Glyph: Scaling Context Windows via Visual-Text Compression
Abstract: LLMs increasingly rely on long-context modeling for tasks such as document understanding, code analysis, and multi-step reasoning. However, scaling context windows to the million-token level brings prohibitive computational and memory costs, limiting the practicality of long-context LLMs. In this work, we take a different perspective-visual context scaling-to tackle this challenge. Instead of extending token-based sequences, we propose Glyph, a framework that renders long texts into images and processes them with vision-LLMs (VLMs). This approach substantially compresses textual input while preserving semantic information, and we further design an LLM-driven genetic search to identify optimal visual rendering configurations for balancing accuracy and compression. Through extensive experiments, we demonstrate that our method achieves 3-4x token compression while maintaining accuracy comparable to leading LLMs such as Qwen3-8B on various long-context benchmarks. This compression also leads to around 4x faster prefilling and decoding, and approximately 2x faster SFT training. Furthermore, under extreme compression, a 128K-context VLM could scale to handle 1M-token-level text tasks. In addition, the rendered text data benefits real-world multimodal tasks, such as document understanding. Our code and model are released at https://github.com/thu-coai/Glyph.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper introduces a new way to help AI models read and understand very long text (like whole books or big code files) without slowing down or needing huge amounts of memory. The idea is called “Glyph.” Instead of feeding the AI raw text, Glyph turns long text into images and lets a vision–LLM (a model that can read both pictures and words) process those images. This packs more information into fewer input pieces, so the AI can handle much longer content faster and cheaper.
Goals
The researchers wanted to solve a common problem: most AI models have a limit to how much text they can read at once (called a “context window”). If the text is too long, the model can miss important details. Their goals were:
- Find a way to fit more text into the model’s input without losing meaning.
- Keep accuracy as high as popular text-only models.
- Speed up reading and answering (inference) and training.
- Make a model with a standard context window (like 128K tokens) still capable of tasks that normally need up to 1 million tokens.
How It Works (in everyday language)
Think of an AI’s “context window” like the number of pages it can look at before answering a question. Text-only models count every word piece (a “token”) separately, which adds up fast. Glyph takes a different approach:
- Render text into images: It “prints” the text onto virtual pages—like screenshots of a document—then feeds these images to a vision–LLM (VLM). One image “token” can hold many words at once, so the model sees more content with fewer tokens.
- Compression: “Compression ratio” is how much fewer tokens the model uses after turning text into images. A 3× compression means the model uses about one-third as many tokens as before but still sees the same content.
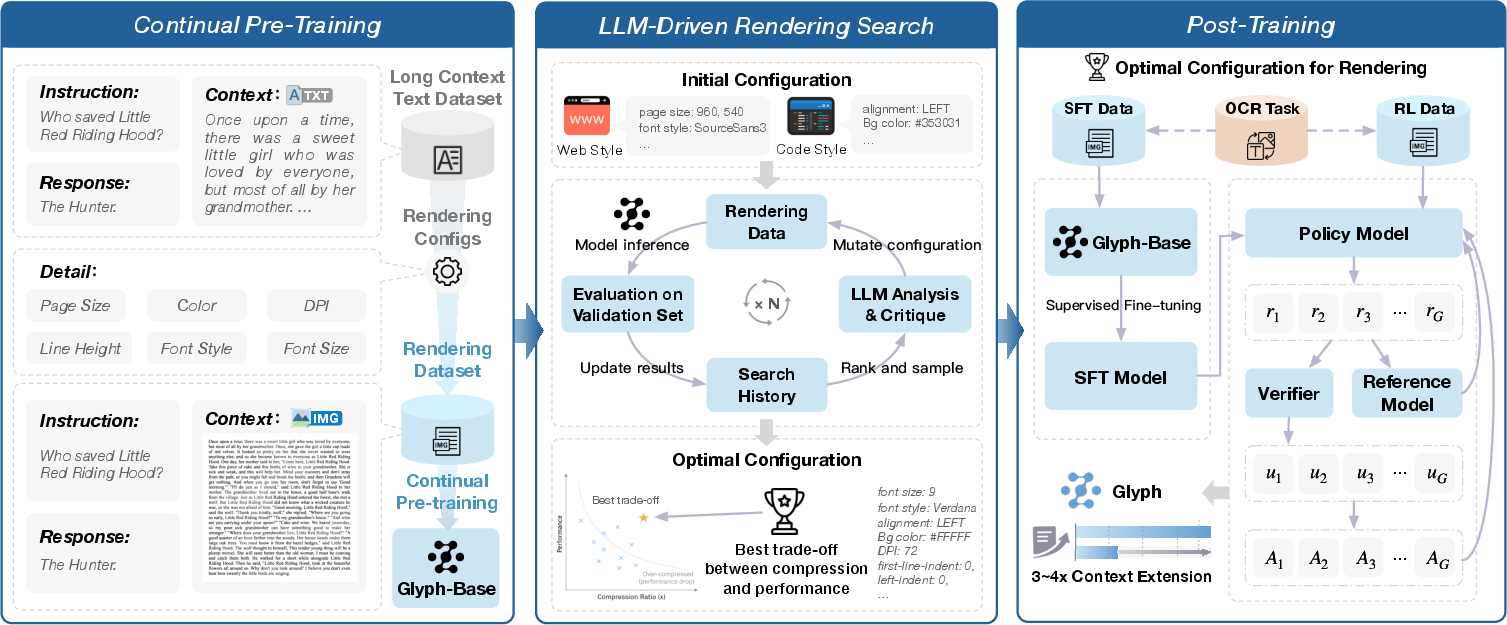
- Three stages to train the model:
- Continual pre-training: The model practices reading lots of rendered pages in different styles (like normal documents, web pages, dark mode, code blocks) so it learns to understand text inside images.
