- The paper introduces Vist, which uses a vision encoder on text images to compress tokens in LLMs.
- Vist employs a frequency-based masking strategy to emphasize semantically critical tokens, achieving a 50% reduction in memory usage.
- Comparative analysis reveals that Vist outperforms traditional text-based methods by 5.7% on benchmarks like TriviaQA and NQ.
Vision-centric Token Compression in LLMs
The paper "Vision-centric Token Compression in LLM" (2502.00791) introduces an innovative approach to reducing computational inefficiencies in LLMs by leveraging vision-based techniques. This method challenges traditional reliance on text encoders by utilizing a vision encoder to process textual inputs, achieving competitive results with reduced resource consumption.
Introduction
LLMs have transformed natural language processing, particularly in handling extended sequences. However, the inefficiency in processing large quantities of in-context tokens persists. Traditional methods aimed at token compression often depend on smaller text encoders, but this paper proposes an unconventional approach by employing visual encoders directly on text sequences. The core idea is to render text as images and process them through a vision encoder, thus bypassing the need for language-specific tokenization and reducing the overall number of tokens processed.
Methodology
The proposed method, named Vist, converts long text sequences into images. These images are processed using a lightweight vision encoder, which results in a significant reduction of token count, improving computational efficiency.
Token Compression Strategy
Vist aims to address the problem of token redundancy in LLMs. The key innovation lies in applying a vision encoder to text rendered as images, leading to fewer FLOPs and reduced memory usage by 50% compared to traditional text encoders. The approach includes a frequency-based masking strategy to focus on critical tokens, such as important nouns and verbs, while minimizing the role of less informative tokens like prepositions and conjunctions.
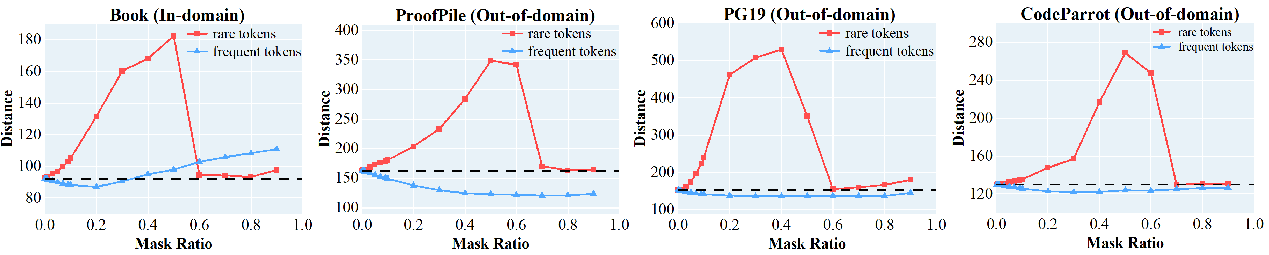
Figure 1: Effect of frequent vs. rare tokens on semantic integrity. Masking rare tokens (red) significantly disrupts semantic representation, increasing text-visual embedding distance, while masking frequent tokens (red) has minimal impact, demonstrating that rare tokens are critical for preserving semantic meaning.
Comparative Analysis
Compared to traditional token compression methods, Vist sets a new standard by outperforming text encoder-based approaches by an average of 5.7% across benchmarks like TriviaQA, NQ, and others. Moreover, the vision-centric approach demonstrates robustness across multiple text understanding tasks, achieving comparable results with significantly reduced computational requirements.
Implications and Future Work
The implications of this research are multifaceted. Practically, the adoption of vision-based token processing can lead to more efficient LLMs with broader applications in various fields requiring long-context understanding, such as document summarization and conversational AI. Theoretically, it opens up new avenues for the integration of visual processing techniques in LLMs, challenging the conventional paradigm of text processing.
Future research may explore expanding this approach to other domains or enhancing the visual encoder's capability to process more diverse and complex texts. Additionally, exploring the integration with memory-augmented architectures could further extend the context windows of LLMs.
Conclusion
The innovative approach presented in this paper leverages vision encoders for token compression in LLMs, leading to improved efficiency and performance. By reducing token redundancy and focusing on semantically rich tokens, this method paves the way for future research in efficient LLM architectures that can handle even longer contexts with reduced computational overhead.