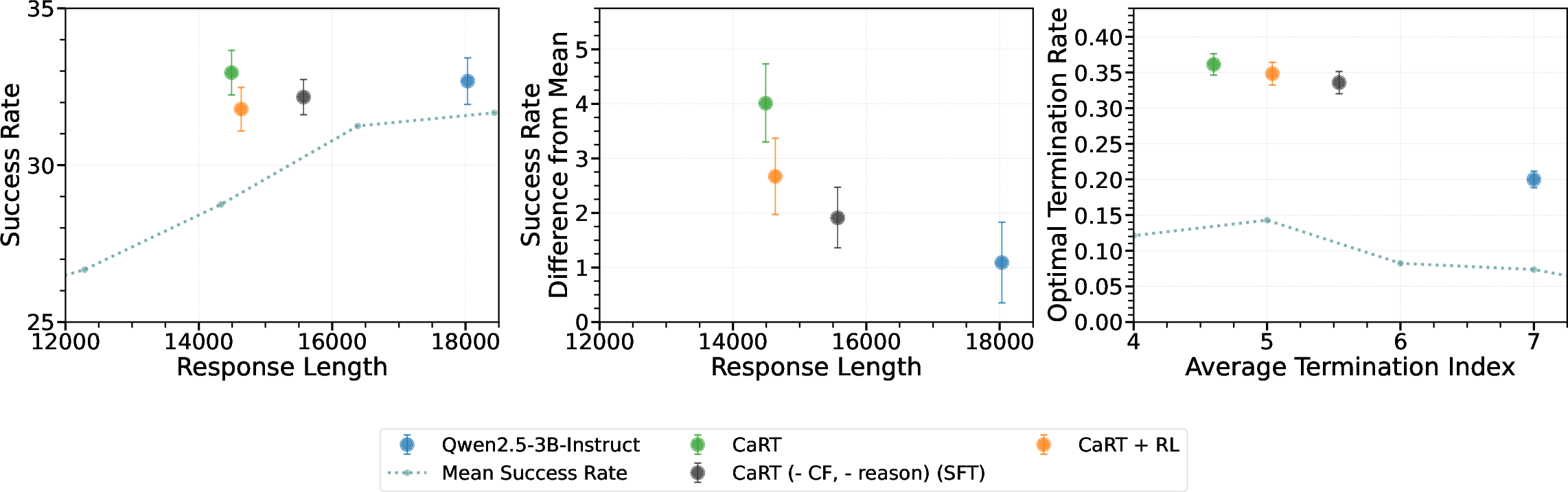
Figure 3: Termination performance on Math, showing CaRT's superiority over base and SFT models on AIME2025.
Ablation Studies
Ablations confirm that both counterfactual data and reasoning traces are essential. Removing either component degrades termination accuracy and increases overfitting. Counterfactuals are particularly important for teaching the model to recognize information sufficiency, while reasoning traces stabilize decision boundaries and improve out-of-distribution robustness.