- LLM-driven genetic search: They use another AI to help “breed” and test different rendering settings (font size, spacing, resolution, layout) to balance readability and compression. It’s like trying different page designs until you find the best.
- Post-training (SFT + RL): They fine-tune the model with supervised training (SFT) on high-quality examples and then improve it with reinforcement learning (RL). They also add an extra OCR task (optical character recognition) so the model gets better at reading small or tricky text inside the images.
Key terms explained simply:
Token: A chunk of text the AI reads (often part of a word). More tokens = more memory and time.
- Context window: The maximum amount of text the AI can look at at once.
- VLM (Vision–LLM): An AI that understands both images and text together.
- OCR: A tool that helps the AI “read” text inside an image.
- Prefill and decoding: Two phases of answering. Prefill is like reading the question and context; decoding is generating the answer.
Main Findings and Why They Matter
What they found:
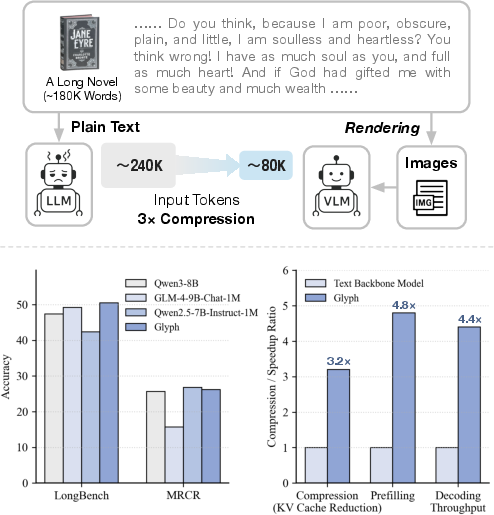
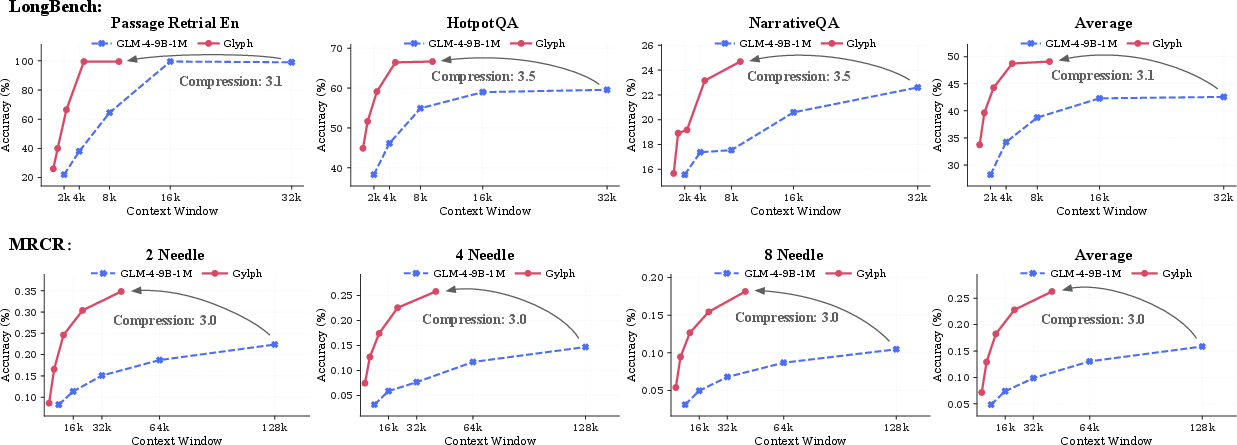
- 3–4× compression with similar accuracy: Glyph can compress input by 3–4 times while staying as accurate as strong text-only models (like Qwen3-8B) on long-context benchmarks (LongBench, MRCR, Ruler).
