- The paper demonstrates that LAION-CLAP outperforms MS-CLAP and MuQ-MuLan in aligning with human ratings of instrumental and audio effect timbre.
- The study employs correlation analyses on human-annotated datasets like CCMusic-Database and SocialFX to evaluate timbre semantics in joint embedding spaces.
- The findings advocate for developing timbre-specific training objectives to enhance applications in audio retrieval, captioning, and text-guided music generation.
Analysis of Joint Language-Audio Embeddings and Timbre Semantics
The paper "Do Joint Language-Audio Embeddings Encode Perceptual Timbre Semantics?" (2510.14249) provides a comprehensive study into the efficacy of joint language-audio embedding models—specifically MS-CLAP, LAION-CLAP, and MuQ-MuLan—in capturing the subtle and complex semantics of timbre. This research is pivotal for applications in music information retrieval, audio captioning, and text-guided music generation, where such embeddings map textual descriptions and auditory content into a shared space.
Introduction to Modalities and Prior Work
The study positions itself in the landscape of multimodal embeddings by investigating their alignment with human perception of timbre—a critical yet underexplored aspect. Prior research has identified core perceptual dimensions of timbre (e.g., brightness, warmth, roughness) integral to musical and audio effect description. However, no systematic evaluation had previously assessed these embedding models' alignment with these dimensions on a semantic level.
Methodology and Experimental Design
Models and Datasets
Three models are scrutinized: MS-CLAP and LAION-CLAP, both focusing on general audio understanding, and MuQ-MuLan, concentrated on music. The research leverages datasets such as the CCMusic-Database-Instrument-Timbre and SocialFX, which offer human-annotated timbre descriptors and audio effects, respectively. These datasets provide a robust basis for evaluating the perceptual validity of embeddings.
Experiment 1: Instrumental Timbre Semantics
In this experiment, the alignment of embeddings with human ratings of instrumental timbre was assessed. Employing correlation analysis, the study evaluates descriptor and instrument-level correlations between human ratings and model predictions. LAION-CLAP emerged as the model with the strongest alignment across descriptors, demonstrating robust semantic mapping across varying timbral qualities.
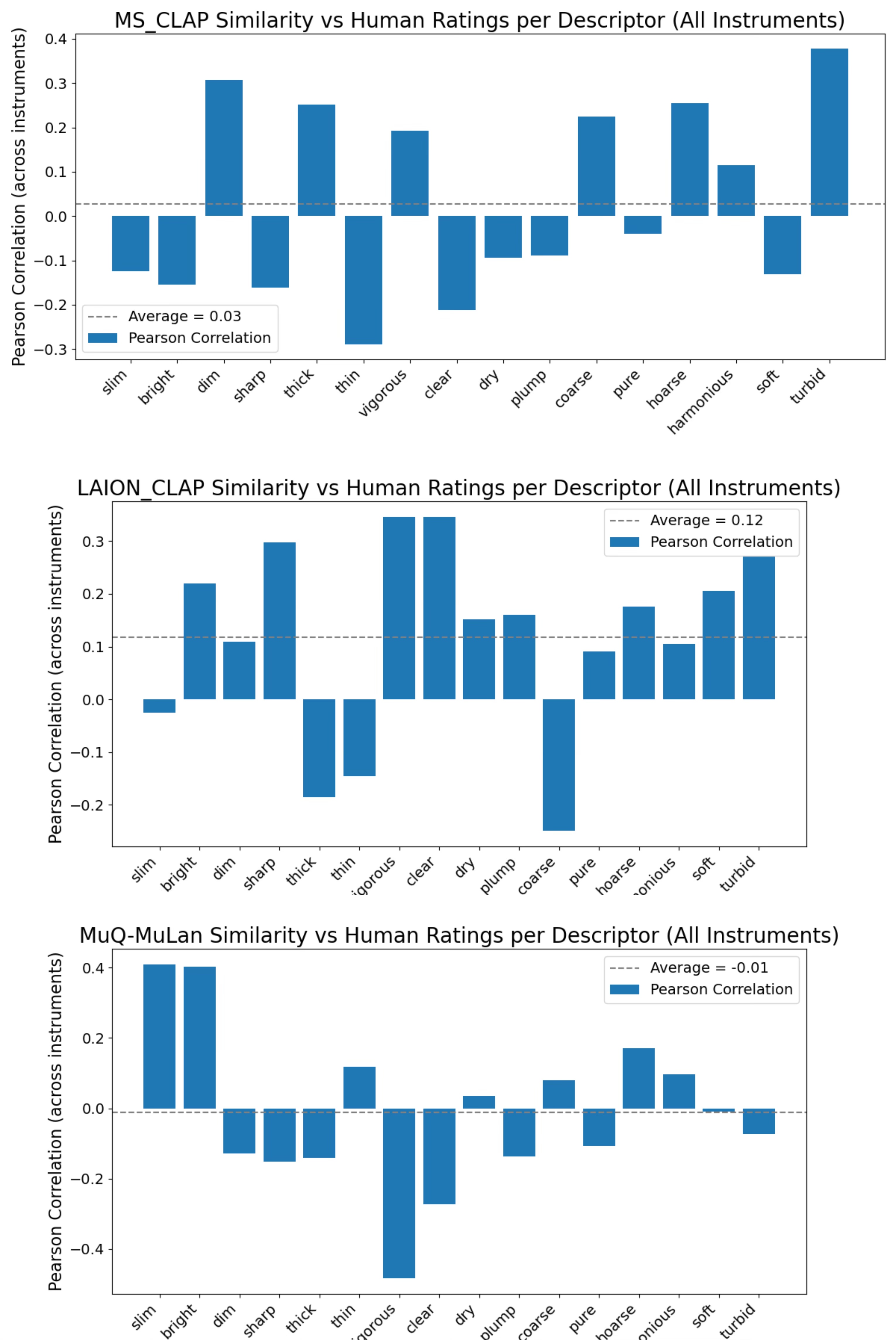
Figure 1: Similarity vs. human ratings per descriptor for MS-CLAP, LAION-CLAP, and MuQ-MuLan.
