- The paper reveals that subtle implementation details, like per-series embeddings, can significantly enhance forecasting accuracy.
- It demonstrates that hybrid models, which blend global and local parameterization, outperform pure global models when handling diverse data structures.
- The study advocates for standardized benchmarking with a forecasting model card to ensure reproducibility and clear performance comparisons.
Critical Factors in Deep Learning Architectures for Time Series Forecasting
Introduction
The proliferation of deep learning approaches for time series forecasting has been accompanied by substantial architectural innovation and an expanding empirical literature. However, empirical results in this field are frequently contradictory, and benchmarking practices often conflate the impact of architectural advances and implementation details. The paper "What Matters in Deep Learning for Time Series Forecasting?" (2512.22702) presents a comprehensive analysis of four major design dimensions in forecasting architectures, demonstrating that various overlooked implementation choices—rather than novel modules or sequence modeling operators—often drive reported improvements. This essay elucidates the core arguments, results, and implications of the paper, focusing on rigorous disentanglement of architectural and experimental confounders and presenting a nuanced perspective on true progress in deep time series forecasting.
Design Dimensions in Forecasting Architectures
The authors systematically dissect time series forecasting architectures along four axes: model configuration (local, global, or hybrid parameterization), preprocessing and exogenous variable usage, temporal processing mechanisms, and spatial (inter-series) processing. Empirical and theoretical insights reveal that seemingly innocuous implementation differences—such as per-series parameter embeddings, window length, or standardization routines—will often have a greater impact on forecasting accuracy than changes in sequence modeling layers themselves.
Model Configuration: Global, Local, and Hybrid Structures
A critical distinction is made between local models (fit per time series), global models (shared parameters across series), and hybrid models (shared core with local embeddings or parameters). The paper demonstrates that benchmarking conflates these paradigms—in some networks, a shift from a global to a hybrid approach via local embeddings leads to substantial error reduction, yet this alteration is often undocumented or described as an implementation detail. Notably, the empirical results reveal that hybrid models systematically outperform pure global models when data contain both shared and series-specific structures, and in various public datasets, this factor outweighs the impact of the specific temporal operator.

Figure 1: Block diagram of the reference architectures, illustrating modular separation between preprocessing, temporal, and spatial components.
Standardization of Preprocessing and Exogenous Variables
Preprocessing choices—such as inclusion of exogenous covariates or per-series normalization—are inconsistently documented and implemented across comparisons. The authors empirically show that access to exogenous features induces large performance swings; for example, adding calendar covariates improves MSE by over 10% in certain benchmarks, regardless of architecture. The absence of input standardization is a confounder that hinders fair attribution of performance improvements.
Temporal Processing: Simplicity Versus Complexity
Recent literature is dominated by architectures employing sophisticated temporal modeling layers: Transformers with attention, deep MLPs, TCNs, hierarchical or pyramidal encodings, and patch-based mixers. The analysis reveals a counterintuitive finding: after careful control for model configuration and preprocessing, simple architectures (e.g., MLPs, TCNs, or even DLinear) often match or surpass the performance of state-of-the-art models on widely-used benchmarks. This challenges the narrative that increasingly complex sequence models offer consistent gains in practical settings.