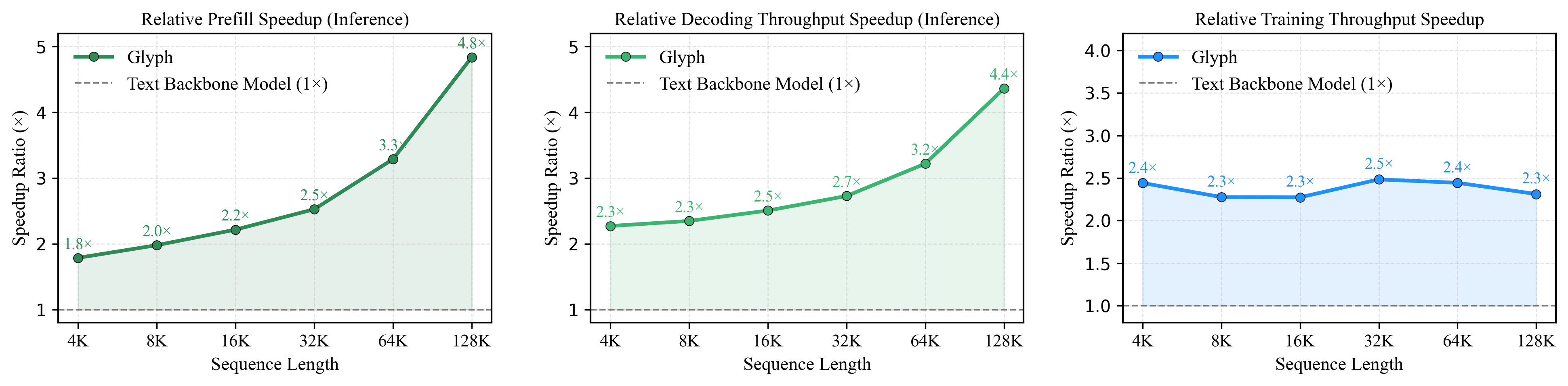
- Faster speed: Around 4× faster in reading and answering (prefill and decoding), and about 2× faster training in supervised fine-tuning.
- Bigger effective context: A model that normally handles 128K tokens can, with Glyph’s compression, tackle tasks that would usually need around 1 million tokens. In one example, the book “Jane Eyre” (about 240K tokens) can be fully processed by a 128K-context VLM when rendered into compact images (~80K visual tokens).
- Good generalization: Even though the model mainly trained on rendered text images, it also improved at real-world document tasks (like reading PDF documents with different layouts), showing it can handle practical multimodal inputs.
Why it matters:
- It lets AI “read” much longer content more efficiently, which is crucial for tasks like legal documents, scientific papers, long chats, or large codebases.
- It reduces memory and compute costs, making powerful long-context AI more practical and affordable.
- It opens a new path beyond just changing the AI’s attention mechanism—by changing how we present the input.
Implications and Impact
Glyph suggests a new way to scale AI’s ability to handle very long inputs: increase information density by converting text into images that the AI can read well. This could:
- Make long document understanding faster and cheaper in real applications (education, law, research, coding).
- Help build AI assistants that remember and reason over longer histories (like months of conversations or large project files).
- Encourage “context engineering”: choosing the best way to present information (fonts, layouts, resolution) to the AI to get better results.
There are still challenges, like being sensitive to rendering settings and recognizing rare, tricky text patterns (like UUIDs). Future improvements could include adaptive rendering (changing the page style depending on the task), better OCR, and stronger alignment between visual and text models. But overall, Glyph shows a promising, practical direction for making long-context AI more powerful and efficient.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper introduces a promising visual–text compression paradigm (Glyph), yet several technical and empirical aspects remain underexplored. The following concrete gaps can guide future research:
- Robustness to rendering variability: Quantify performance sensitivity to DPI, font family/size, line height, column count, color schemes (e.g., dark mode), background textures, anti-aliasing, and kerning. Provide robustness curves and stress tests across systematically perturbed renderings.
- Cross-lingual and script coverage: Evaluate and train for non-Latin scripts (CJK, Devanagari), right-to-left languages (Arabic, Hebrew), vertical/bi-directional layouts, mixed-script text, and diacritics. Assess whether compression vs accuracy trade-offs differ by script.
