- The paper finds that optimal sequence length varies by task and model, challenging a one-size-fits-all approach by showing shorter and longer sequences perform best in different scenarios.
- The methodology systematically varied sequence lengths from 64 to 8192 tokens across OPT and Mamba models to compare training efficiency and performance on multiple language tasks.
- The results offer actionable guidelines for resource-constrained training, balancing computational efficiency with effective task-specific performance.
Optimal Sequence Length for BabyLM: A Technical Analysis
Introduction
The research paper "What is the Best Sequence Length for BABYLM?" (2510.19493) critically examines the effects of sequence length on the training of Transformer-based LLMs within the context of the BabyLM Challenge. This challenge uniquely constrains models to a 100M-token corpus to evaluate the effects of various sequence lengths on model training. This study specifically compares the Open Pre-Trained Transformer (OPT) and Mamba models, examining how different sequence lengths impact performance across various tasks typical of LLM evaluations.
Sequence Length Considerations
The paper argues that longer sequence lengths generally contribute to training efficiency by allowing models to process more tokens per update, thus enhancing the learning signal and reducing gradient noise. However, when data is limited, shorter sequences might be preferable due to more frequent updates despite noisier gradient estimates. This nuanced approach leads to the first research question: what is the optimal sequence length for different evaluation tasks in the BabyLM setting? Additionally, the paper explores whether this optimal length varies with model architecture, specifically between OPT and Mamba models.