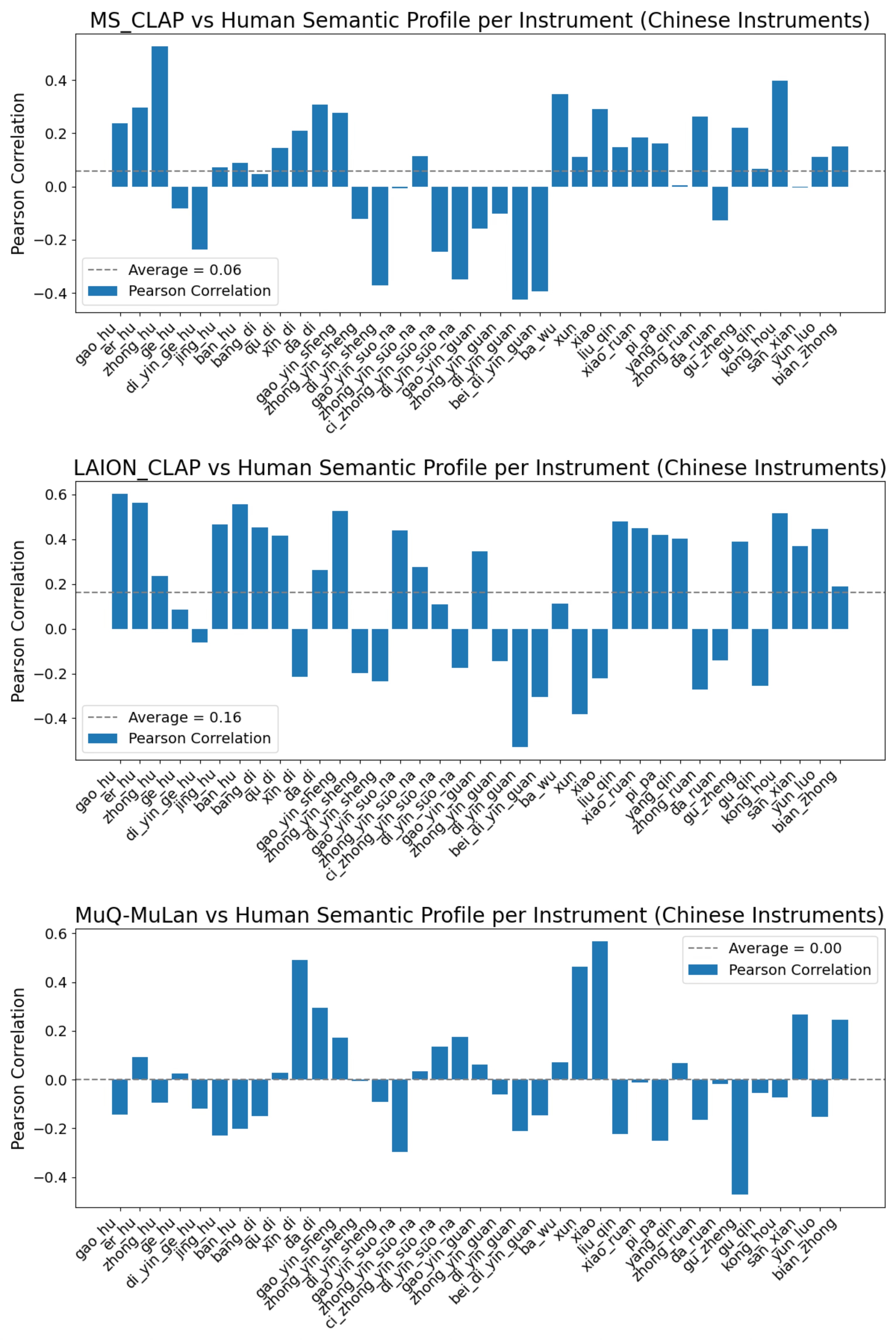
Figure 2: MS-CLAP, LAION-CLAP, and MuQ-MuLan vs. human-rated timbre semantic profile for Chinese instruments.
