- The paper shows that LSA-based Transformers have inherent representational limits for capturing temporal dependencies in AR(p) processes.
- It quantifies a positive finite-sample excess risk and demonstrates that stacking layers reduces but never eliminates the gap relative to linear predictors.
- The research reveals that chain-of-thought inference leads to exponential error compounding, validating classical models as a superior baseline.
Theoretical and Empirical Limits of Transformers for In-Context Time Series Forecasting
Introduction and Motivation
This paper provides a rigorous theoretical and empirical analysis of why Transformer architectures, particularly those based on Linear Self-Attention (LSA), fail to outperform classical linear models in time series forecasting (TSF) tasks, even when equipped with large parameter counts and deep architectures. The study is grounded in the context of autoregressive (AR(p)) processes, which are canonical in time series analysis, and leverages the framework of In-Context Learning (ICL) to dissect the representational and inferential limitations of Transformers in this domain.
Theoretical Analysis: Representational Constraints
The core theoretical contribution is the formal demonstration that LSA-based Transformers are fundamentally limited in their ability to represent and exploit temporal dependencies in AR(p) data. The analysis proceeds by Hankelizing the input sequence, which encodes the autoregressive structure and obviates the need for explicit positional encodings. The LSA mechanism, when applied to this Hankelized input, is shown to induce a cubic feature space that, in the limit of infinite context, collapses to the span of the last p lags—the same information exploited by classical linear regression.
This is formalized via a series of propositions and lemmas:
- Feature-Space Compression: One-layer LSA is a linear functional over a cubic feature space, but this space is strictly coarser than the full context, and cannot unlock predictive signal beyond the last p lags.
- Asymptotic Equivalence: As context length n→∞, the LSA features concentrate onto the last p lags, and the optimal LSA readout asymptotically matches the linear predictor.
- Strict Finite-Sample Gap: For any finite n, there exists a strictly positive excess risk (in expected MSE) for LSA relative to the optimal linear predictor, quantified by a Schur-complement gap that vanishes at a rate no faster than $1/n$.
Quantitative Gap and Scaling Behavior
The paper provides explicit closed-form characterizations of the excess risk incurred by LSA, both in the Gaussian AR(p) case and for general linear stationary processes. The gap is shown to be robust to non-Gaussianity, with the $1/n$ rate persisting and the leading constant determined by higher-order cumulants.
Stacking additional LSA layers yields monotone improvements in risk, but the linear regression baseline remains unbeatable at finite n. The analysis is extended to multi-layer LSA via convex relaxation and Moore–Penrose pseudoinverse techniques, confirming that depth helps but does not close the fundamental gap.
Chain-of-Thought Rollout: Error Compounding
A critical practical insight is the behavior of Transformers under Chain-of-Thought (CoT) style inference, where model predictions are iteratively fed back as inputs for future steps. The paper proves that, in contrast to language modeling tasks where CoT can enhance reasoning, in TSF CoT leads to exponential error compounding and collapse of predictions to the mean. Even the Bayes-optimal linear predictor exhibits this collapse, but LSA-based models fail earlier and more severely.
Empirical Validation
The theoretical findings are corroborated by extensive experiments on synthetic AR(p) data:
- Teacher-Forcing vs. CoT: Under teacher-forcing, LSA tracks the AR(p) process but never surpasses the OLS baseline in MSE. Under CoT rollout, both methods collapse to the mean, with LSA failing earlier.
- Scaling Experiments: Increasing context length and stacking more LSA layers improves performance but never closes the gap to OLS. Gains from additional layers saturate at the linear baseline.