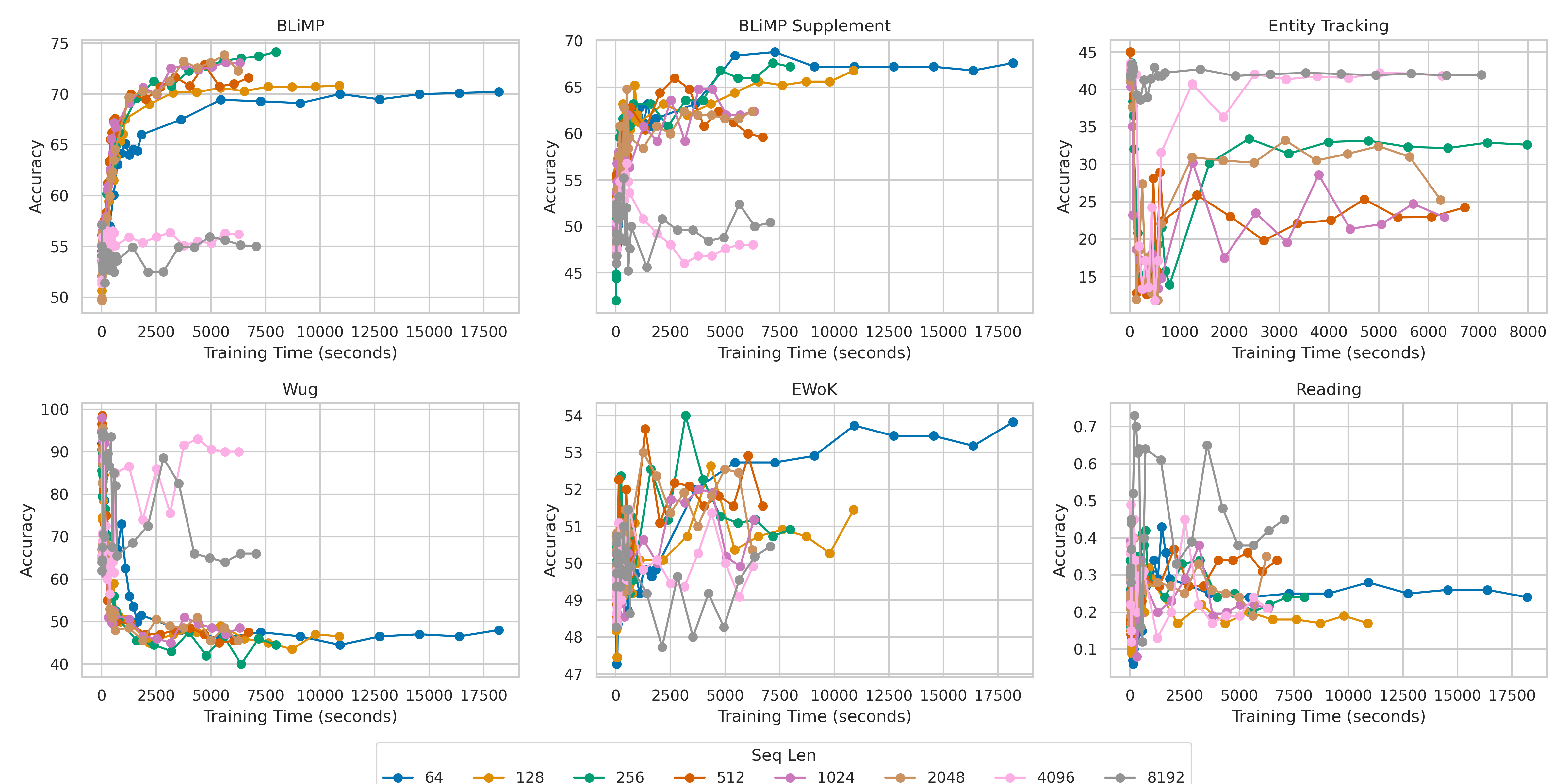
Figure 1: OPT Model Families: Effect of Sequence Length Accuracy vs Training Time per Metric. Evaluation of OPT 125M Family trained on 100M Strict BabyLM Corpus with Warmup with a range of sequence lengths {64,128,256,512,1024,2048,8192}.
Methodology
The study utilizes a broad range of sequence lengths from 64 to 8192 tokens to train two families of BabyLM models — OPT and Mamba. Mamba offers an advantage in potentially handling long sequences more efficiently due to its state-space model architecture, differing from the vanilla Transformer structure. Sequence lengths are systematically varied, with training configurations adjusted accordingly, to identify the sequence length L∗ that achieves the highest score with minimal computational time. The evaluation is performed over multiple tasks present in the BabyLM Evaluation Pipeline, including grammatical and morphological reasoning tasks.
Results and Analysis
The results reveal that the optimal sequence length is task and model-dependent. For tasks such as BLiMP and BLiMP Supplement, shorter sequences of up to 256 tokens proved more effective, consistently outperforming longer sequences. Conversely, tasks like Entity Tracking and Wug demanded longer sequences to capture the necessary context for effective reasoning, benefiting from sequences as long as 8192 tokens for OPT models.
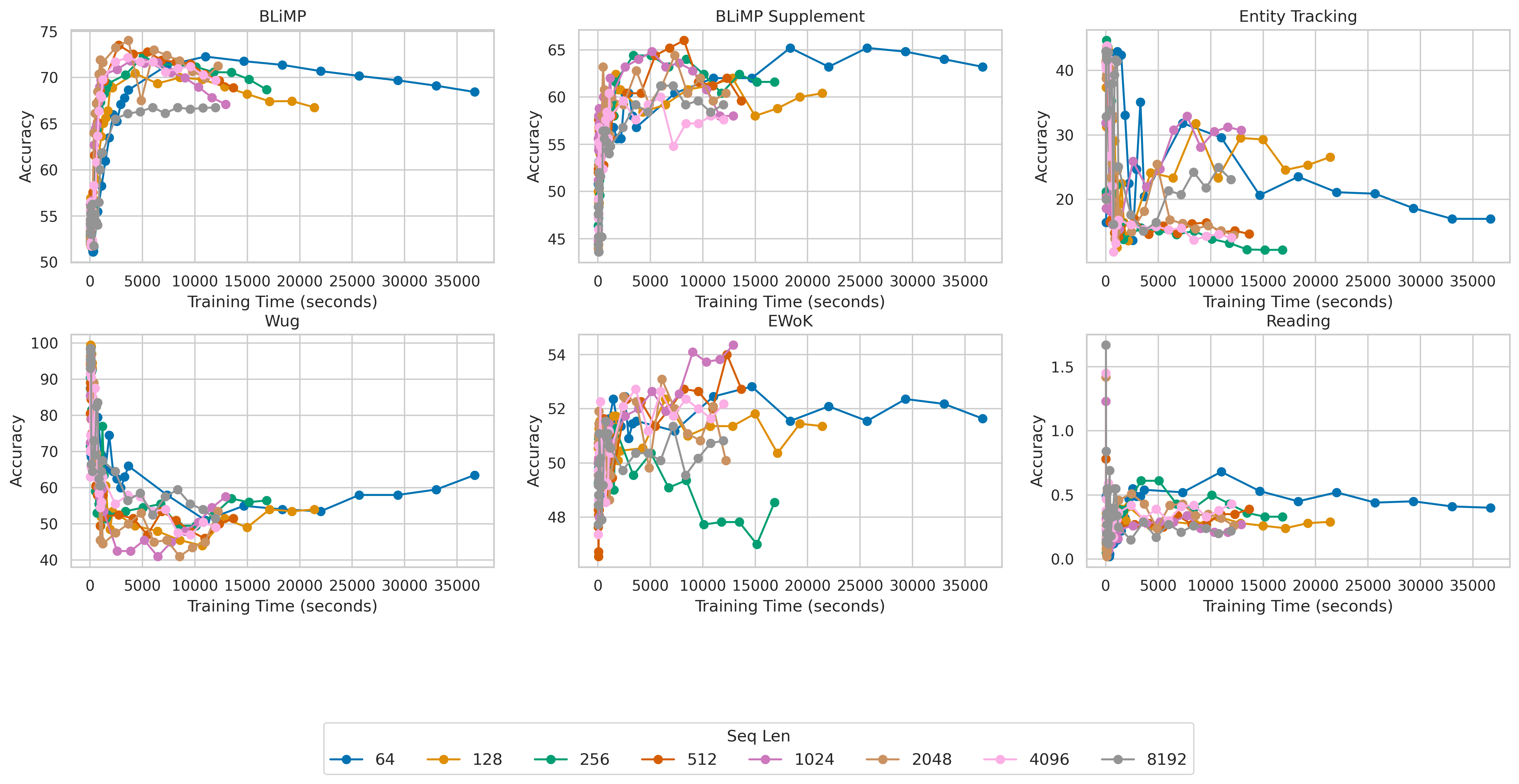
Figure 2: Mamba Model Families: Effect of Sequence Length Accuracy vs Training Time per Metric.
