- The paper introduces LATTICE, a zero-shot hierarchical retrieval framework where LLMs steer semantic tree traversal for efficient, reasoning-driven search.
- It employs a two-stage process with offline semantic tree construction using both bottom-up and top-down clustering, and online calibrated best-first LLM-guided traversal.
- Experimental results show improved nDCG@10 and Recall@100 metrics over standard methods with logarithmic search complexity, though challenges remain for dynamic corpora.
LLM-guided Hierarchical Retrieval: An Expert Review
Introduction
The work "LLM-guided Hierarchical Retrieval" (2510.13217) introduces LATTICE, a hierarchical retrieval framework where LLMs act as central traversal agents to navigate semantically structured document corpora. LATTICE directly leverages the reasoning capabilities of LLMs to replace standard embedding-based or pipeline IR paradigms, addressing inherent limitations of retrieve-then-rerank and generative approaches. The core contribution is a training-free, zero-shot algorithm that organizes unstructured text corpora into hierarchical semantic trees, enabling logarithmic search complexity with calibrated LLM relevance signal propagation, and resulting in robust, efficient retrieval for reasoning-intensive queries.
Framework Overview
LATTICE's architecture is a two-stage process:
- Offline: Corpus Structuring via Semantic Trees The document corpus is organized as a semantic hierarchy. Two LLM-driven strategies are explored: bottom-up agglomerative clustering using embeddings and summaries, and top-down divisive clustering with multi-level LLM-generated summaries.
- Online: LLM-guided Tree Traversal
At query time, a search LLM executes a best-first traversal of the tree, making decisions at each node by evaluating local candidate clusters with globally calibrated path relevance scores. Score calibration compensates for the inherent noise and context dependency in LLM outputs, ensuring scores are comparable across disparate branches and depths.

Figure 1: LATTICE consists of offline construction of a semantic tree and online best-first LLM-guided traversal with calibrated path relevance.
This approach leads to a traversal cost logarithmic in corpus size, a significant improvement over naive approaches for large-scale corpora, while maintaining high relevance precision due to explicit LLM-guided reasoning at each step.
Methodology
Semantic Tree Construction
- Bottom-Up Agglomerative: Recursively clusters documents using vector embeddings (Gecko [lee2024gecko]) and generates LLM-based summaries for each internal node. This exploits local document relations and is particularly effective when datasets have underlying structural semantics (e.g., StackExchange).
- Top-Down Divisive: Begins with the entire corpus and recursively partitions using LLMs, informed by hierarchically-increasing summary complexity, until clusters satisfy a maximum branching factor. This enables conceptual clustering when no explicit structure exists.
Tree Traversal and Calibration
Experimental Results
Evaluation on the BRIGHT benchmark [Su2024-xk], encompassing 12 reasoning-intensive IR tasks across multiple domains and up to 420k documents per corpus, confirms the efficacy of LATTICE:
- Zero-Shot Ranking (nDCG@10):
LATTICE achieves average nDCG@10 up to 51.6 on StackExchange subsets, surpassing a strong Gemini-2.5-flash reranking baseline (47.4) and approaching fine-tuned SOTA system DIVER-v2 (52.2). For several domains (Economics, Robotics), it obtains the highest scores among all methods evaluated.
LATTICE records an average of 74.8, exceeding BM25 (+9.5 points) and advanced embedding-based retrievers such as ReasonIR-8B (+4 points).
- Computational Efficiency:
Cost-performance analysis shows that, as search budget increases (in terms of LLM input tokens), LATTICE scales more favorably than rerankers, which plateau early, while LATTICE's scores continue to improve linearly with traversal depth.
