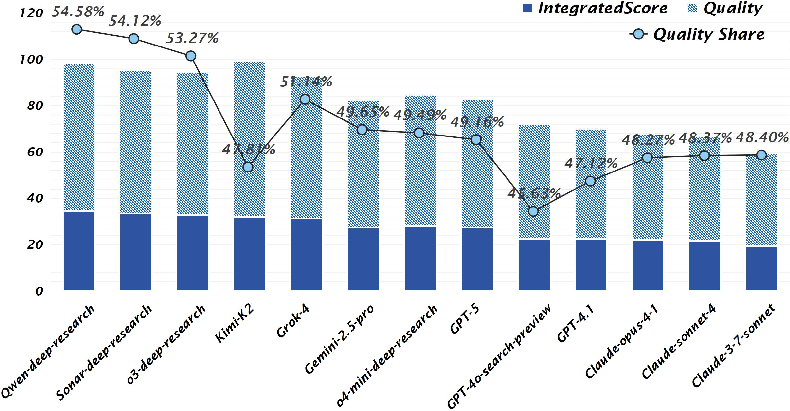
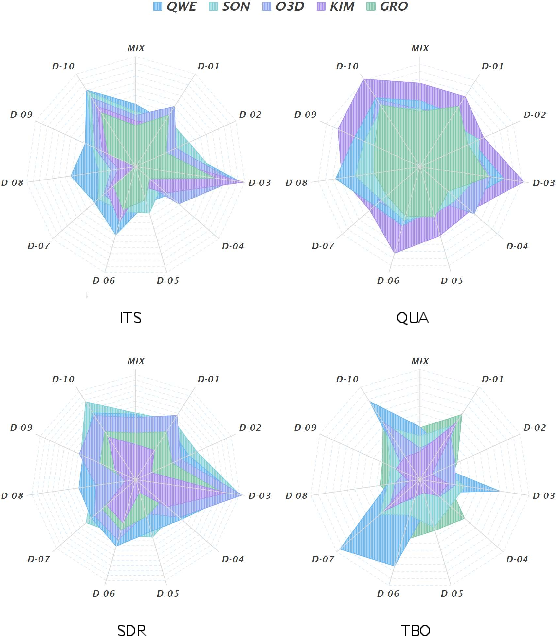
- The paper presents a robust benchmark that evaluates Deep Research Agents on semantic quality, topical focus, and retrieval trustworthiness using detailed rubrics.
- It introduces a multidimensional evaluation framework combining metrics like SemanticDrift and TrustworthyBoost to deliver a comprehensive integrated score.
- Experimental results reveal that DRAs outperform tool-augmented models, though trade-offs between resource efficiency, stability, and coherence remain.
Rigorous Benchmarking and Multidimensional Evaluation for Deep Research Agents
Introduction
The paper presents a comprehensive benchmark and evaluation framework specifically designed for Deep Research Agents (DRAs), a class of agentic systems that integrate task decomposition, cross-source retrieval, multi-stage reasoning, and structured report generation. The work addresses the inadequacies of existing benchmarks, which are predominantly tailored to short-form, discrete outputs and lack the granularity required to assess the complex, report-style outputs characteristic of DRAs. The proposed Rigorous Bench dataset and its associated multidimensional evaluation framework enable systematic, fine-grained assessment of DRA capabilities, with a focus on semantic quality, topical focus, and retrieval trustworthiness.
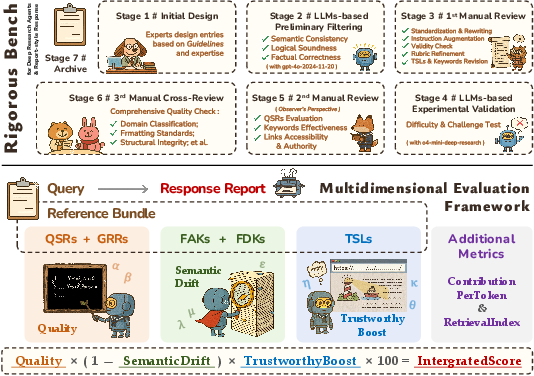
Figure 1: Pipeline for benchmark construction and overview of the evaluation framework.
Benchmark Construction and Dataset Design
Rigorous Bench comprises 214 expert-curated, high-difficulty queries distributed across ten thematic domains, including academia, news, sports, law, business, technology, environment, history, and health. Each entry is paired with a reference bundle containing:
- Query-Specific Rubrics (QSRs): Task-specific criteria for factual accuracy and logical validity, scored in binary or ternary fashion.
- General-Report Rubrics (GRRs): 48 general rubrics assessing structural, logical, and stylistic quality across seven dimensions.
- Trustworthy-Source Links (TSLs): Curated authoritative sources for citation verification.
- Focus-Anchor Keywords (FAKs): Core terms for evaluating thematic focus.
- Focus-Deviation Keywords (FDKs): Terms indicative of topic drift.
The construction pipeline involves iterative expert design, LLM-based auditing, and multi-stage manual review to ensure semantic validity, difficulty, and reproducibility. This process yields a dataset with high representational breadth and evaluative operability.