Interestingly, while the OPT model favored a broader range of sequence lengths, Mamba achieved its peak performance with shorter lengths (64 to 1024 tokens) across many tasks, indicating that it efficiently harnesses its architectural capabilities to capture context without requiring excessively long sequences.
Implications
The findings challenge the simplistic view that longer sequence lengths universally enhance Transformer model performance, revealing instead the critical role of task-specific tuning in sequence length for both complexity and computational efficiency. By identifying the training-optimal lengths, the study provides a robust framework for resource-efficient model development in constrained data environments, aligning with the BabyLM Challenge's low-resource mandate.
These insights are pivotal for practitioners aiming to balance training performance and computational resources, particularly when deploying models in environments with strict data or compute constraints. Given the practical implications, the recommended sequence lengths based on architecture and task provide a tangible starting point for optimizing training configurations in both research and application-focused settings.
Conclusion
The study offers a comprehensive evaluation of the interplay between sequence length, model architecture, and task specificity in the context of the BabyLM Challenge. The observed task-dependent sequence length optimality underscores the need for nuanced training strategies rather than a one-size-fits-all approach. This paper contributes to our understanding of how small alterations in sequence processing can yield substantial improvements in training efficiency and performance, providing valuable guidance for future advancements in LLM pretraining under constrained conditions.