- The paper presents the SAGE benchmark, a controlled, reasoning-intensive test set for evaluating retrieval in multi-domain deep research agents.
- The paper shows that classical sparse retrievers like BM25 outperform LLM-based methods by ~30% on short-form queries, exposing key agent-retriever gaps.
- The paper demonstrates that corpus-level augmentation, which prepends extracted keywords, improves BM25’s exact match by 8%, highlighting tuning opportunities.
Sage: Benchmarking and Improving Retrieval for Deep Research Agents
Introduction
"SAGE: Benchmarking and Improving Retrieval for Deep Research Agents" (2602.05975) systematically interrogates the integration of retrieval mechanisms within deep research agents tasked with complex scientific literature search. The authors introduce Sage, a controlled, reasoning-intensive benchmark across four domains, present critical empirical evidence contrasting sparse and LLM-based retrieval architectures, and propose corpus-level augmentation as a test-time scaling solution. The evaluation exposes fundamental limitations in current agent-retriever interactions, especially in multi-step agentic workflows requiring deep reasoning.
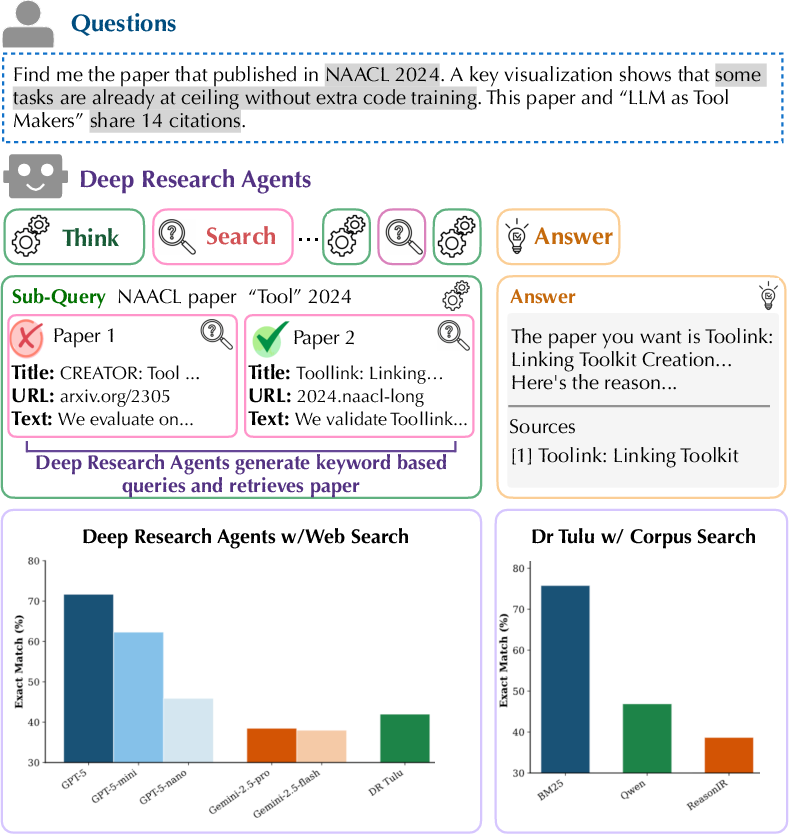
Figure 1: Overview of the Sage task, highlighting iterative reasoning, keyword-based sub-query generation, corpus-level retrieval, and answer synthesis by deep research agents.
Sage Benchmark: Design and Scope
The Sage benchmark consists of 1,200 queries—600 short-form and 600 open-ended—spanning Computer Science, Natural Science, Healthcare, and Humanities, each paired with a 50,000-paper corpus curated to minimize pre-existing LLM knowledge leakage. Short-form queries demand intensive, verifiable reasoning over metadata, multimodal content, and inter-paper relationships; open-ended queries emulate real-world literature review tasks and include multiple, relevance-graded ground-truth documents.

Figure 2: Short-form questions require fine-grained reasoning over metadata and inter-paper relationships with a unique ground-truth answer.

Figure 3: Open-ended questions model practical scientific inquiry, with relevance-weighted ground-truth answer sets.
Corpus construction leverages reference overlap and multimodal extraction, ensuring each domain’s collection remains both up-to-date and comprehensive. Evaluation metrics include Exact Match (EM) for short-form and Weighted Recall for open-ended queries, establishing robust, reproducible standards for retrieval quality.
Empirical Evaluation: Agent and Retriever Analysis
Six deep research agents, both proprietary (e.g., GPT-5, Gemini-2.5 Pro/Flash) and open-source (DR Tulu), are evaluated with their native web search APIs. All systems exhibit pronounced performance deficits on reasoning-intensive retrieval tasks, with proprietary agents leading but none exceeding 80% EM in short-form scenarios.
Further, the interplay between agentic query decomposition and underlying retrieval stack is dissected by replacing web search backends within DR Tulu with alternative retrievers: BM25 (lexical/sparse), gte-Qwen2-7B-instruct (dense semantic), and ReasonIR (reasoning-specialized). BM25 demonstrates ~30% superior accuracy on short-form queries relative to LLM-based retrievers, a strong numerical result. The observed agent queries are predominantly keyword-oriented, making them more compatible with BM25's surface-form matching rather than semantic embedding-based retrieval. With open-ended queries, the advantage narrows, suggesting that broader evidence coverage partially mitigates sparse-dense retrieval disparities.

