- The paper demonstrates a modular framework integrating image, population, and environmental models to significantly enhance predictive accuracy in geospatial intelligence.
- It employs specialized remote sensing models—including VLMs, OVD, and a ViT backbone—for robust zero-shot and few-shot performance on benchmark datasets.
- Geospatial reasoning via a Gemini-powered agent enables automated, multi-step analysis, yielding notable improvements in FEMA risk and CDC health predictions.
Earth AI: Foundation Models and Agentic Reasoning for Geospatial Intelligence
Introduction and Motivation
The "Earth AI" framework addresses the longstanding challenge of extracting actionable insights from heterogeneous, high-volume geospatial data. Traditional geospatial analysis has been hampered by siloed data sources, disparate modalities (imagery, population, environment), and the lack of scalable, generalizable models. Earth AI proposes a modular, multi-modal system built on specialized foundation models for imagery, population, and environmental signals, orchestrated by a Gemini-powered geospatial reasoning agent. This architecture enables both expert and non-expert users to perform complex, multi-step geospatial analyses, bridging the gap between raw data and decision-ready intelligence.
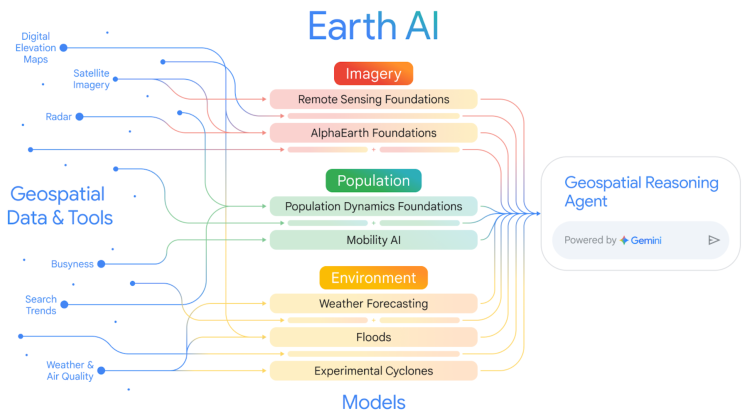
Figure 1: Earth AI integrates diverse geospatial data and models across imagery, population, and environment, unified by a geospatial reasoning agent for comprehensive analysis.
Core Foundation Models
Remote Sensing Foundation Models
Earth AI's Remote Sensing (RS) Foundation Models are designed to overcome the unique challenges of Earth observation, such as limited labeled data and domain-specific image distributions. The RS suite includes:
- Vision-LLMs (VLMs): Trained on large-scale, Gemini-captioned aerial/satellite imagery, these models map images and text into a joint embedding space, enabling zero-shot classification and retrieval with natural language prompts.
- Open-Vocabulary Object Detection (OVD): Built on OWL-ViT v2, the RS-OVD model supports detection of arbitrary object categories, with few-shot adaptation via FLAME for rapid domain transfer.
- General-Purpose Vision Transformer (ViT) Backbone: Pre-trained on 300M+ remote sensing images using a two-stage MAE and multi-task protocol, this backbone demonstrates strong generalization across classification, detection, and segmentation tasks.
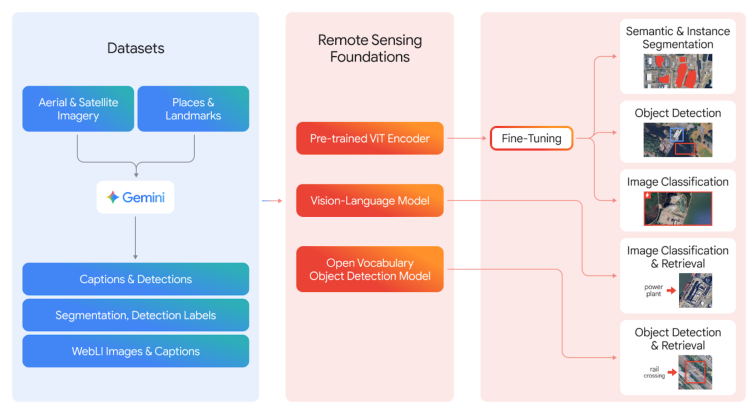
Figure 2: Training and deployment pipeline for RS Foundation Models, leveraging Gemini-generated captions and multi-source imagery for VLM, OVD, and ViT backbone training.
