- The paper demonstrates that language models can be pre-trained efficiently on less than 100 million words from child-directed corpora, achieving competitive performance.
- It employs three data-restricted tracks with evaluations on tasks like BLiMP, GLUE fine-tuning, and bias assessments to benchmark model capabilities.
- The findings imply that cognitive-inspired training methods can democratize LM research by reducing resource demands while aligning with human linguistic development.
Findings of the BabyLM Challenge: Sample-Efficient Pretraining on Developmentally Plausible Corpora
Overview
This paper details the results and implications of the BabyLM Challenge, a communal effort to optimize LLM training on a fixed data budget resembling the input quantity experienced by human language learners. Unlike modern LMs, which rely on vast datasets, the challenge aimed to train models using corpora consisting of less than 100 million words, focusing on creating developmentally plausible training conditions that mimic human linguistic input exposure.
Motivation
Modern LLMs require orders of magnitude more data than human learners and yet fail to match human performance on many evaluations. This discrepancy highlights two questions: how do humans learn language so efficiently, and how can this efficiency be replicated in LMs? The BabyLM Challenge addresses the need for data-limited training to build cognitively plausible models of language acquisition, optimize training protocols before scaling, and democratize LLM research by reducing resource demands.
Methodology
Participants could submit models to three tracks—Strict, Strict-Small, or Loose—based on the data restrictions of the corpora used. The pretraining corpora drew from sources mirroring environments in which children learn, such as child-directed speech, dialogue, and children's literature, curated to maintain developmental plausibility in size and domain.
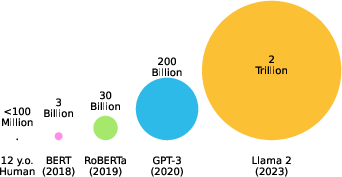
Figure 1: Data Scale: Modern LLMs are trained multiple orders of magnitude more word tokens than the amount available to a typical child, illustrating disparity between human and LM learning environments.
Models were evaluated using tasks targeting grammatical ability, downstream performance, and generalization. Metrics included zero-shot evaluations on BLiMP, finetuning tasks from GLUE, and assessments of model bias through MSGS.
Results and Analysis
Analysis of over 30 submissions revealed that certain architectures, particularly the LTG-BERT model, outperformed existing models trained on trillions of words. ELC-BERT, which incorporates optimizations such as disentangled attention and scaled weight initialization, demonstrated superior score aggregation across all tracks.
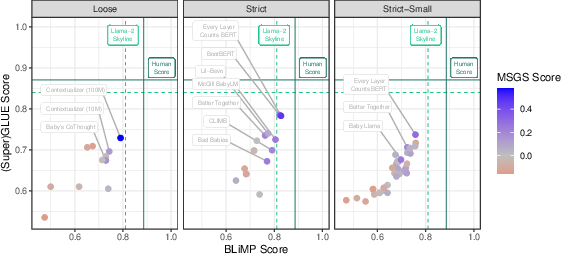
Figure 2: Summary of BabyLM Submission Results: Each point represents an official model submission with performance breakdown across BLIMP, GLUE, and MSGS.
Despite curriculum learning being attempted widely, it seldom led to substantial improvements, suggesting that these approaches might not yet be optimized for the nuances of human-like learning scenarios.
Implications
The BabyLM Challenge highlights the potential to enhance data-efficiency in LLMs and aligns LM development with cognitive modeling principles. Winning submissions suggest avenues where modifications in LM architecture—particularly those informed by human learning processes—can advance performance within data-restricted environments.
Future Directions
The success and insights garnered from the current BabyLM Challenge iteration underscore the possibility for future iterations to trial harder evaluations and explore areas such as multimodality and compute efficiency. Enhancing the evaluation pipeline, perhaps through greater community involvement, could support diverse submissions not confined to HuggingFace implementations.
Conclusion
The BabyLM Challenge has set a precedent for research into sample-efficient training of LLMs, fostering innovations in their architecture and data processing. The initiative has brought to light methods that harmonize machine learning with cognitive patterns, paving the path toward models that better approximate human linguistic behavior.