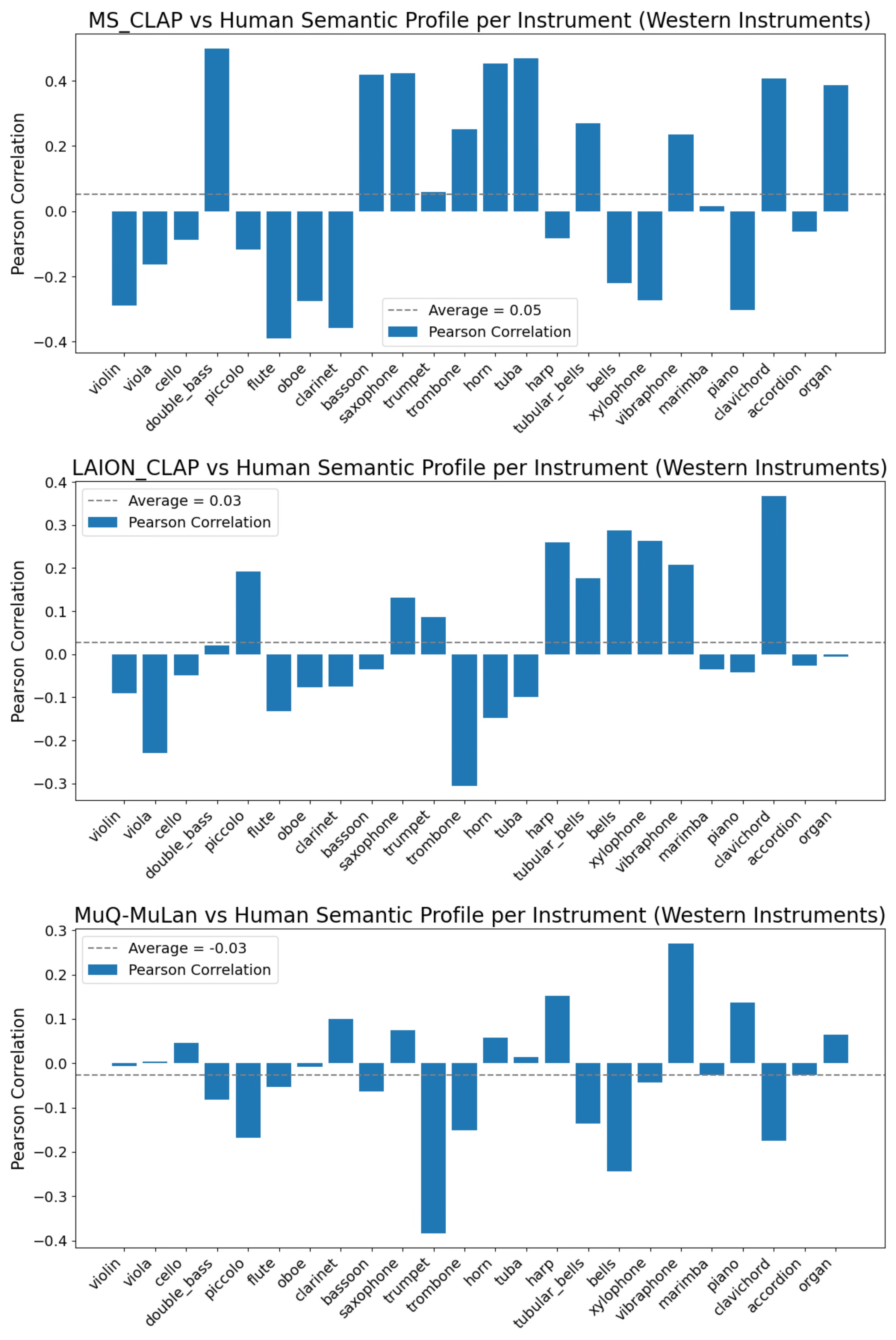
Figure 3: MS-CLAP, LAION-CLAP, and MuQ-MuLan vs. human-rated timbre semantic profile for Western instruments.
Experiment 2: Audio Effect Timbre Semantics
The second experiment controlled timbral variables more precisely via DSP, evaluating EQ and reverberation effects. This approach assessed how each model captured timbral changes aligned with specific descriptors. Despite weaker results overall, LAION-CLAP again showed superior performance, particularly in aligning with EQ-induced timbral changes.
Results and Discussion
The results indicate that while LAION-CLAP consistently achieves the highest alignment with human timbre perception across both experiments, MS-CLAP and MuQ-MuLan exhibit limited efficacy in accurately capturing such perceptual dimensions. This suggests potential areas for model refinement, such as incorporating timbre-specific training objectives.
Conclusion and Future Prospects
The findings underscore the superior performance of LAION-CLAP in encoding perceptual timbre semantics, offering invaluable insights for enhancing audio-based applications through improved semantic embeddings. Future explorations may include developing interpretable timbral axes within the embeddings, potentially enhancing capabilities in audio retrieval, manipulation, and synthesis tasks. The implications of such advancements could significantly refine the interaction between linguistic descriptors and auditory perceptions, thus broadening the scope and applicability of joint embeddings in complex musical and acoustic environments.