- Fine-grained OCR fidelity: Characterize failure modes on rare/structured tokens (UUIDs, long numbers, hex strings, URLs, email addresses, code identifiers), and quantify how these errors propagate to downstream reasoning. Explore integrating specialized OCR heads or lexicon-constrained decoding.
- Complex document structures: Test on and adapt to tables, math formulas/LaTeX, inline equations, footnotes, references, multi-column layouts, figure captions, code blocks with indentation/whitespace significance, and cross-references. Measure layout-sensitive degradation and devise layout-aware encoders.
- Information loss vs compression frontier: Establish Pareto curves linking compression ratio to semantic preservation across tasks and domains. Identify per-task compression thresholds beyond which answers degrade sharply.
- Task-adaptive rendering (open): Develop and evaluate policies that choose rendering parameters (DPI, font size, cropping, multi-resolution zoom) conditioned on task/query, with budgeted compute. Compare fixed vs adaptive schemes under the same token budget.
- End-to-end differentiable or learnable rendering: Replace fixed rasterization with differentiable/neural rendering or learned text-to-visual codecs to co-optimize readability for the VLM. Study whether gradients through rendering improve OCR fidelity and reasoning.
- Vision encoder bottlenecks: Ablate patch size, stride, positional encoding, and cross-attention bridging to the LLM. Determine how visual tokenization interacts with compression, and whether smaller patches or hierarchical encoders improve legibility at low DPI.
- Multi-resolution reading strategies: Investigate coarse-to-fine pipelines (global low-res pass + selective high-res zoom on suspected spans). Measure end-to-end latency and accuracy with learned zooming policies.
- Page and chunk boundary effects: Analyze errors due to page breaks, reflow, hyphenation, or truncated lines. Propose boundary-aware rendering or overlap strategies and quantify their benefit.
- Ordering and 2D-to-1D alignment: Study how the model infers reading order in multi-column or complex layouts. Evaluate layout-aware positional encodings or graph/sequence-of-boxes representations vs plain raster pages.
- Reproducibility and compute of rendering search: Report search budget, convergence criteria, and generalization of the found configuration across datasets/tasks. Compare single best config vs Pareto-front multi-objective optimization (accuracy–compression–latency–memory).
- Generalization beyond seen styles: Test zero-shot performance on unseen fonts, paper textures, scanner noise, camera-captured documents, distortions (skew, blur), and compression artifacts. Develop augmentation policies targeted at these shifts.
- Security and adversarial typography: Assess vulnerability to adversarial fonts, homoglyphs, obfuscated text, hidden/overlapping layers, and watermarking. Propose detection/defense strategies.
- Privacy and data handling: Evaluate risks introduced by rasterizing sensitive text into images (storage, logging, redaction). Explore on-device rendering, ephemeral processing, and secure enclaves.
- End-to-end efficiency accounting: Include rendering time, disk I/O, image encoding/decoding overhead, and GPU memory bandwidth in wall-clock and energy measurements. Compare against strong long-attention baselines under matched hardware and batching.
- Memory/latency trade-offs at higher DPI: Quantify how increasing DPI at test time impacts VRAM, throughput, and tail latencies; identify practical ceilings on “test-time scaling” under real deployment constraints.
- Scaling laws with model size: Provide empirical scaling for small-to-large VLM backbones under fixed compression ratios (accuracy, OCR error rates, stability), and determine whether larger models alleviate OCR bottlenecks.
- Backbone dependence: Evaluate Glyph across multiple VLM architectures (e.g., different vision backbones, connector types) to test portability and to identify architecture–compression interactions.
- Impact on general vision tasks: Measure whether heavy training on rendered text regresses performance on natural-image tasks (e.g., VQAv2, doc-VQA, COCO). Investigate mitigations (multi-task balancing, adapters).
- Reward modeling risks in RL: The RL stage relies on LLM-as-judge with references; assess reward hacking, judge bias, and overfitting. Incorporate programmatic/verifiable rewards and human evaluation to validate gains.
- Interleaved modality scheduling: Determine when to keep spans as text vs rendered image in interleaved training/inference for best efficiency–accuracy trade-offs. Learn a router that decides modality per span.
- Combining retrieval with compression: Explore retrieval to preselect candidate spans and allocate high-resolution rendering only to likely relevant sections. Benchmark against pure Glyph and pure RAG under equal compute.
- Theoretical capacity analysis: Develop information-theoretic models linking bits per visual token to achievable error rates, and derive upper bounds on safe compression without semantic loss for given tasks.
- Vector vs raster representations: Evaluate vector-native pipelines (PDF glyph outlines, SVG) or subpixel rendering to preserve sharpness at low “token cost,” compared to raster-only images.