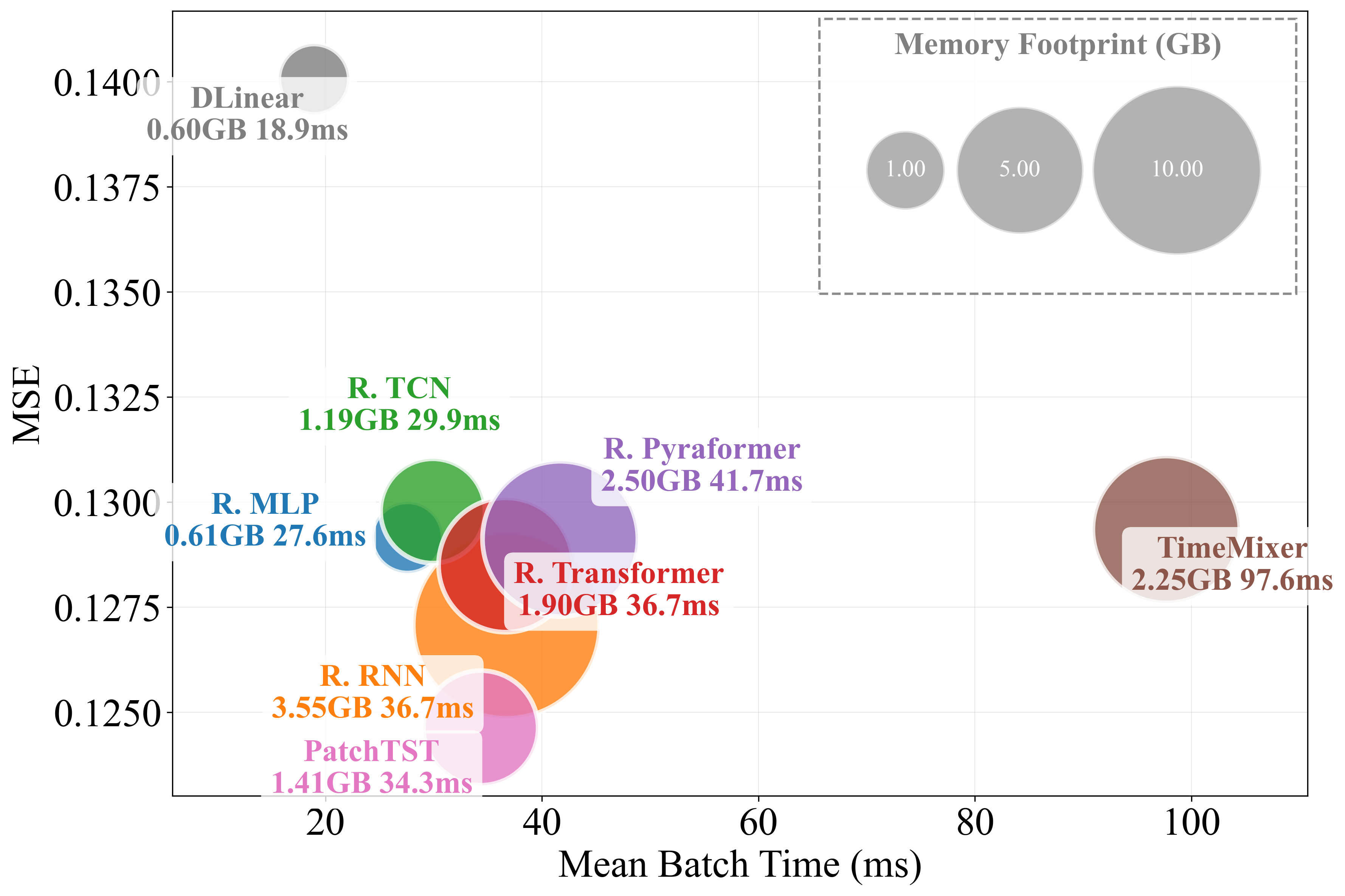
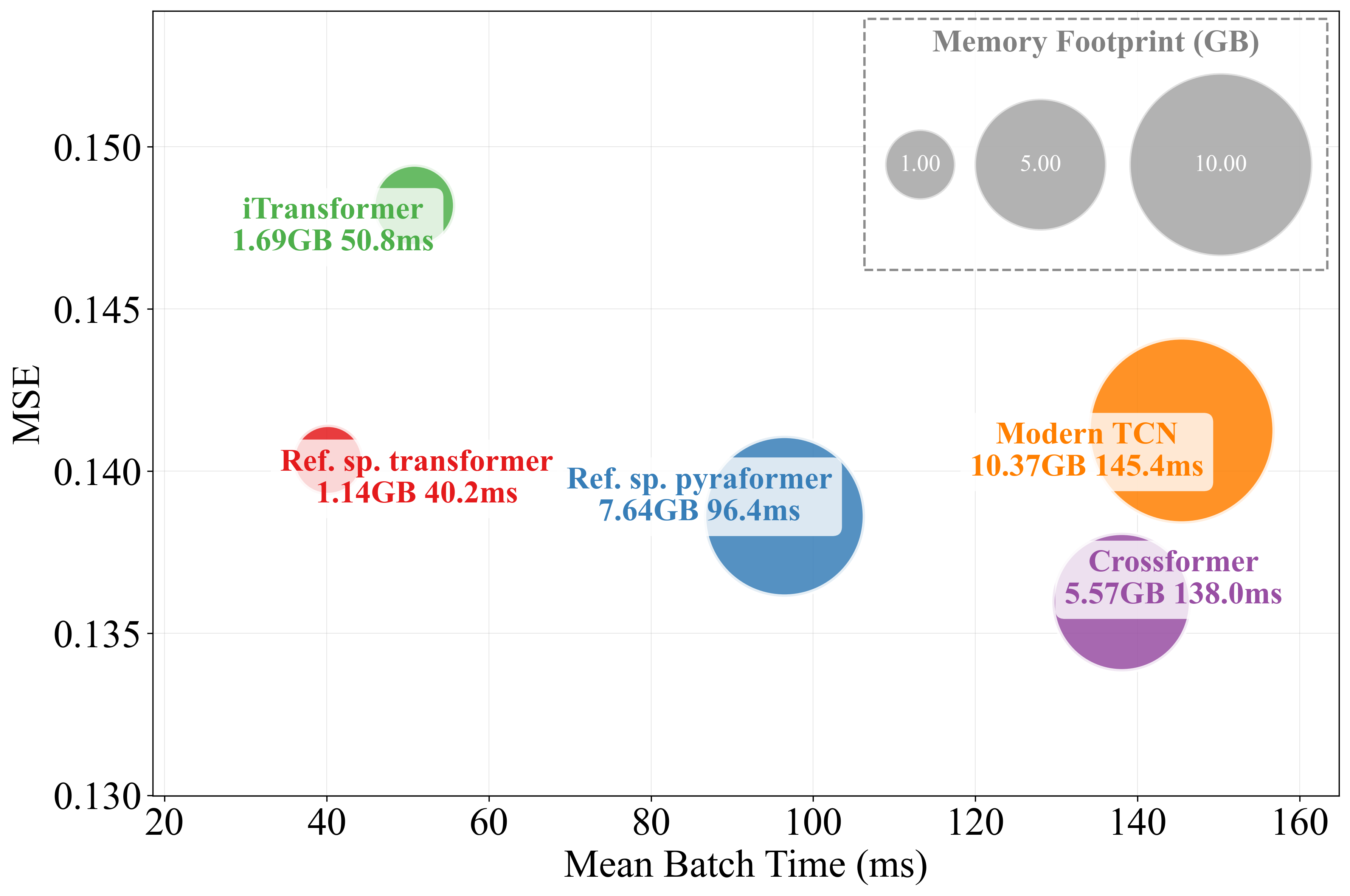
Figure 2: Models not including spatial processing, focusing exclusively on temporal modules.
Spatial Processing: Inter-Series Dependence and Its Limitations
Modeling spatial (inter-series) dependencies via attention or other message-passing modules has been posited as crucial for multivariate forecasting. The paper’s controlled ablation study, however, finds that the removal of spatial attention either has no effect or improves forecasting outcomes in long-horizon regimes for standard benchmarks. For example, iTransformer loses little or no accuracy when its space-attention module is replaced by a trivial feedforward layer. This observation highlights that the utility of explicit inter-series modeling is nuanced and highly context-dependent.
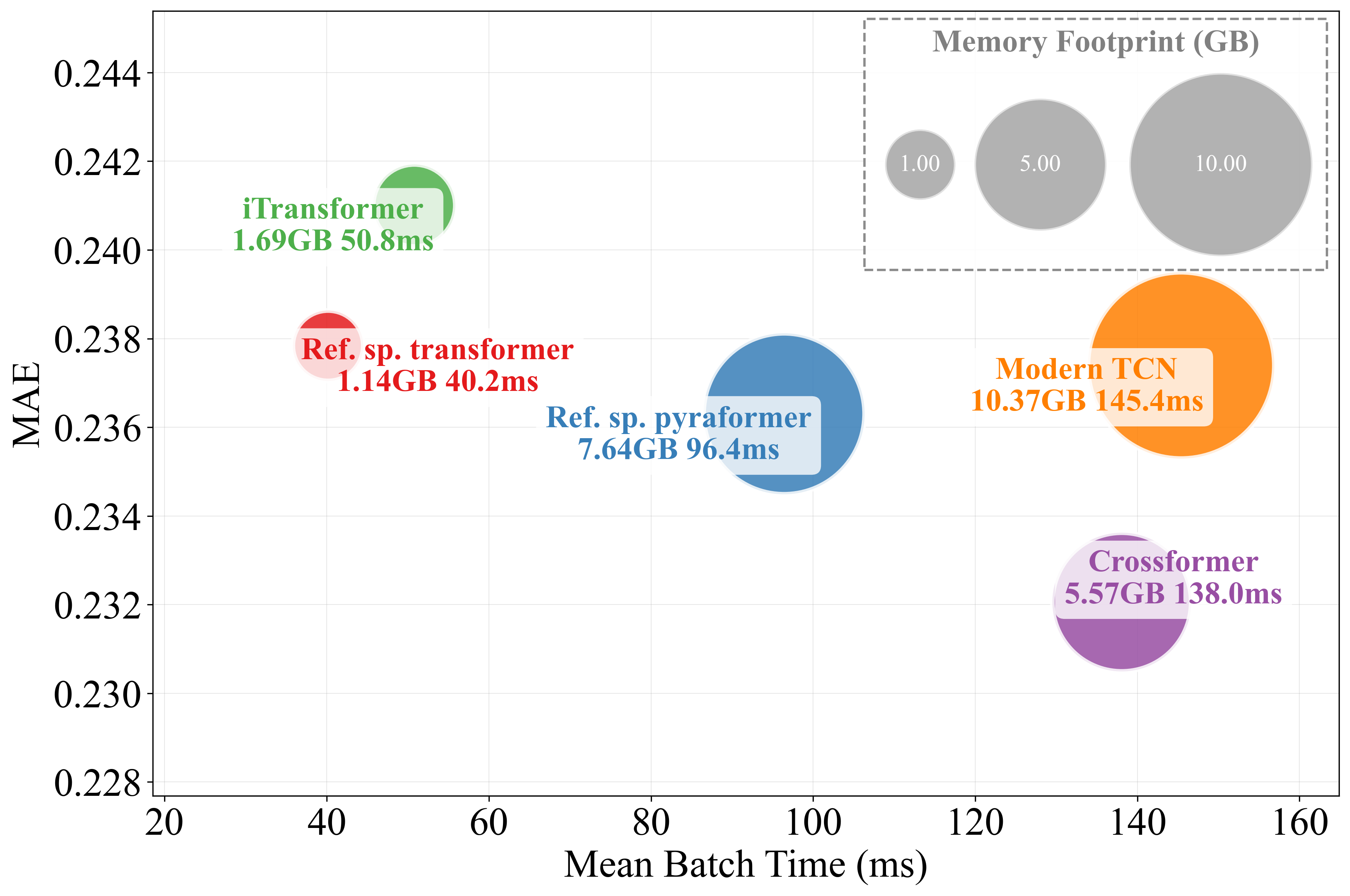
Figure 3: MAE and MSE performance versus mean batch time for models including spatial processing; circle size indicates memory consumption.
