- The paper introduces SNOO, which applies Nesterov momentum to pseudo-gradients, achieving 1.5x–2.5x compute efficiency gains over AdamW.
- The paper demonstrates that SNOO improves convergence and robustness by smoothing training trajectories and reducing model weight norms.
- The paper validates SNOO's scalability across dense and MoE architectures, offering a minimal overhead, single-worker deployment for LLMs.
Step-K Nesterov Outer Optimizer (SNOO): A Detailed Analysis
Introduction to SNOO
The paper "SNOO: Step-K Nesterov Outer Optimizer - The Surprising Effectiveness of Nesterov Momentum Applied to Pseudo-Gradients" (2510.15830) addresses a critical need in the field of LLMs: efficient optimization techniques. Traditionally, optimizers like AdamW have been prevalent for training LLMs. However, as the scale of these models grows, so do the computational costs. The paper presents SNOO, which leverages Nesterov momentum applied to pseudo-gradients, achieving substantial efficiency improvements in training large models without the complexities of distributed setups.
Methodology
SNOO is built upon the Lookahead optimizer framework, which uses a two-loop structure to update model weights across different time scales. Specifically, SNOO replaces traditional gradient updates with pseudo-gradients—a trajectory produced by inner optimizer steps. The adoption of Nesterov momentum enhances this approach by effectively smoothing the training trajectory, thus improving convergence rates.
