- The paper presents a method to convert complex customer support documents into an Intent, Context, and Action (ICA) format that improves LLM comprehension and reasoning.
- It outlines a process for generating synthetic training data to fine-tune smaller, open-source LLMs, thereby reducing latency and manual processing requirements.
- Experimental results demonstrate that using the ICA format with chain-of-thought reasoning significantly enhances model accuracy and operational efficiency.
LLM-Friendly Knowledge Representation for Customer Support
The study presents an approach that aims to improve the efficiency of customer support services by integrating LLMs with a practical framework designed to comprehend complex workflows of Airbnb operations. This is achieved by transforming policy and workflow representations into an LLM-friendly format termed Intent, Context, and Action (ICA), and generating synthetic data for model fine-tuning.
Introduction and Background
The paper discusses the challenges inherent in deploying LLMs for customer support, primarily due to the complexity and inconsistency of internal policy documents. Airbnb customer support is particularly challenging due to its domain-specific knowledge requirements, lengthy documents full of jargon, and workflows that are not easily interpretable by LLMs without significant preprocessing.
The paper identifies three main challenges:
- The complexity of internal knowledge, which is not naturally comprehensible by LLMs.
- The limitations of larger LLMs concerning latency and cost, both crucial in enterprise applications.
- The difficulty in creating training data due to the implicit nature of the operational knowledge, which is not always documented.
To address these challenges, the paper introduces an end-to-end solution for customer support automation that focuses on two primary innovations: converting business knowledge into a structured ICA format and fine-tuning LLMs using synthetic data methods.
The ICA format is proposed to convert complex support documents into structured knowledge that LLMs can efficiently process. This involves breaking down workflows into easily interpretable pseudocode that describes the intent behind tasks, the required context, and the actions to be taken (Figure 1).

Figure 1: Converting workflows in one document from original (rich text) format to the ICA format.
The ICA transformation process is depicted as a critical step for enhancing LLM interpretability and reasoning capabilities. The approach simplifies the content, making it more digestible for LLMs, thereby improving their ability to execute tasks based on the business logic defined in policy documents.

Figure 2: Our solution includes: 1) Transforming the workflow into ICA format, thereby enhancing the interpretive abilities of LLMs. 2) Online prediction: Retrieving relevant ICA candidates by comparing the user query and "Intent" part of the ICAs in the knowledge base; Retrieving necessary contextual data from backbend APIs; Utilizing LLMs to generate the action to take 3) Offline training: Addressing the scarcity of training data by employing synthetic methods to create the necessary data. We then apply Supervised Fine-Tuning (SFT) to train the open-source LLMs.
Additionally, the paper discusses a method for synthetic data generation, which reduces the need for extensive human-labeled datasets. This involves using synthetic rationales and synthetic decision tree constructions, which allow the production of diverse training examples (Figure 3).