Efficient Architecture Design and Computational Profiling
The work supplementally profiles models with regard to training time and memory. Simple temporal models—MLPs or TCNs—are found to deliver attractive trade-offs between computational efficiency and predictive power, with models like PatchTST also exhibiting favorable scaling for large input windows.
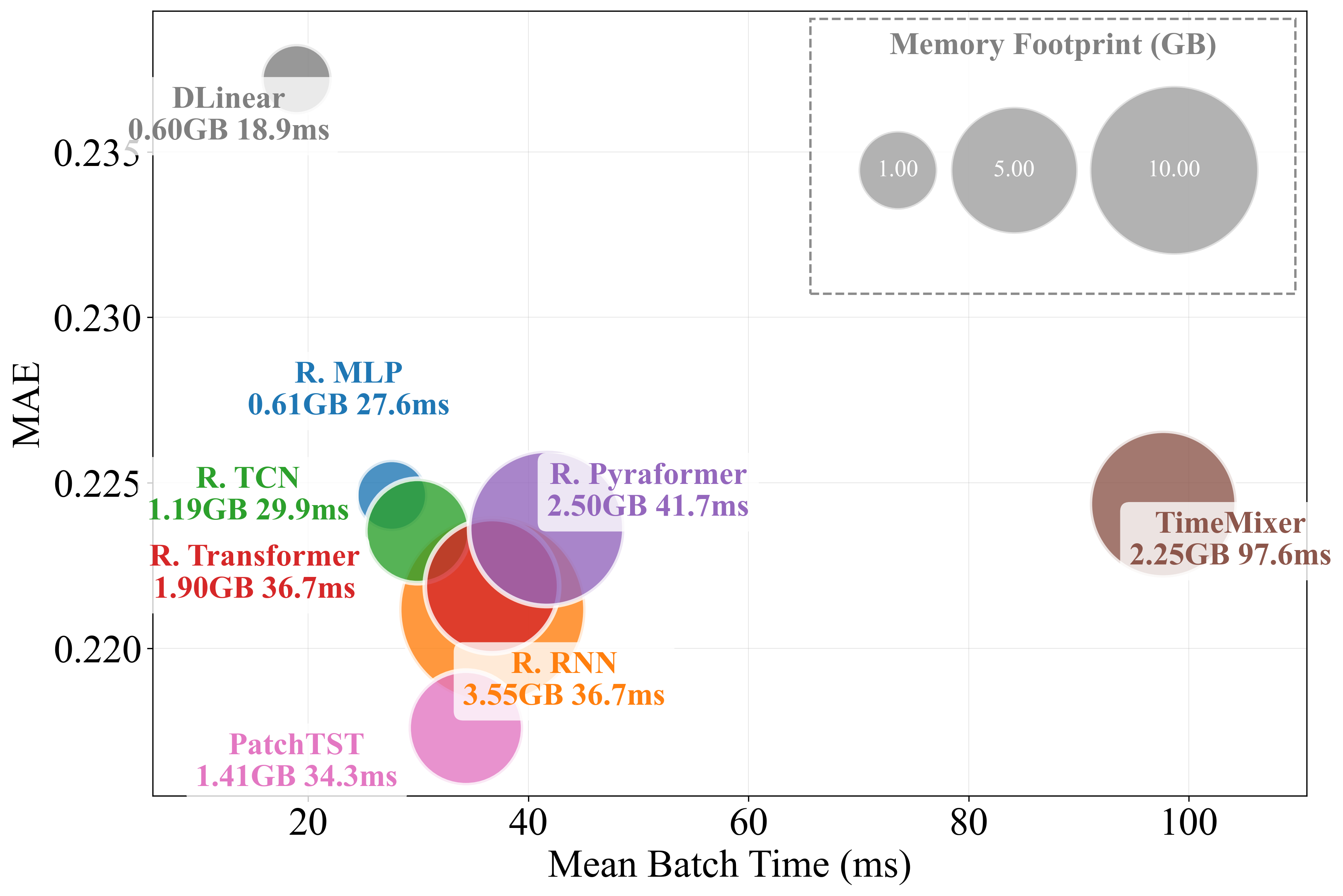
Figure 4: MAE and MSE performance versus mean batch time for models not including spatial processing, for a large batch size. Circle size encodes memory utilization.
Reproducibility, Benchmarking, and the Model Card Framework
The empirical ambiguities identified in the literature are traced in part to inconsistent benchmarking, lack of standardized covariate inclusion, and incomplete reporting of model parameterization. To address this, the authors propose a “forecasting model card” template, capturing core configuration, preprocessing, temporal and spatial operators, and scalability metrics—intended to ensure transparent, reproducible, and meaningful empirical comparisons. Adoption of such structured reporting would elevate the field’s methodological rigor.