- Error detection and fallback: Design uncertainty estimators to detect illegible spans (e.g., low OCR confidence) and trigger fallback strategies (higher DPI rerendering or textual ingestion).
- Data transparency: Detail the pretraining corpus (domains, languages, licenses) and analyze domain bias effects on OCR and reasoning. Provide contamination checks for benchmarks.
- Extreme-length stability and limits: While 1M-token equivalent is demonstrated, characterize stability and degradation beyond this (e.g., 2–10M), including memory scaling and failure patterns.
- Benchmarks breadth: Augment evaluation with agentic, long-horizon planning, software repository QA, legal/medical corpora, scientific papers with heavy math, and long-form safety-critical tasks.
- Fine-grained error taxonomy: Provide qualitative/quantitative error analyses (e.g., misreads vs reasoning vs layout-order errors) to inform targeted architectural or training fixes.
- Licensing and font/layout diversity: Analyze how font licensing and limited access to diverse typography/layouts constrain generalization; curate and release a diverse, permissively licensed rendering corpus.
- Open-source reproducibility of the search and training pipeline: Release search logs, seeds, exact parameter grids, and rendering code to enable independent replication and meta-analysis of configuration transferability.
Glossary
- Ablation study: An experimental method that removes or alters components to assess their impact on performance. "Ablation study comparing randomly combined, manually designed, and search-based configurations on three benchmarks under SFT setting."
- Auxiliary OCR Alignment: A training objective that aligns visual recognition with text by adding OCR-focused tasks alongside main objectives. "Throughout both SFT and RL, we therefore incorporate an auxiliary OCR alignment task that encourages the model to correctly read and reproduce low-level textual details."
- Compression ratio: The measure of how many original text tokens are represented per visual token after rendering. "To quantify the degree of compression, we define the compression ratio:"
- Content-aware encodings: Input-position encoding strategies that adapt to content to improve long-context handling. "and content-aware encodings \cite{cope,dape}."
- Continual pre-training: Additional pre-training on new data and tasks to adapt or extend model capabilities. "In the continual pre-training stage, we render large-scale long-context text into diverse visual forms,"
- Context window: The maximum number of tokens a model can accept in a single input. "scaling context windows to the million-token level brings prohibitive computational and memory costs,"
- Cross-entropy loss: A standard loss function for training generative models by maximizing likelihood of target sequences. "We minimize the cross-entropy loss"
- Decoding: The inference phase where a model generates outputs token by token. "This compression also leads to around 4× faster prefilling and decoding, and approximately 2× faster SFT training."
- Dots per inch (DPI): A rendering resolution parameter affecting visual clarity and compression. "DPI: 96 / Compression rate: average 2.2, up to 4.4"
- Genetic search: An optimization method using mutation and crossover over parameter populations to find high-performing configurations. "we design an LLM-driven genetic search to automatically explore rendering parameters (e.g. font size, layout, resolution) to maximize compression while preserving long-context ability."
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm that normalizes advantages across sampled response groups to stabilize updates. "After SFT, we further refine the policy using Group Relative Policy Optimization (GRPO)."
- Importance sampling weight: A ratio adjusting gradient updates based on the probability under current versus old policy. "We first define the importance sampling weight:"
- Interleaved Language Modeling: A training setup mixing rendered images with text spans to teach modality switching. "Interleaved Language Modeling: certain text spans are rendered as images, while the rest remain in text, training the model to switch seamlessly between modalities."
- KL divergence: A measure of how one probability distribution diverges from another, used as a regularizer in RL objectives. "-~ \beta\, D_{\mathrm{KL}!\big(\pi_\phi \,|\, \pi_{\text{SFT}\big)"
- Levenshtein distance: An edit-distance metric used to score OCR fidelity by counting insertions, deletions, and substitutions. "In the RL stage, the reward for the OCR task is given by the Levenshtein distance."
- Linear attention: An attention variant reducing quadratic complexity to near-linear in sequence length. "modifying the attention mechanism, e.g., sparse or linear attention~\cite{huang2023advancing,yang2024gated, peng2025rwkv,chen2025minimax}, which reduces the quadratic complexity of self-attention and improves per-token efficiency."
- LLM-as-a-judge: An evaluation approach where a LLM scores outputs for correctness or format. "which is a reference-based LLM-as-a-judge with the reference being the ground truth."
- LongBench: A benchmark suite evaluating long-context understanding across tasks. "Glyph attains competitive performance on LongBench and MRCR,"
- Long-context modeling: Techniques enabling models to reason over very long inputs with many tokens. "LLMs increasingly rely on long-context modeling for tasks such as document understanding, code analysis, and multi-step reasoning."