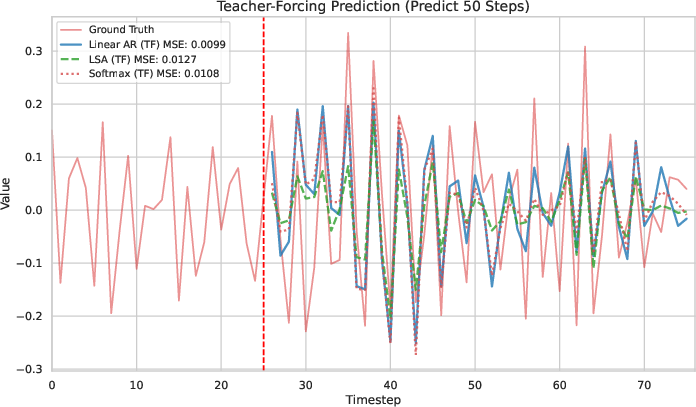
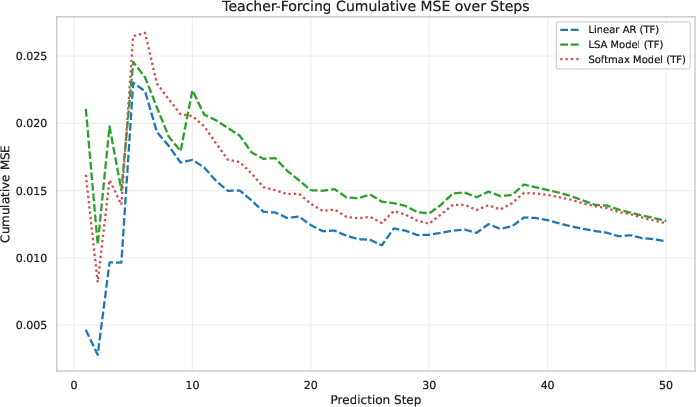
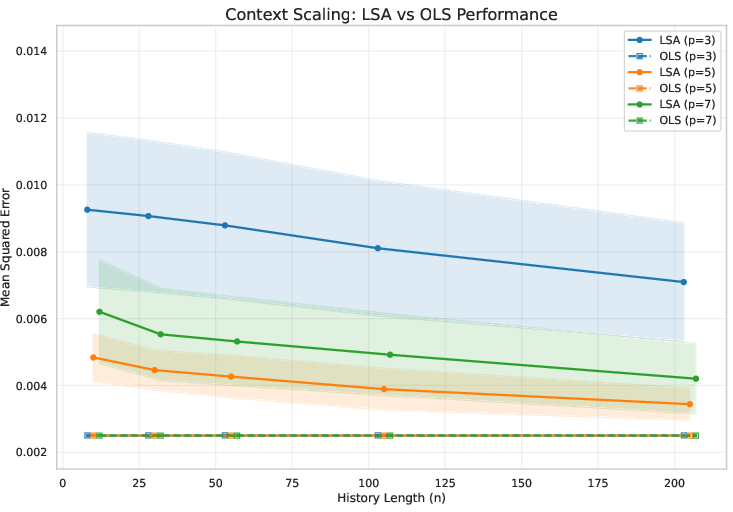
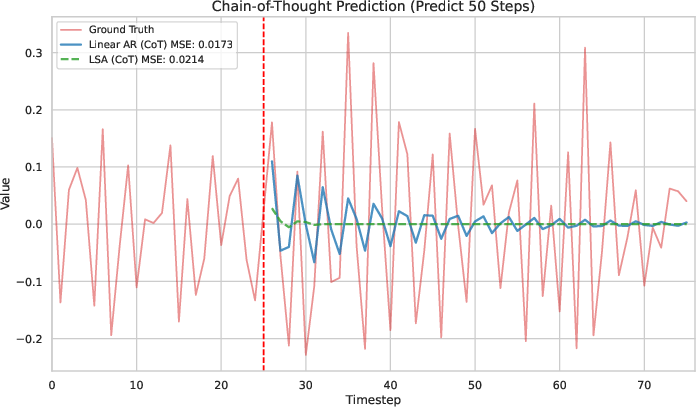
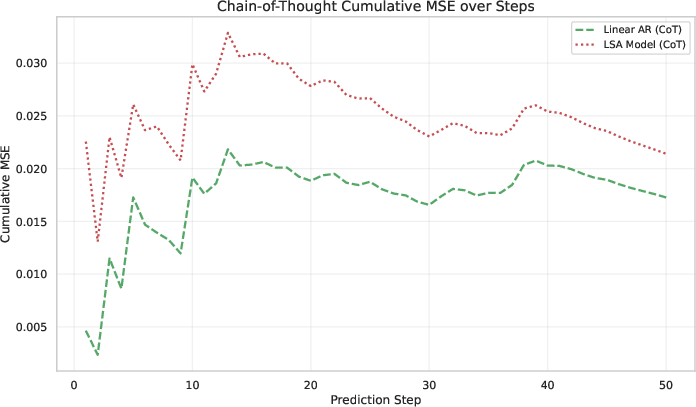
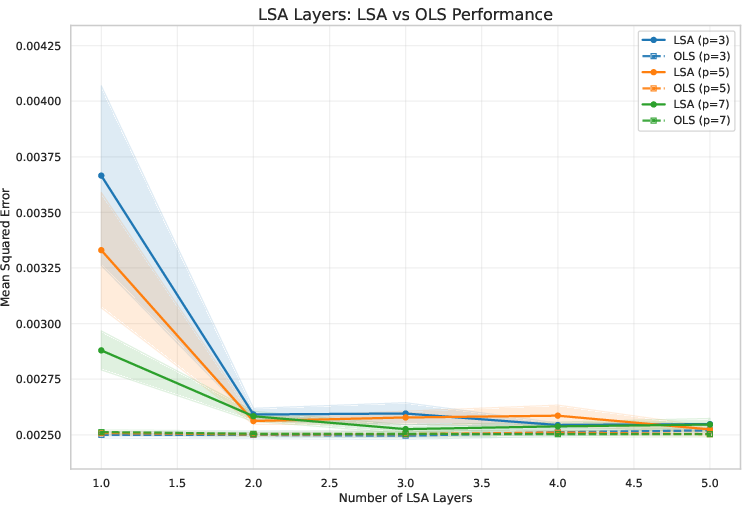
Figure 1: Experimental results. (a--b) Predictions under Teacher-Forcing (TF) and Chain-of-Thought (CoT). (c--d) Cumulative MSE for TF and CoT rollouts. (e--f) Scaling experiments varying the history length and the number of LSA layers. Overall, LSA tracks AR(p) but never surpasses the OLS baseline, confirming its representational limits.