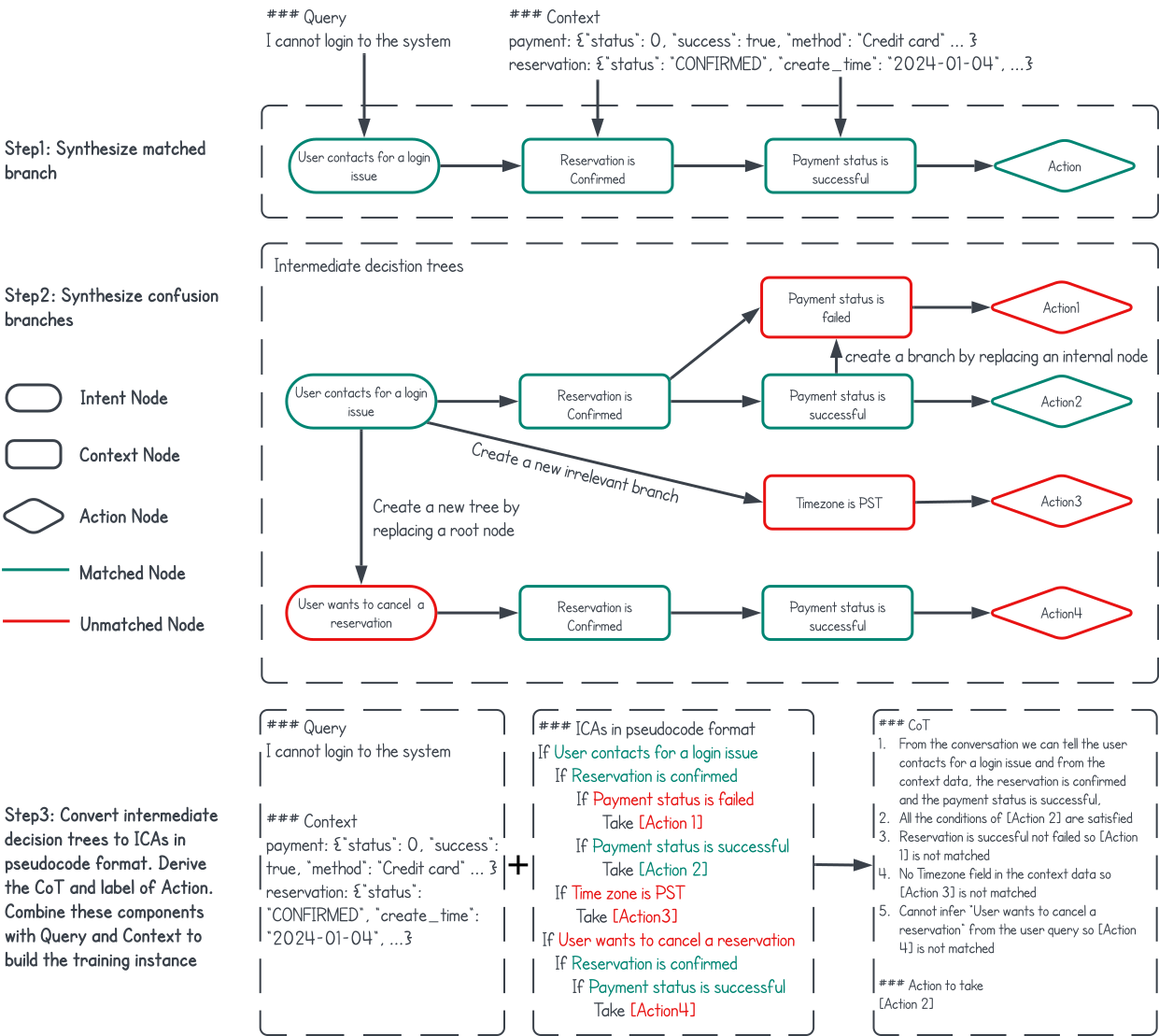
Figure 3: Three steps of generating synthetic training data: 1) Sample user query and context data randomly to establish a matched branch. 2) Incorporating additional divergent branches to construct the decision trees. 3) Developing pseudocode, detailing the reasoning process, and deriving the label from the trees, then integrating these components to assemble the training dataset.
Experimental Verifications
The experimentation process focused on evaluating the effectiveness of the proposed ICA format and synthetic data generation on model performance. The study demonstrates that using the ICA format, along with Chain-of-Thought (CoT) reasoning, significantly increases model accuracy across various LLMs, especially when compared to rich text formats (Table 1). The use of synthetic data to fine-tune smaller, open-source LLMs also notably enhances the models' speed and efficiency, reducing latency and manual processing times in real-world applications (Table 2).
Conclusion
The proposed framework for LLM-friendly knowledge representation has shown significant potential in enhancing customer support services by restructuring internal knowledge for better LLM comprehension and reasoning. This method not only allows for improved accuracy and reduced processing times but also provides a cost-effective solution for model fine-tuning using synthetic data. The implications of this research could extend to other domains, suggesting potential for reformulation of domain-specific knowledge in fields such as legal and finance, indicating a broad applicability beyond customer support.