- The paper introduces CBF-RL, a dual framework that integrates control barrier functions for training-time safety filtering and reward shaping, achieving faster convergence and improved safety in high-dimensional humanoid tasks.
- It establishes a theoretical bridge between continuous-time CBFs and discrete-time RL using closed-form safety filters with explicit Euler discretization bounds.
- Empirical evaluations, including ablation studies and real-world humanoid experiments, show that the dual approach consistently outperforms reward-only and filter-only methods in achieving robust obstacle avoidance and stair climbing.
Safety Filtering Reinforcement Learning in Training with Control Barrier Functions (CBF-RL)
Overview
The paper introduces CBF-RL, a dual-framework for safe reinforcement learning (RL) that integrates Control Barrier Functions (CBFs) into both the training and reward structure of RL agents. The approach is designed to internalize safety constraints within the learned policy, enabling deployment without the need for a runtime safety filter. The framework is validated through theoretical analysis, ablation studies, and real-world experiments on high-dimensional humanoid robots, demonstrating robust performance in obstacle avoidance and stair climbing tasks.

Figure 1: A humanoid robot trained to climb stairs with the CBF-RL framework. Safety is injected into training by both filtering the policy-proposed actions and also provide safety rewards in addition to task and regularization rewards. During deployment the CBF policy retains safe behavior without a runtime filter.
Theoretical Foundations
CBFs provide a formal mechanism for encoding state-based safety constraints as forward-invariant sets. The paper establishes a rigorous connection between continuous-time CBFs and their discrete-time analogues, which is critical for RL environments that operate with sampled-data and zero-order hold. The main theoretical contribution is a proof that continuous-time safety filters can be deployed via closed-form expressions on discrete-time rollouts, with explicit bounds on the evolution of the barrier function under Euler discretization. This enables the use of continuous-time CBF tools directly in discrete-time RL training, provided the simulation timestep Δt is sufficiently small.
The safety filter is implemented as a closed-form solution to the CBF-QP:
vksafe={vkpolicy,if ak⊤vkpolicy≥bk vkpolicy+∥ak∥2(bk−ak⊤vkpolicy)ak,otherwise
where ak=∇h(qk) and bk=−αh(qk).
Dual Approach: Safety Filtering and Reward Shaping
CBF-RL combines two complementary mechanisms:
- Safety Filtering During Training: The policy's proposed actions are filtered through the CBF-QP, ensuring that only safe actions are executed in the environment. This prevents catastrophic unsafe actions during exploration and provides direct corrective supervision to the policy.
- Barrier-Inspired Reward Shaping: The reward function is augmented with a term that penalizes unsafe actions and incentivizes the policy to propose actions that satisfy the barrier condition. The reward is defined as:
rcbf(qk,vk)=max(ak⊤vkpolicy−bk,0)+(exp(−σ2∥vkpolicy−vksafe∥2)−1)
This dual approach enables the policy to internalize safety constraints, resulting in safe behavior at deployment without requiring an online safety filter.
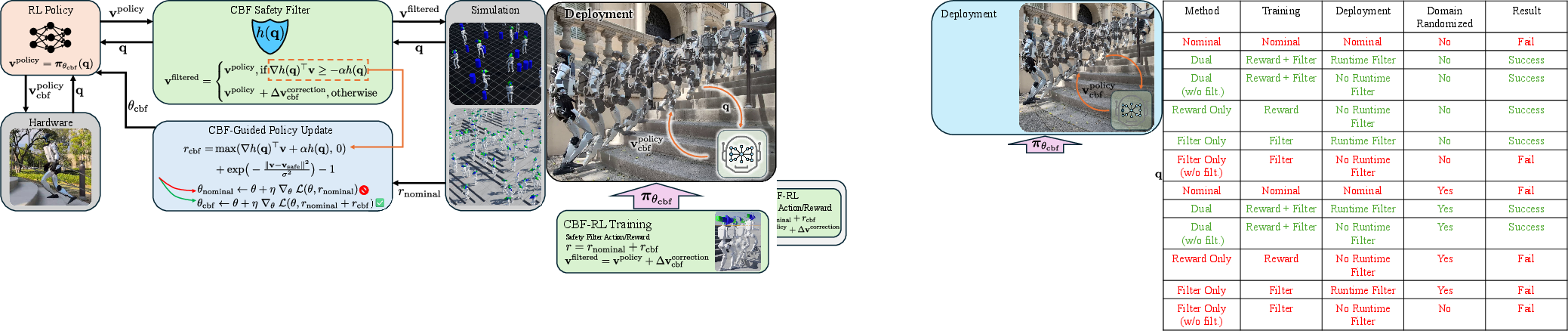
Figure 2: CBF-RL framework: For one given task, the user defines the safety barrier function h(q) and the accompanying ∇h(q). During training, the RL policy proposes actions, which are filtered and rewarded for safety. At deployment, the policy outputs safe actions without a runtime filter.
Empirical Evaluation and Ablation Studies
The framework is evaluated on a 2D navigation task and high-dimensional humanoid locomotion tasks. Ablation studies compare four variants: Dual (filter + reward), Reward-only, Filter-only, and Nominal. The Dual approach achieves higher rewards, faster convergence, and maintains safety throughout training. Notably, policies trained with filtering but deployed without a runtime filter degrade markedly, while Dual-trained policies retain safety.
Robustness is further validated under domain randomization, with the Dual approach suffering the least degradation due to dynamics uncertainty. Success rates over 1000 random test environments show that the Dual policy consistently outperforms other methods, both with and without runtime filtering.
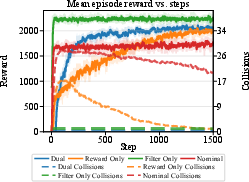
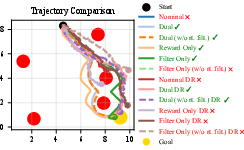
Figure 3: Training progress with the Dual, Reward Only, Filter Only and Nominal methods. Dual and Filter Only achieve faster convergence and avoid training-time safety violations.
Application to Humanoid Locomotion
CBF-RL is applied to two humanoid tasks: planar obstacle avoidance and blind stair climbing. For obstacle avoidance, the safety barrier is defined as the distance to the nearest obstacle, and the policy modulates planar velocities to maintain safe separation. For stair climbing, the reduced-order model is the swing foot's position, with the barrier function preventing toe collisions with stair risers.
Zero-shot sim-to-real transfer is demonstrated on the Unitree G1 humanoid robot. The robot successfully navigates obstacles and climbs stairs of varying roughness, tread depths, and riser heights, relying solely on proprioception for terrain adaptation. The Dual-trained policy enables the robot to climb high stairs (0.3m riser) that nominal policies fail to traverse, as evidenced by CBF violation markers and collision events.
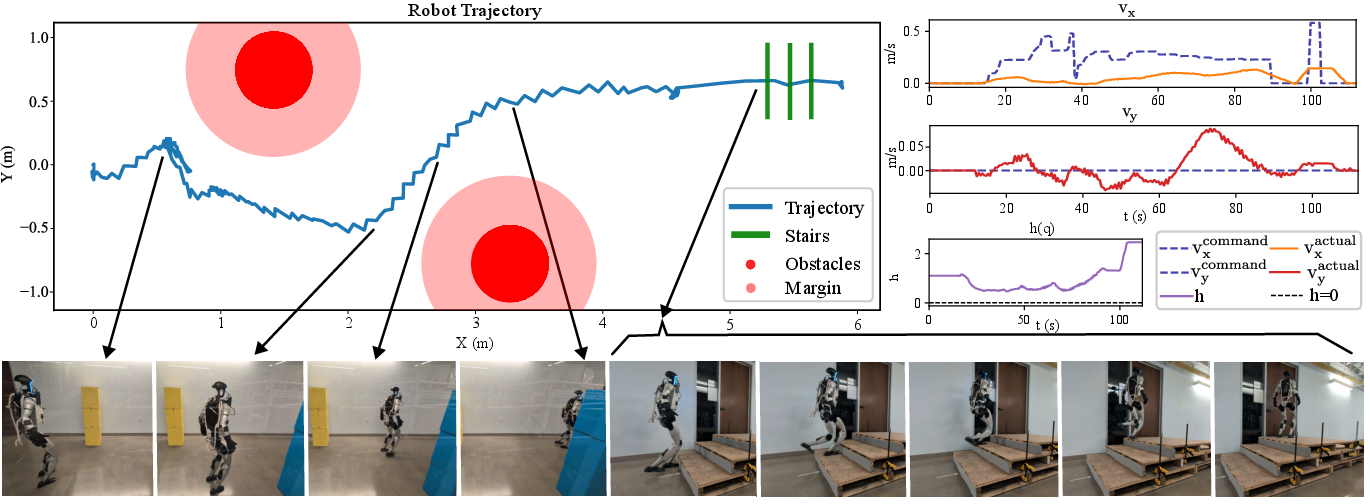
Figure 4: Robot trajectory, h, and command vs. actual velocity visualization. The robot avoids obstacles approximated as cylinders without a runtime safety filter and climbs up stairs. The velocity plots show the robot modulating its own velocities despite the command and the h plot quantifies safety.