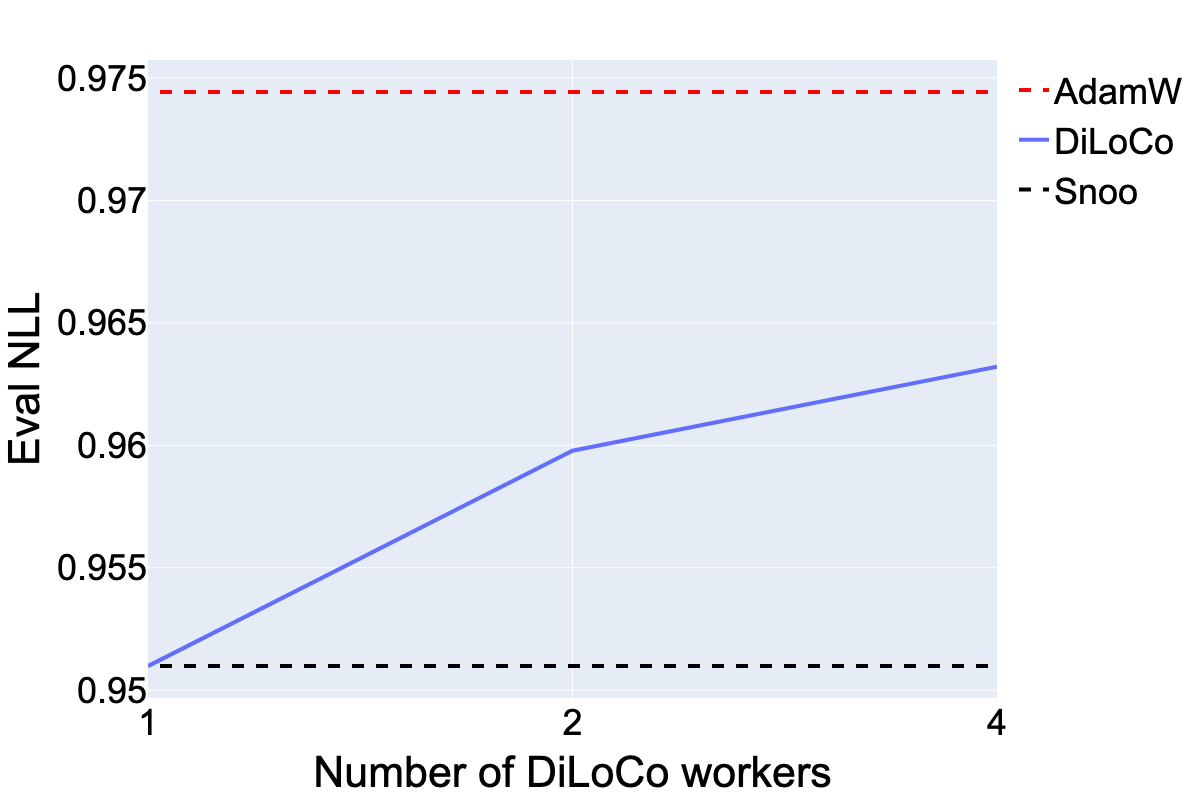
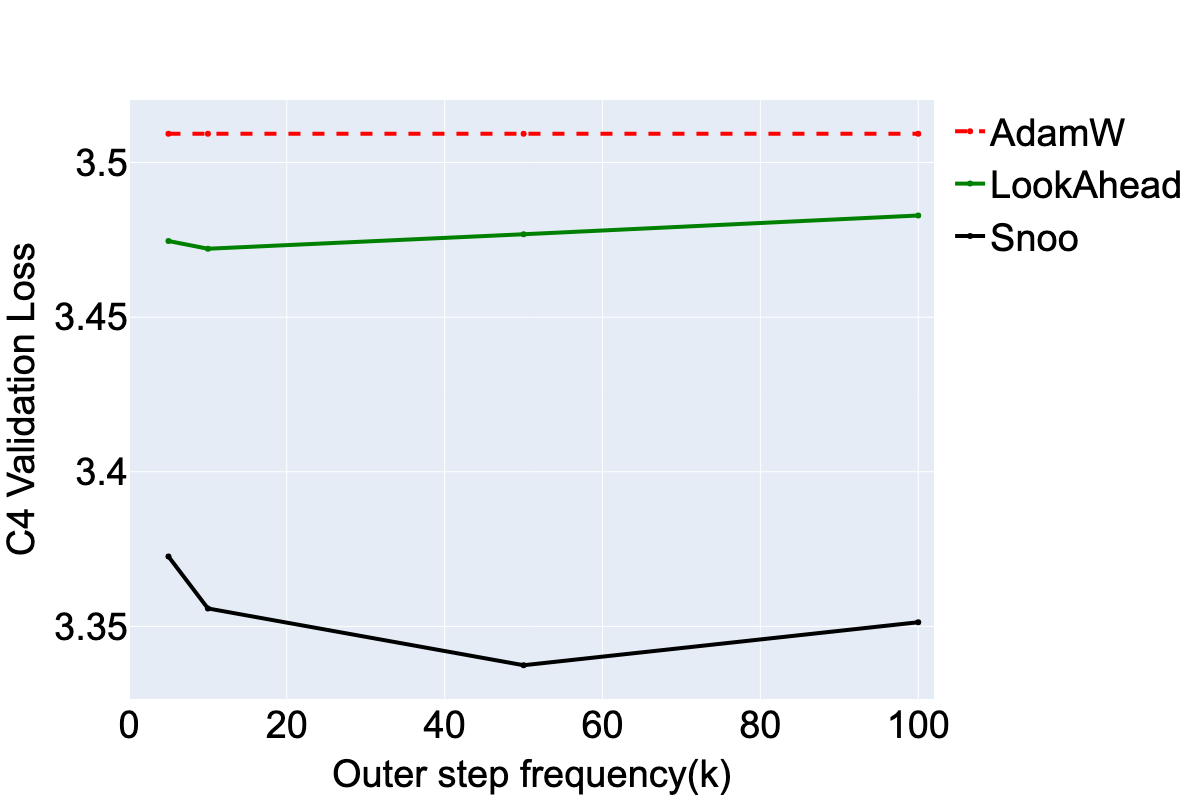
Figure 1: DiLoCo is able to outperform the AdamW baseline even when increasing the number of workers. However, its performance is best with only a single worker, which is equivalent to disabling the local SGD component and only applying Nesterov momentum to the pseudo-gradients.
Unlike distributed methods like DiLoCo, which apply Nesterov momentum in a multi-worker environment, SNOO achieves optimal performance with a single worker setup. This simplicity allows SNOO to integrate easily into existing pipelines, providing a practical enhancement for various inner optimizers including AdamW and Muon.
Experimental Results
The paper conducts extensive evaluations to assess the performance of SNOO across different model scales and architectures. Notably, SNOO demonstrates gains in compute efficiency of 1.5x to 2.5x compared to AdamW, with improvements increasing as model size grows. This is particularly evident in medium-scale Llama-3 models trained on the C4 dataset and large-scale models reaching up to 1e23 FLOPs.
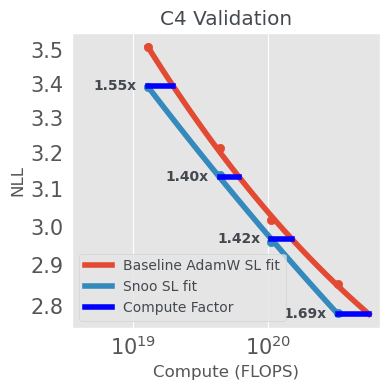
Figure 2: SNOO shows strong improvements across compute scales over the AdamW baseline on the C4 validation dataset. This figure plots NLL on a held-out validation set of C4 run using TorchTitan on OSS Llama-3 models.