- LongLoRA: A method combining shifted sparse attention with parameter-efficient fine-tuning for long contexts. "LongLoRA~\cite{longlora} had combined shifted sparse attention with parameter-efficient fine-tuning."
- MRCR: A benchmark featuring needle-in-a-haystack challenges under varying context lengths and difficulty. "Glyph attains competitive performance on LongBench and MRCR,"
- Multimodal LLMs (MLLMs): Models that jointly process and reason over text and other modalities like images. "Multimodal LLMs (MLLMs) extend traditional LLMs to process and reason over text and visual inputs jointly."
- Needle sub-task: A challenge where specific “needle” items must be retrieved from very long contexts. "Performance comparison of our model against leading LLMs on the 4-needle and 8-needle sub-tasks of the MRCR benchmark (\%)."
- Optical character recognition (OCR): The capability to read and transcribe text from images. "An auxiliary OCR task is applied to enhance the model's ability to recognize textual content within images,"
- Parameter-efficient fine-tuning: Methods that adapt models using small sets of additional parameters rather than full model updates. "LongLoRA~\cite{longlora} had combined shifted sparse attention with parameter-efficient fine-tuning."
- Positional encodings: Techniques to encode token position information for transformers. "One line of work extends positional encodings, such as YaRN~\cite{yarn}, allowing well-trained models to accept longer inputs without additional training."
- Positional interpolation and extrapolation: Strategies that adapt positional encodings to longer or unseen lengths. "positional interpolation and extrapolation \cite{rope,alibi,xpos,yarn}"
- Prefilling: The initial inference phase where input tokens are processed before generation begins. "This compression also leads to around 4× faster prefilling and decoding, and approximately 2× faster SFT training."
- Rendering pipeline: The parameterized process that turns text into images using typography and layout settings. "The rendering pipeline parameterizes how text is visualized before being fed into the model."
- Retrieval-augmented approaches: Methods that shorten inputs by retrieving relevant context externally rather than reading all tokens. "Retrieval-augmented approaches \cite{laban2024summary,yu2025memagent} instead shorten the input length through external retrieval, but they risk missing important information and could introduce additional latency."
- Ruler benchmark: A long-context benchmark assessing performance and degradation across different lengths and tasks. "On the Ruler benchmark, Glyph also achieves performance comparable to leading LLMs across most categories (Table \ref{tab:ruler_single_header})."
- Self-attention: The mechanism enabling transformers to compute relationships among tokens within a sequence. "reduces the quadratic complexity of self-attention and improves per-token efficiency."
- Sparse attention: Attention patterns that limit interactions to a subset of tokens to reduce computation. "modifying the attention mechanism, e.g., sparse or linear attention~\cite{huang2023advancing,yang2024gated, peng2025rwkv,chen2025minimax}"
- Supervised fine-tuning (SFT): Training a model on labeled examples to specialize or improve performance. "we perform supervised fine-tuning and reinforcement learning to further improve the model's performance on visualized input,"
- Token budget: The available number of tokens for an input, constraining how much context can be processed. "This means that within the same token budget, Glyph can effectively utilize several times more original context than text-only models."
- Token compression: Reducing the number of input tokens by packing information more densely (e.g., via visual tokens). "we demonstrate that our method achieves 3–4× token compression while maintaining accuracy comparable to leading LLMs such as Qwen3-8B on various long-context benchmarks."
- UUID: A unique identifier string that is challenging for OCR in visual models due to fine-grained character fidelity. "We exclude the UUID task from this benchmark due to its huge difficulty for VLMs, which is further discussed in the limitations section."
- Vision–LLMs (VLMs): Models that jointly process visual and textual inputs for reasoning. "we propose Glyph, a framework that renders long texts into images and processes them with visionâLLMs (VLMs)."
- Visual tokens: Discrete units produced by vision encoders that represent patches or regions of an image containing text. "treating each visual token as a compact carrier of multiple textual tokensâthereby increasing the information density without sacrificing semantic fidelity."
- Visual-text compression: Representing text as images to reduce token count while preserving semantics for VLMs. "which enables long-context modeling through visual-text compression using VLMs,"
Practical Applications
Immediate Applications
Below are specific, deployable use cases that can leverage the paper’s findings on visual–text compression (Glyph) today, with explicit sector links, potential tools/workflows, and feasibility notes.