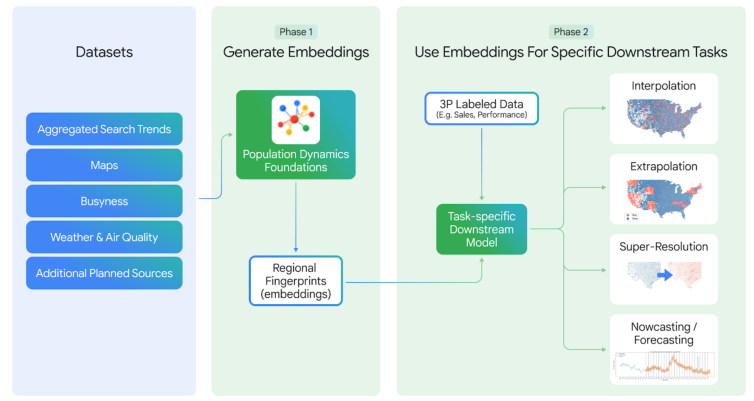
Population Dynamics Foundations
The Population Dynamics Foundations (PDFM) model encodes the spatiotemporal dynamics of human populations by integrating maps, search trends, mobility, and environmental data into privacy-preserving regional embeddings via a GNN architecture. Key advances include:
Environment Models
Earth AI incorporates operational weather, flood, and cyclone forecasting models, including MetNet and stochastic neural network-based cyclone prediction, providing high-resolution, real-time environmental signals for integration with other modalities.
Model Synergy and Predictive Applications
A central claim of Earth AI is that combining complementary foundation models yields superior predictive performance compared to single-modality approaches. This is empirically validated across multiple domains:
- FEMA Risk Prediction: Integrating AlphaEarth (imagery/topography) and PDFM (socioeconomic) embeddings yields an average 11% R2 improvement over single-model baselines for 20 FEMA risk indices.
- CDC Health Statistics: Joint embeddings improve R2 by 7% over PDFM alone and 43% over AlphaEarth alone for 21 health indicators.
- Disaster Damage Forecasting: For Hurricane Ian, the combined cyclone forecast, building data, and PDFM model predicted the number of damaged buildings within 3% of ground truth three days before landfall.
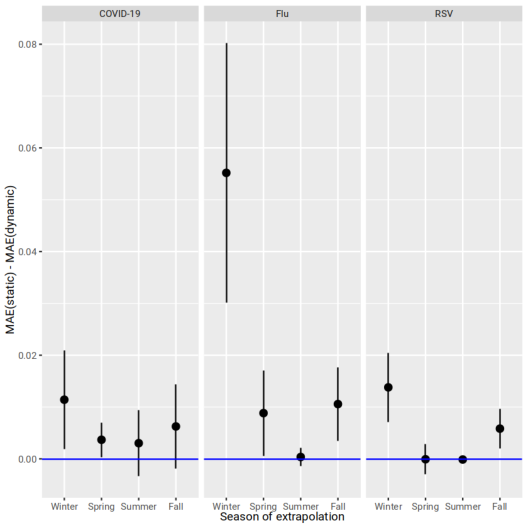
Figure 4: Dynamic (time-matched) PDFM embeddings consistently reduce mean absolute extrapolation error for monthly disease visit forecasting compared to static embeddings.
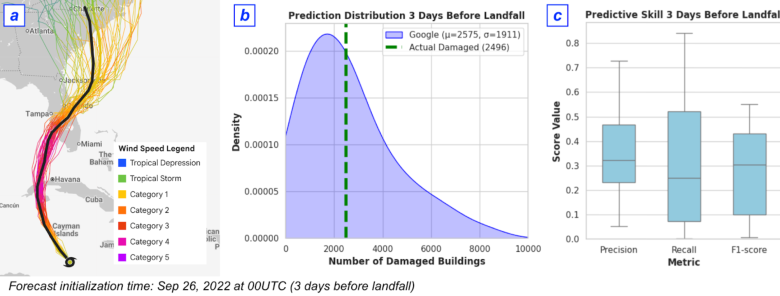
Figure 5: Cyclone damage forecasting pipeline and performance for Hurricane Ian, demonstrating high-fidelity prediction of damaged buildings using multi-modal inputs.
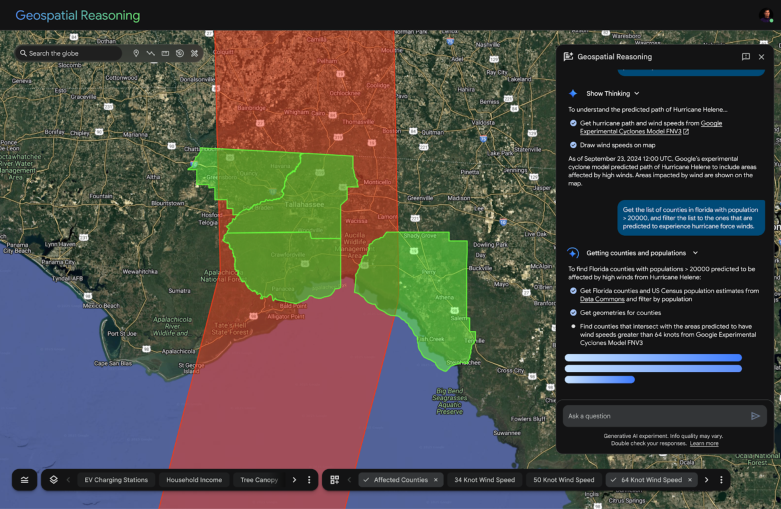
Geospatial Reasoning Agent: Orchestration and Automation
The Gemini-powered Geospatial Reasoning Agent operationalizes the integration of foundation models and data sources. It decomposes complex queries into sub-tasks, selects appropriate models/tools, and synthesizes results through an iterative Think-Plan-Act-Reflect loop.