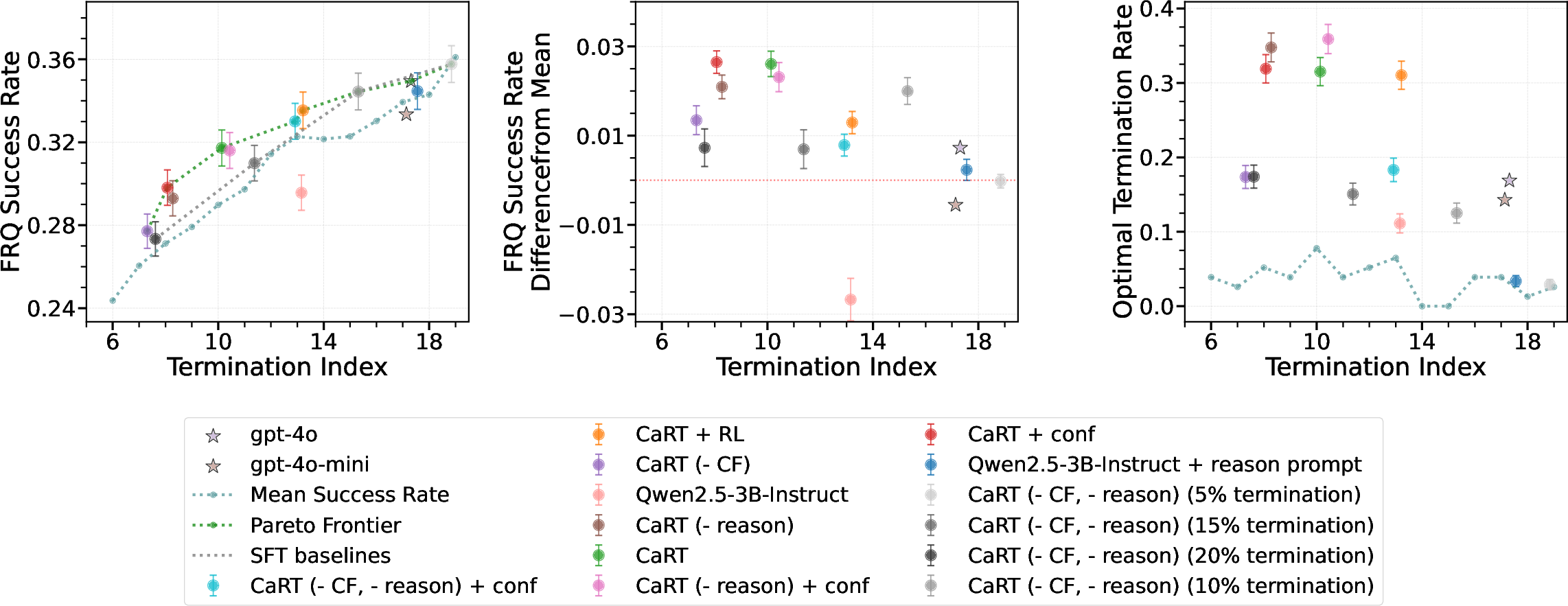
Figure 4: Ablation study on holdout data, demonstrating the necessity of both counterfactuals and reasoning for optimal termination.
Further, representation analysis shows that reasoning augmentation yields more linearly separable internal representations, facilitating better generalization.
Analysis and Implications
The results establish that off-the-shelf LLMs and standard SFT approaches are insufficient for learning robust termination policies, often defaulting to length-based heuristics or overconfident continuation. CaRT's explicit contrastive and reasoning-based supervision enables the model to internalize a form of value estimation, leading to adaptive, context-sensitive termination. The strong OOD performance and improved representation separability suggest that CaRT mitigates overfitting and enhances generalization, which is critical for deployment in real-world, safety-critical domains.
The methodology is broadly applicable to any sequential information-seeking or reasoning task where optimal stopping is nontrivial. The approach is data-efficient, as counterfactuals provide dense supervision, and the reasoning traces can be generated with minimal human effort using strong LLMs.
Future Directions
Several extensions are proposed:
- Joint Exploration and Termination: Integrating CaRT with exploration policy optimization, enabling end-to-end learning of both what information to seek and when to stop.
- Explicit Value Estimation: Augmenting CaRT with explicit value or uncertainty modeling to further improve robustness to distribution shift.
- Broader Domains: Applying CaRT to other domains such as tool use, open-ended dialogue, or embodied agents.
Conclusion
CaRT provides a principled and empirically validated framework for teaching LLM agents to know when they know enough. By leveraging hard negative counterfactuals and explicit reasoning traces, CaRT enables LLMs to learn robust, generalizable termination policies that outperform standard baselines in both interactive and internal reasoning settings. The approach addresses a fundamental challenge in LLM deployment and opens avenues for more efficient, reliable, and interpretable AI agents.