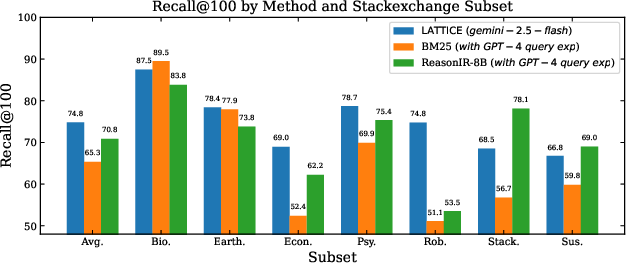
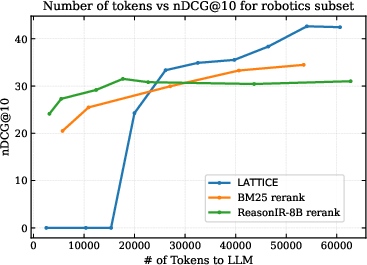
Figure 3: Recall@100 (left) demonstrates consistent LATTICE gains across BRIGHT's StackExchange domains over BM25 and ReasonIR-8B; nDCG@10 vs computational cost (right) shows superior cost-effectiveness for LATTICE compared to reranking.
LATTICE's performance degrades on tasks with dynamic, query-dependent corpora (e.g., certain coding/theorem domains), as pre-computed hierarchy summaries may become invalid when the underlying document index changes; hence, the static nature of the semantic tree is a current limitation when faced with runtime corpus mutability.
Ablation and Analysis
- Score Calibration: Removing latent score calibration yields a consistent nDCG@10 decrease (∼2 points), confirming the necessity of slate-independent global comparison for reliable traversal.
- Path Relevance Smoothing (α): Disabling path smoothing leads to largest drops in retrieval quality among all ablations.
- Reasoning Budget: Restricting the LLM’s stepwise reasoning (forcing it to output only scores) results in non-trivial nDCG@10 drops, demonstrating the importance of explicit LLM-generated rationales for high-level retrieval.
- Construction Strategy Impact: Optimal construction strategy depends on corpus characteristics—bottom-up is preferable for part-whole document hierarchies, while top-down divisive works better for conceptually uniform, unstructured corpora.
Practical and Theoretical Implications
The LATTICE framework reconfigures the role of LLMs in IR by deeply integrating them as the search agent, not merely as rerankers or preprocessors. This design demonstrates that logarithmic retrieval complexity with expert-level, fine-grained reasoning is achievable in zero-shot settings, with zero task-specific fine-tuning.
Practically, LATTICE can be deployed for reasoning-intensive benchmarks and other knowledge-heavy retrieval settings where deep, abstract query-document relationships must be discovered in large corpora, without incurring the cost of task-specific retriever training. The global calibration and path-relevance mechanisms generalize beyond tree traversals, suggesting utility in any structured or semi-structured corpus navigation problem.
On the theoretical front, LATTICE challenges the permanence of the retrieve-then-rerank performance ceiling by shifting the initial search decision mechanism to an LLM agent operating over semantically compositional tree scaffolding, effectively expanding the effective search horizon while introducing noise robustness through latent calibration.
Future Directions
Key open research avenues include:
- Dynamic Tree Maintenance: Efficient methods for updating summaries and calibrations in response to runtime corpus updates, adapting the hierarchical structure to evolving document sets.
- Probabilistic Score Modeling: More advanced models beyond linear MLE calibration, potentially Bayesian frameworks or structured latent variable approaches, may further improve traversal precision.
- Reinforcement Learning Traversal: Jointly learning a traversal policy via RL with path-level rewards tailored to downstream reasoning or question-answering objectives.
- Scalable Construction: Hybrid construction algorithms that use traditional unsupervised clustering at scale for lower layers, augmented with LLM-based summarization only at higher, abstract layers for improved computational tractability.
Conclusion
"LLM-guided Hierarchical Retrieval" establishes a rigorous, LLM-native alternative to established IR paradigms, demonstrating competitive or superior zero-shot retrieval in reasoning-intensive benchmarks by directly integrating LLMs as the search controller over semantic trees. Core innovations in latent calibration, path relevance propagation, and LLM-guided tree construction underpin this result. While the static tree structure presents adaptation challenges for dynamic corpora, the framework provides a tractable path toward robust, semantic, and agentic retrieval systems, setting the foundation for further research at the intersection of LLMs, hierarchical structures, and dynamic corpus reasoning.