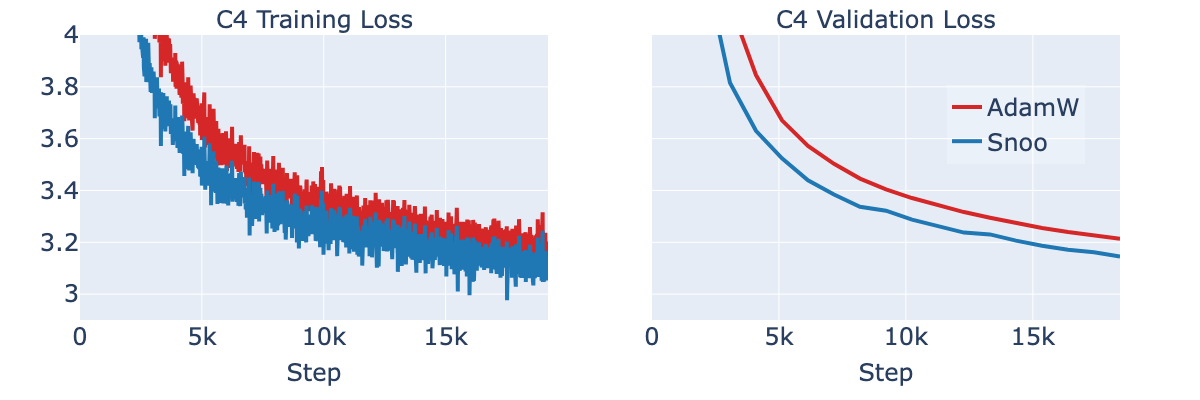
Figure 3: SNOO outperforms the AdamW baseline throughout training, exhibiting lower train and validation loss using a 300M dense transformer model. This figure plots NLL on training and held-out validation set of C4 run using TorchTitan on OSS Llama-3 models.
The empirical results suggest that SNOO's scaling benefits become even more pronounced at large scales, with dense and Mixture-of-Experts (MoE) models showing consistent performance improvements across different benchmarks. These findings underscore SNOO's potential for real-world applications where training efficiency directly translates to reduced costs and time.
Implicit Regularization and Generalization
Beyond raw efficiency, SNOO exhibits intriguing implicit regularization properties. The paper discusses two key observations: SNOO encourages smaller ℓ2-norms of model weights, and it shows resilience to overfitting when training on data with repeated inputs. These characteristics suggest that SNOO not only speeds up convergence but also improves model robustness, potentially contributing to better generalization.
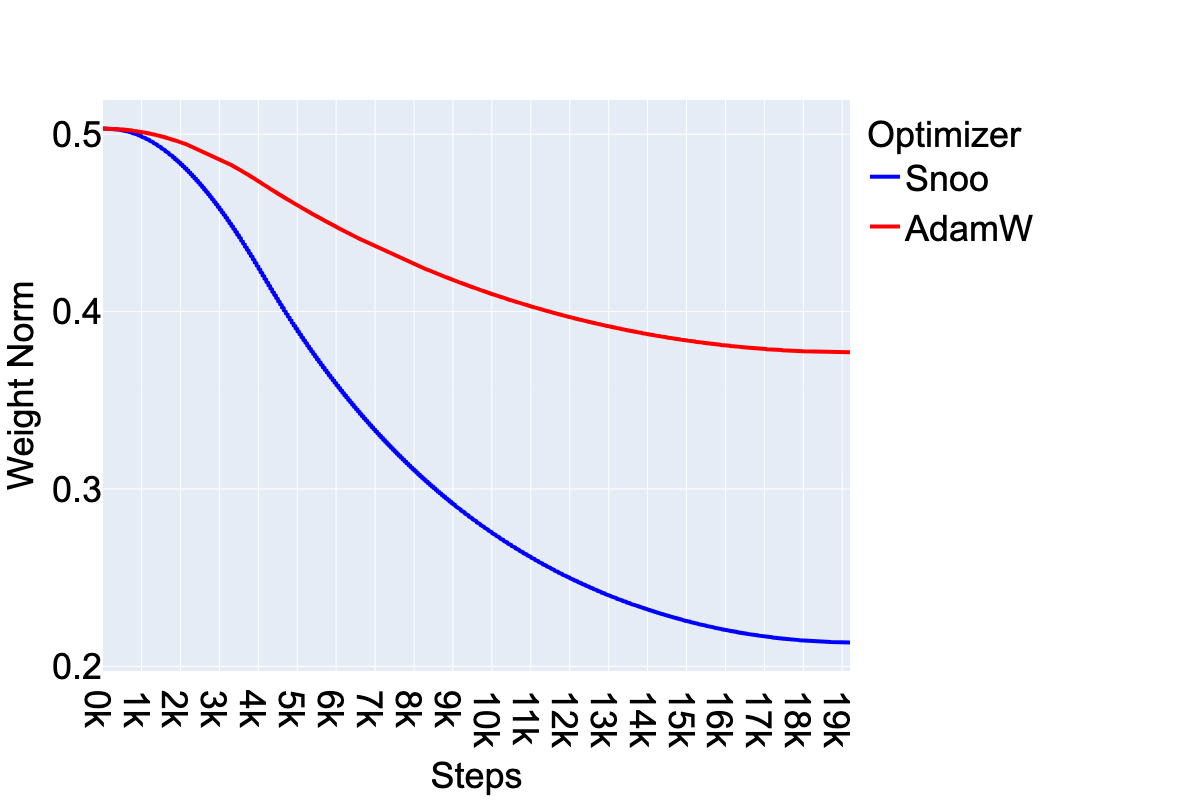