A further comparison between LSA and Softmax Attention shows that Softmax Attention is slightly better than LSA, but neither surpasses the OLS baseline.
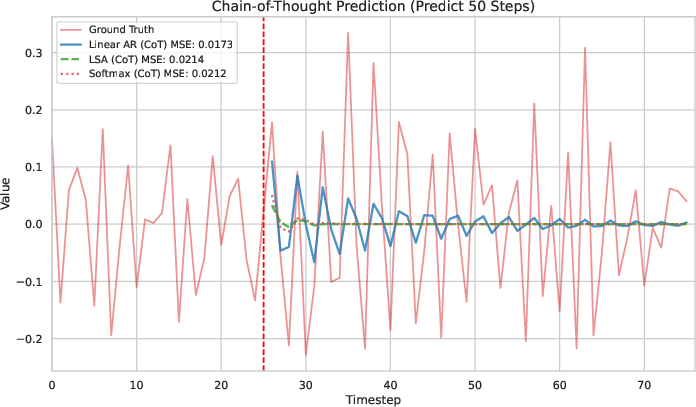
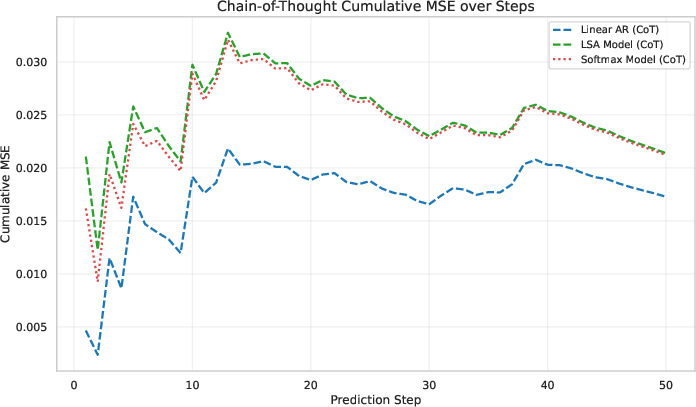
Figure 2: Experimental results on comparison of LSA and Softmax Attention. (a--b) Predictions under Teacher-Forcing (TF) and Chain-of-Thought (CoT). (c--d) Cumulative MSE for TF and CoT rollouts. Overall, both LSA and Softmax Attention tracks AR(p) but never surpass the OLS baseline. Moreover, Softmax Attention is slightly better than LSA.
Architectural and Domain-Specific Implications
The analysis highlights that the attention mechanism, while powerful for compressing and aggregating long-range dependencies in language modeling, is misaligned with the local, position-specific dependencies that dominate time series with low-order dynamics. The fixed contextual weights of attention obscure direct temporal relationships, leading to representational inefficiency.
The role of other architectural components, such as Softmax attention, multi-head aggregation, and feedforward MLPs, is discussed. While these may enhance expressivity, they do not fundamentally overcome the limitations identified for TSF. The findings suggest that alternative architectures—such as state-space models or frequency-domain approaches—may be better suited for time series tasks.
Practical and Theoretical Implications
- Model Selection: For TSF tasks with pronounced linear structure, classical linear models remain the gold standard, and the use of complex Transformer-based architectures should be critically evaluated.
- Pretraining and Transfer: Pretraining on uncorrelated multivariate time series is unlikely to yield useful shared representations, and the representational gap persists in more general linear stationary processes.
- Future Directions: Theoretical exploration of optimization dynamics, real-world complexities, and alternative generative modeling paradigms (e.g., diffusion models, state-space models) is warranted.
Conclusion
The paper establishes that, for AR(p) time series, LSA-based Transformers cannot outperform optimal linear predictors, with a strictly positive excess risk at finite context lengths and exponential error compounding under CoT inference. These results clarify the inherent limits of attention mechanisms in TSF and underscore the need for architectures that are better aligned with the temporal structure of time series data. The work provides a foundation for future research into more effective forecasting models and calls for deeper theoretical scrutiny of the direct application of sophisticated architectures to TSF.