Figure 2: Detailed criteria for General-Report Rubrics.

Figure 3: Example ID 040216 of benchmark entries.


Figure 4: Examples ID 07001 and 10236 of benchmark entries.

Figure 5: Example ID 08004 of benchmark entries.
Multidimensional Evaluation Framework
The evaluation framework is designed to capture the multifaceted nature of DRA outputs, moving beyond surface-level string matching or LLM-based similarity scoring. The core components are:
- Semantic Quality: Aggregates QSR and GRR scores using a weighted average, normalized to [0,1]. This captures both task-specific and general report quality.
- Topical Focus (SemanticDrift): Quantifies thematic alignment via FAK and FDK metrics, penalizing omission of core concepts and presence of off-topic content. The metric is a weighted sum of FAK and FDK drift, with tunable sensitivity.
- Retrieval Trustworthiness (TrustworthyBoost): Assesses citation reliability by measuring the hit rate of TSLs in the generated report, with multiplicative confidence boosting for exact and hostname matches.
The integrated score is computed as:
IntegratedScore=Quality×(1−SemanticDrift)×TrustworthyBoost×100
This multiplicative formulation penalizes semantic drift and rewards credible external support, yielding a normalized score on a 100-point scale.
Additional metrics include ContributionPerToken (efficiency per output token) and RetrievalIndex (selectivity in information aggregation).
Experimental Results
Thirteen models were evaluated, including five DRAs, one advanced agent, and seven web-search-tool-augmented reasoning models. All models were assessed at deterministic temperature settings, and LLM-based rubric scoring was cross-validated with human judgments (99.3% agreement).
Key findings:
Domain-level analysis revealed that DRAs maintain stable advantages in domains such as sports and health, while web-search-tool-augmented models exhibit higher efficiency and external support alignment. Supplementary metrics highlighted strategic differences in retrieval and reasoning patterns, with DRAs engaging in more complex, multi-stage inference chains.
Limitations and Trade-offs
Two systemic limitations were identified:
- Invocation Instability: Variance in reasoning and retrieval steps across repeated queries, indicating insufficient internal constraints on search behavior.
- Semantic Decomposition Errors: Occasional generation of incoherent or non-English sub-queries, leading to misaligned retrieval and reduced report relevance.
These reflect fundamental trade-offs:
- Efficiency–Quality: High-quality reasoning incurs significant computational cost and latency; adaptive control over search depth and token allocation is required.
- Decomposition–Coherence: Modular query breakdown enhances coverage but risks semantic fragmentation; future architectures must balance decomposition with coherent multi-stage reasoning.
Implications and Future Directions
The Rigorous Bench and its evaluation framework establish a robust foundation for the systematic assessment and optimization of DRAs. The multidimensional approach enables fine-grained diagnosis of model strengths and weaknesses, facilitating targeted architectural refinement. The empirical results underscore the need for improved efficiency, stability, and interpretability in DRA design, particularly in managing resource consumption and maintaining semantic coherence during complex, multi-stage tasks.
Future research should focus on:
- Automated, interpretable scoring mechanisms to further reduce human evaluation overhead.
- Adaptive control strategies for search and reasoning depth to optimize efficiency–quality trade-offs.
- Enhanced decomposition algorithms that preserve semantic fidelity and intent alignment.
- Transferability of the evaluation framework to other agentic and tool-augmented systems beyond DRAs.
Conclusion
This work introduces a rigorous, multidimensional benchmark and evaluation framework for Deep Research Agents, addressing critical gaps in the assessment of complex, report-style outputs. The empirical analysis demonstrates both the current capabilities and persistent limitations of state-of-the-art DRAs, providing actionable insights for future system development and evaluation methodologies in agentic AI.