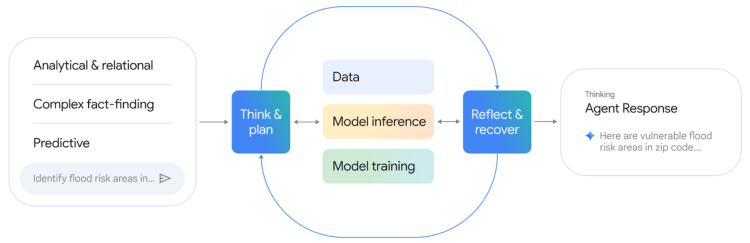
Figure 6: Closed-loop operational framework for the Geospatial Reasoning Agent, supporting analytical, fact-finding, and predictive queries.
The agent architecture is modular, with domain-specific expert sub-agents (e.g., for imagery, population, environment) and general-purpose tools (e.g., code generation, Earth Engine access). This enables extensibility and robust orchestration across diverse geospatial tasks.
Evaluation and Empirical Results
Foundation Model Benchmarks
- RS VLMs: Achieve SOTA zero-shot classification and retrieval on FMOW, SkyScript, RESISC45, and other benchmarks, outperforming larger models such as GeoChat (7B) and LHRS-Bot (7B).
- RS OVD: RS-OWL-ViT-v2 achieves 31.8% mAP (DOTA) and 29.4% mAP (DIOR) in zero-shot; FLAME-augmented few-shot adaptation boosts mAP to 54%+.
- ViT Backbone: RS-Global MTP backbone surpasses Dino V2 and SigLIP2, with a 14.9% average improvement over ImageNet pretraining across 13 downstream tasks.
Population Dynamics Foundations
- Global Interpolation: PDFM embeddings achieve mean R2 of 0.85 across 17 countries for elevation, night lights, population density, and tree cover.
- Cross-country Extrapolation: PDFM outperforms IDW and RBF for GDP, death rate, and fertility rate prediction in held-out countries.
- Temporal Embeddings: Dynamic PDFM reduces MAE for disease visit forecasting, especially during high-burden months.
Model Synergy
- FEMA Risk and Health Prediction: Joint embeddings consistently outperform single-modality models.
- Cholera Forecasting (DRC): Adding PDFM and weather covariates to TimesFM reduces RMSE by 34% over baseline Prophet.
Agentic Reasoning Benchmarks
Implementation Considerations
- Data Integration: All foundation models are designed for modularity, with embeddings and APIs accessible for downstream tasks. Aggregation across spatial/temporal scales is handled via area-weighted averaging and histogram-based feature extraction.
- Agent Framework: The agent is implemented using Google's ADK, with Gemini 2.5 Pro/Flash as the LLM backbone. Domain-specific sub-agents are encapsulated for extensibility.
- Resource Requirements: Training RS foundation models requires large-scale compute (hundreds of millions of images), but inference and downstream fine-tuning are tractable on standard cloud infrastructure.
- Privacy: PDFM embeddings are constructed with privacy-preserving aggregation, including Knowledge Graph entity mapping for search trends.
- Limitations: Current RS models focus on high-res RGB imagery; temporal and multi-sensor support is a target for future work. Model alignment across spatial/temporal granularities remains a challenge for unified meta-models.
Implications and Future Directions
Earth AI demonstrates that compositional, multi-modal geospatial AI systems can deliver state-of-the-art performance and enable new classes of automated, agentic analysis. The empirical results support the claim that model synergy—rather than monolithic, single-modality models—is critical for robust, generalizable geospatial intelligence.
Future research directions include:
- Unified Meta-Earth Models: Training a single model across imagery, population, and environment for shared multi-modal representations.
- Temporal and Multi-sensor Expansion: Extending RS models to support temporal tasks and additional sensor modalities (e.g., SAR, hyperspectral).
- Generalized Fusion Methods: Developing more automated, variable-agnostic fusion strategies for embedding integration.
- Robust Agentic Evaluation: Expanding benchmarks to include out-of-distribution and failure-mode scenarios, with human expert review.
Conclusion
Earth AI establishes a scalable, extensible paradigm for geospatial AI, combining specialized foundation models with agentic reasoning to automate complex, multi-modal analysis. The demonstrated gains in predictive accuracy, robustness, and accessibility suggest that integrated, orchestrated ecosystems will define the future of geospatial intelligence, with broad implications for crisis response, public health, environmental monitoring, and beyond.