- Long-document Q&A and summarization at scale
- Sector: Legal, Finance, Government, Publishing, Academia
- Tools/Workflows: A “Glyph renderer” API that converts PDFs/HTML/long text into compact images, paired with a 128K-context VLM for cross-page Q&A, summarization, and policy/contract analysis; batch processing pipelines for compliance scans (e.g., multi-Doc QA over 10-K filings or regulations)
- Value: 3–4× token compression with competitive accuracy; faster prefilling/decoding (≈4×) reduces latency and cost
- Assumptions/Dependencies: Requires a capable VLM with large visual token context (e.g., 128K); optimal rendering configuration found via the genetic search; OCR fidelity sufficient for non-UUID, non-rare-character text
- Enterprise knowledge assistant with attachment-aware long-context
- Sector: Enterprise software, Knowledge management
- Tools/Workflows: Chat assistants that accept long reports, policy decks, and manuals in rendered form to enable whole-document reasoning without truncation; “compression-aware context packer” that auto-selects DPI/font/layout per document type
- Value: Maintains coverage of entire document sets under fixed context windows
- Assumptions/Dependencies: Integration with existing VLM backbones; governance for sensitive content handling
- Accelerated model fine-tuning and inference for LLM/VLM teams
- Sector: AI/ML engineering
- Tools/Workflows: Use Glyph to cut input tokens in SFT, achieving ≈2× faster training throughput; deploy visual compression during inference for long-context tasks to reduce memory/compute
- Value: Lower training costs and faster iteration cycles
- Assumptions/Dependencies: Access to training data that can be rendered; compatibility with GRPO/RL setup and OCR auxiliary loss
- Document-understanding pipelines for multi-page PDFs
- Sector: Document AI, OCR, RPA (Robotic Process Automation)
- Tools/Workflows: Replace or augment traditional OCR with VLM-driven understanding on rendered pages; cross-page QA for forms and reports; layout-aware reasoning using style themes (document_style, web_style, code_style)
- Value: Demonstrated gains on MMLongBench-Doc; robust cross-page reasoning without bespoke OCR-only pipelines
- Assumptions/Dependencies: Adequate image resolution and layout rendering; limited performance on UUIDs or rare alphanumeric sequences
- Policy and regulatory analysis across large corpora
- Sector: Public policy, Legal/regulatory compliance
- Tools/Workflows: Ingest multi-thousand-page bills, public comments, and guidance; run multi-document queries, summaries, contradiction checks
- Value: Efficiently process entire legislative packages within fixed context budgets
- Assumptions/Dependencies: Quality OCR alignment; access to authoritative ground truths for verification (LLM-as-judge optional)
- Financial research and due diligence
- Sector: Finance, Investment, Risk
- Tools/Workflows: End-to-end analysis of earnings calls, filings, and research notes; “compression-aware filing reader” that supports cross-document tracing and risk summarization
- Value: Reduced inference time and improved coverage of long investor materials
- Assumptions/Dependencies: Reliable rendering of tables and footnotes; context budget sufficient for multiple reports
- Academic literature review and grant/proposal evaluation
- Sector: Academia, R&D management
- Tools/Workflows: Render entire books, theses, and multi-paper bundles; Q&A over global context (e.g., who supported Jane in “Jane Eyre”) without truncation
- Value: Better fidelity in multi-hop reasoning over long texts
- Assumptions/Dependencies: High-DPI fallback improves fidelity; domain formatting may need tailored rendering presets
- Codebase and log analysis for long-context tasks
- Sector: Software engineering, DevOps
- Tools/Workflows: Render long code files or aggregated logs into images for cross-file reasoning; search for needles across large contexts (MRCR-like tasks)
- Value: Process larger scopes within fixed token budgets; competitive accuracy with compression
- Assumptions/Dependencies: Code-style rendering tuned to preserve indentation/line markers; careful handling of monospaced fonts/resolution to maintain syntax cues
- On-device or constrained-hardware assistants for long documents
- Sector: Mobile, Edge AI
- Tools/Workflows: Use token compression to fit longer inputs on devices with limited memory; document Q&A for mobile knowledge workers
- Value: Practical long-context experiences on limited hardware
- Assumptions/Dependencies: Efficient VLM deployment on-device; image rendering pipeline optimized for mobile
- Hybrid RAG with compression-first ingestion
- Sector: AI applications, Search
- Tools/Workflows: Pre-render full documents and allow the model to operate with near-complete coverage; selectively retrieve only when compression won’t preserve critical details
- Value: Lower risk of retrieval omissions; reduced latency vs. complex retrieval chains
- Assumptions/Dependencies: Careful coordination between compression and retrieval; query-aware rendering beneficial but optional
Long-Term Applications
These use cases require further research, scaling, or ecosystem development (e.g., adaptive rendering, better OCR fidelity, larger context windows, or sector-specific standards).