Figure 4: Case study of iterative retrieval failure in LLM-based retrievers (ReasonIR), where semantic drift accumulates, reinforcing initial keyword focus and failing evidence synthesis; BM25’s lexical anchoring circumvents the drift.
Low-diversity query decomposition, reduced document-level answer locality, and the mismatch between agent-generated query styles and retriever training distributions account for much of the retrieval gap. Increasing top-k candidates per search marginally enhances retrieval effectiveness, particularly for LLM-based retrievers, but does not close the gap.
Corpus-Level Test-Time Scaling
To address retriever-agent misalignment, the authors propose corpus-level augmentation for test-time scaling. Each document's markdown is prepended with LLM-extracted keywords and bibliographic metadata using Qwen3-Next-80B-A3B-Instruct, increasing surface-form signals and mitigating limitations of sparse retrievers under keyword-centric querying.
Post-augmentation, BM25 achieves 8% absolute EM gains in short-form settings; LLM-based retrievers improve only modestly, evidencing higher sensitivity to augmented keyword signals in lexical methods. On open-ended questions, improvements are limited (<3%), attributed to restricted query diversity and evidence space coverage.
Ablation Studies and Auxiliary Analyses
Ablations reveal that retrieval backend strongly determines which information source (metadata, multimodal details, inter-paper relationships) most impacts agent performance. Using web search, agents prioritize paper details; with corpus-based BM25, relationship constraints dominate. Additional experiments with SearchR1-32B affirm the dominance of BM25 even under natural-language querying, further substantiating the benchmark’s insights.
Markdown length distributions across domains reveal markedly longer documents in Sage relative to prior benchmarks—mean 13,000+ tokens—leading to diminished effectiveness of prefix-only dense embedding strategies.
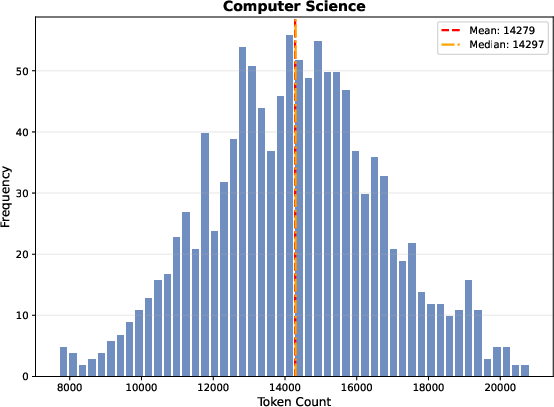
Figure 5: Computer Science document length distribution, indicating substantial document size and challenging retrieval granularity.
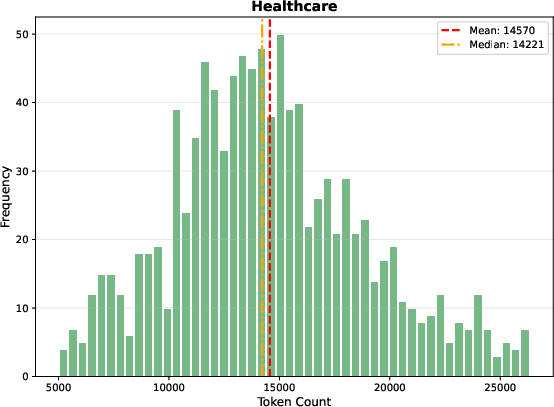
Figure 6: Healthcare domain document length distribution, validating input constraints for embedding strategies.
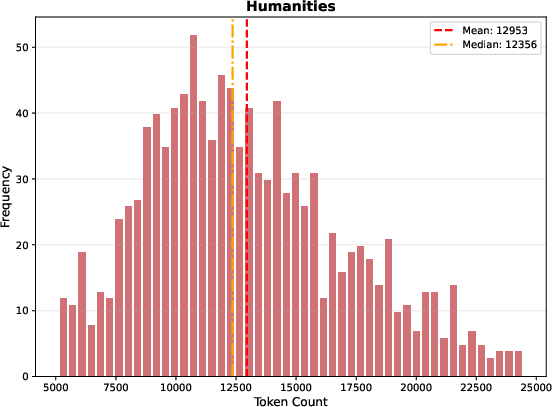
Figure 7: Humanities domain document length distribution, highlighting corpus heterogeneity.
Figure 8: Natural Science domain document length distribution, underpinning retrieval challenges in varying domains.
Implications and Future Directions
The Sage benchmark and its findings underscore several practical and theoretical implications:
- Agent-Retriever Interaction: Current deep research agents are heavily constrained by their retrieval stack; keyword-based query decomposition unintentionally favors classical sparse retrievers over dense semantic architectures, challenging assumptions about LLM superiority in scientific search workflows.
- Corpus Augmentation: Test-time document enrichment is effective primarily for sparse retrieval and highlights a new axis for improving agentic retrieval pipelines; future research should explore more aggressive corpus transformations and retriever-aware agent training.
- Benchmark Design: Controlled, up-to-date, and long-document corpora enable more rigorous assessment of retrieval and synthesis capabilities, suggesting future benchmarks should maintain temporal freshness and document coverage.
- AI System Adaptation: Retrieval-aware query generation, heterogeneous agent designs, and flexible document encoding may further bridge gaps in evidence synthesis, supporting higher-level reasoned outputs critical to scientific discovery.
Conclusion
"SAGE: Benchmarking and Improving Retrieval for Deep Research Agents" provides an authoritative benchmark and empirical foundation demonstrating that agentic scientific search pipelines, when driven by keyword decomposition, are substantially more effective with sparse retrievers than contemporary LLM-based architectures. Corpus-level augmentation improves retrieval, especially for surface-matching systems. The work advocates closer adaptation between agentic decomposition strategies and retrieval architectures, suggesting future research should pursue retriever-aware agent training and advanced corpus transformation for robust scientific inquiry at scale.