Implications and Outlook
The findings have several important implications:
- Benchmark design and reporting must control for all design dimensions; future progress requires ablation and standardization across configuration, preprocessing, and temporal/spatial modules.
- Overinterpretation of marginal improvements in accuracy on benchmarks should be cautioned against unless the underlying model specification is validated to be fully comparable.
- Architectural simplicity is often sufficient for high-accuracy forecasting in canonical benchmarks, suggesting opportunity to reconsider the emphasis on increasingly complex operators without domain-specific justification.
- Theoretically, the results suggest that foundational questions about the inductive biases underlying global, local, and hybrid models remain unresolved, and practical progress will require explicit attention to these aspects rather than further operator proliferation alone.
- In applied AI, model selection should focus on data structure, exogenous signal availability, and computational budget, rather than assuming universal benefit from advanced sequence mechanisms.
Conclusion
The paper "What Matters in Deep Learning for Time Series Forecasting?" (2512.22702) provides a rigorous examination of the factors that produce progress—or the illusion thereof—in deep time series modeling. By decomposing performance gains into four major design dimensions and offering strong empirical evidence that proper model specification and experimental controls dominate over architectural innovation per se, the authors prompt a re-evaluation of current benchmarking and publication practices. The call to ground progress on clear, transparent, and standardized experimental design is foundational, and is likely to shape methodological development in time series forecasting and adjacent domains moving forward.