Figure 5: Snapshots of high stairs of riser height 0.3m. The nominal policy clips its feet against the riser and stumbles, as shown with the red CBF violations while the CBF-RL dual trained policy successfully climbs up and down. The yellow star marks the point the robot's feet collides with the stair riser.

Figure 6: Snapshots of outdoor experiments. The robot is able to climb up stairs of varying roughness, tread depths and riser heights.
Implementation Considerations
- Computational Efficiency: The closed-form CBF-QP solution enables lightweight integration with massively parallel RL environments (e.g., IsaacLab), avoiding the overhead of solving QPs at every step.
- Model-Free Compatibility: The framework requires only derivatives of the reduced-order model (e.g., kinematic Jacobians), making it suitable for high-dimensional systems with uncertain dynamics.
- Scalability: The approach is agnostic to the underlying RL algorithm and can be extended to other domains beyond locomotion, such as whole-body loco-manipulation.
- Deployment: Policies trained with CBF-RL can be deployed without a runtime safety filter, reducing computational burden and latency in real-world systems.
Implications and Future Directions
CBF-RL advances the integration of formal safety guarantees into RL for high-dimensional, safety-critical systems. The dual approach enables policies to internalize safety constraints, facilitating robust, efficient, and safe exploration and deployment. Theoretical analysis supports the use of continuous-time CBFs in discrete-time RL, broadening the applicability of control-theoretic safety tools in learning-based control.
Future work may focus on automated barrier discovery, perception-based barriers, and extending CBF-RL to whole-body manipulation and other complex tasks. The framework's compatibility with model-free RL and its empirical success in sim-to-real transfer suggest strong potential for broader adoption in robotics and autonomous systems.
Conclusion
CBF-RL provides a principled, efficient, and empirically validated framework for safe reinforcement learning by combining training-time safety filtering with barrier-inspired reward shaping. The approach enables policies to internalize safety constraints, achieving robust performance in both simulation and real-world humanoid locomotion tasks without the need for runtime safety filters. Theoretical and practical contributions position CBF-RL as a significant step toward scalable, safe RL for complex robotic systems.