- Adaptive, task-aware rendering for optimal accuracy–compression trade-offs
- Sector: AI infrastructure, Context engineering
- Tools/Workflows: A “rendering policy” that dynamically sets DPI/layout/fonts per query/document section; plug-in that learns to allocate high DPI to critical spans and lower DPI elsewhere
- Dependencies: Learning robust policies; runtime orchestration; improved visual encoders
- Million-to-ten-million token equivalent contexts via extreme compression
- Sector: Advanced AI assistants, Research copilots
- Tools/Workflows: Scaling from 1M to 10M “effective” tokens by combining 8× compression with future encoders; whole-corpus reasoning without chunking
- Dependencies: Model architecture upgrades; memory-efficient VLMs; stronger OCR for edge cases (UUIDs, rare strings)
- Agent memory systems with long-term conversational and document context
- Sector: Agentic AI, CX automation
- Tools/Workflows: Agents that retain full conversation history, policies, and documents as compressed pages; reasoning over multi-session narratives and customer records
- Dependencies: Persistent, query-aware context management; privacy controls; adaptive rendering
- Whole-patient longitudinal EHR and guideline integration
- Sector: Healthcare
- Tools/Workflows: Clinical decision support that reads multi-year records, imaging reports, and guidelines compressed into visual pages; cross-document evidence tracing
- Dependencies: Strict privacy and security; medical OCR precision; clinical validation and regulatory approval
- Governance-scale document analysis (e.g., public comments, FOIA releases)
- Sector: Government, Civic tech
- Tools/Workflows: Automated synthesis of millions of pages into issue maps, contradictions, stakeholder summaries
- Dependencies: Compute scaling; transparency standards; public-sector procurement and standardization
- Repository-scale code understanding and refactoring assistance
- Sector: Software engineering
- Tools/Workflows: Global codebase reading (multi-repo) under compressed contexts; cross-file dependency reasoning and semantic refactors
- Dependencies: High-fidelity code rendering; integration with build systems; precise evaluation
- Layout-aware semantic retrieval and indexing over visual pages
- Sector: Search, Enterprise content management
- Tools/Workflows: “Visual-index” stores features from rendered pages (tables, figures, footnotes) for retrieval; cross-modal search blending text and layout cues
- Dependencies: New index formats; feature storage standards; query engines that exploit layout signals
- Standards for “LLM-friendly” document formats (Glyph-PDF)
- Sector: Publishing, Document AI
- Tools/Workflows: A document standard optimized for machine reading (fonts, spacing, DPI metadata) to minimize ambiguity
- Dependencies: Industry adoption; backward compatibility; accessibility compliance
- Hardware–model co-design for glyph-centric reading
- Sector: Semiconductors, Edge AI
- Tools/Workflows: Vision encoders specialized for textual glyphs; low-power accelerators tuned for page-level processing
- Dependencies: Co-design cycles; ecosystem support; benchmarking suites
- Privacy-preserving document compression
- Sector: Security, Compliance
- Tools/Workflows: Rendering that reduces human legibility while maintaining machine readability for confidential workflows; secure enclaves for image processing
- Dependencies: Robust OCR-to-comprehension alignment; legal standards; auditability
- Education: interactive, compression-aware textbooks and study platforms
- Sector: Education/EdTech
- Tools/Workflows: Platforms that render entire textbooks and problem sets in optimized layouts for AI tutors; cross-chapter reasoning and exam prep
- Dependencies: Curriculum alignment; explainability; teacher-in-the-loop protocols
- Cross-modal analytics on reports combining text, tables, and figures
- Sector: Consulting, Energy, Manufacturing
- Tools/Workflows: Unified analysis of technical reports where tables/diagrams are embedded; multi-hop reasoning that exploits layout and visuals
- Dependencies: Better multimodal training on technical layouts; domain-specific evaluation
General Assumptions and Dependencies (applicable across many use cases)
- Availability of a strong VLM with large visual-token context (e.g., ≈128K), and support for page sequences.
- Robust OCR-like alignment within the VLM; UUIDs and rare alphanumerics remain challenging and may require specialized modules.
- Effective rendering configuration discovered via the LLM-driven genetic search; performance is sensitive to DPI/layout/fonts.
- Data security, privacy, and compliance controls for sensitive documents (health, finance, legal).
- Compute resources for batching/serving rendered inputs; potential need for high-DPI fallback at inference time for critical spans.
- Domain-specific validation and calibration (e.g., clinical, legal) to ensure trustworthy outputs.
Collections
Sign up for free to add this paper to one or more collections.