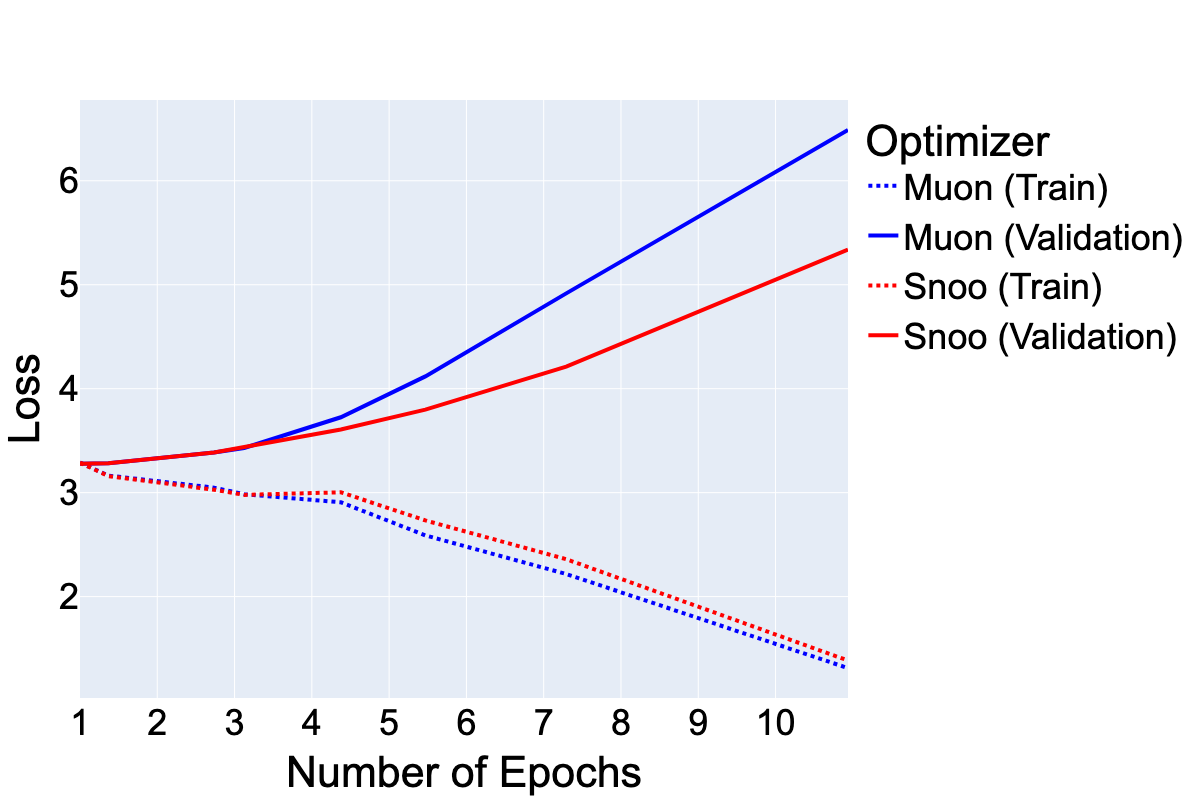
Figure 4: SNOO (with AdamW as the inner optimizer) encourages smaller ℓ2-norms of the model weights compared to AdamW, with weight norms continually decreasing as training progresses.
Systems Implications
From a systems perspective, SNOO is efficient in terms of additional computational and memory resources. The overhead introduced by the outer update is minimal, making it compatible with parallel computing frameworks like Fully-Sharded Data Parallelism (FSDP). This positions SNOO as a scalable and practical solution for training large-scale LLMs in both academic research and industry settings.
Conclusion
SNOO represents an effective optimization strategy that integrates Nesterov momentum with pseudo-gradients, offering significant compute efficiency gains without sacrificing model performance or generalization. Its utility spans across different model architectures and scales, providing a robust approach suitable for the ongoing quest to train ever-larger LLMs. Future research could explore deeper theoretical underpinnings of SNOO's regularization effects and extend its application to more diverse machine learning tasks.