olmOCR 2: Unit Test Rewards for Document OCR
Abstract: We present olmOCR 2, the latest in our family of powerful OCR systems for converting digitized print documents, like PDFs, into clean, naturally ordered plain text. olmOCR 2 is powered by olmOCR-2-7B-1025, a specialized, 7B vision LLM (VLM) trained using reinforcement learning with verifiable rewards (RLVR), where our rewards are a diverse set of binary unit tests. To scale unit test creation, we develop a pipeline for generating synthetic documents with diverse and challenging layouts, known ground-truth HTML source code, and extracted test cases. We show that RL training on these test cases results in state-of-the-art performance on olmOCR-Bench, our English-language OCR benchmark, with the largest improvements in math formula conversion, table parsing, and multi-column layouts compared to previous versions. We release our model, data and code under permissive open licenses.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
What’s this paper about?
This paper introduces olmOCR 2, a smart system that turns tricky PDF pages (like research papers and scanned documents) into clean, well-ordered text. It uses a vision-LLM (a kind of AI that looks at images and writes text) and a special training method that rewards the model for passing simple, automatic “checks” about whether it read the page correctly.
Key Questions
What were the researchers trying to figure out?
- How can we train an AI to read complex documents (with formulas, tables, and multiple columns) more accurately?
- Can we use simple, pass/fail tests—like a checklist—to give the AI reliable feedback during training?
- Will this approach beat other OCR systems on a tough benchmark?
Methods and Approach
Breaking down the main ideas in everyday language
- OCR: Stands for Optical Character Recognition. It’s how computers read text from images or PDFs.
- Vision-LLM (VLM): An AI that looks at an image and writes text about it. Think of it as a “see-and-say” machine.
- Reinforcement Learning with Verifiable Rewards (RLVR): Training the AI like a video game. The model tries to read a page; then we grade it using simple tests. If it passes more tests, it earns a higher score and learns to do better next time.
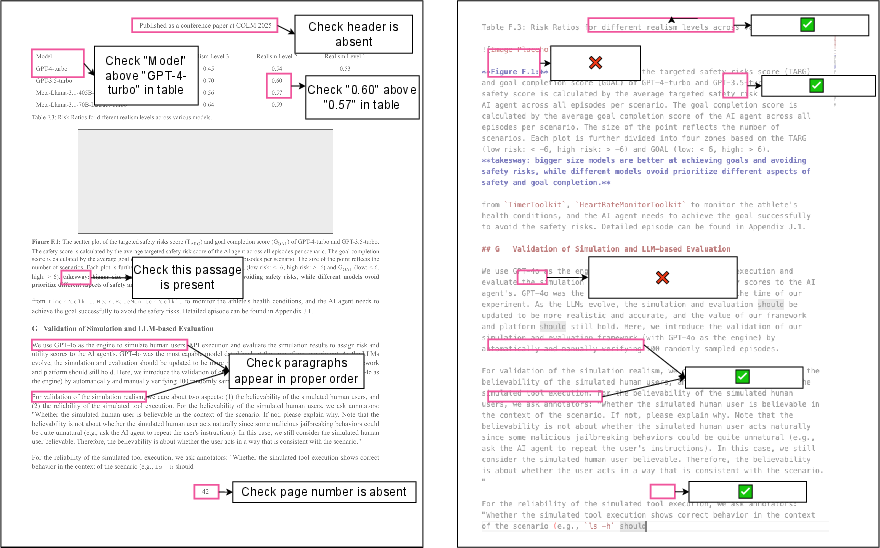
- Unit Tests: Small, automatic checks. They’re like yes/no questions that verify parts of the output. Example: “Is this sentence present?” “Is the table cell in the right place?” “Do the math formulas render correctly?”
How they built the training data
Instead of only using hand-made examples (which is slow), they created a pipeline to generate lots of reliable training cases:
- They picked real, tough pages from PDFs (like math-heavy papers) to get realistic challenges.
- A general AI model recreated each page as clean HTML (the language websites use). The HTML is like a blueprint of the page’s structure—headers, footers, columns, tables, and formulas.
- Using that HTML, they automatically made many unit tests. For example:
- Text Presence: “Does this exact sentence appear?”
- Text Absence: “Did we successfully remove headers/footers?”
- Reading Order: “Are sentences in the natural reading order?”
- Table Accuracy: “Is a specific cell located in the correct row/column?”
- Math Formula Accuracy: “Does the formula display correctly when rendered?”
- Robustness: “Does the output avoid weird repeats or wrong-language characters?”
Because the tests come from the HTML “ground truth,” they’re easy to check and very reliable.
How they trained the model
- Base model: A 7-billion-parameter vision-LLM specialized for OCR.
- Training style: The model tried reading each synthetic page many times. Each try got a score: the fraction of unit tests it passed (0 to 1).
- Extra format rewards: Bonus points for finishing properly (ending the output correctly) and including a small block of metadata at the top.
- GRPO: A specific reinforcement learning method that helps the model improve based on those scores.
- Model “souping”: They trained six versions of the model and averaged their weights. Think of it like blending several good models to get a more stable, stronger one.
- Practical tuning: They improved details like image size, prompting style, and output format (switching from JSON to YAML to reduce errors and loops).
Main Findings
What did they discover, and why does it matter?
- State-of-the-art performance: olmOCR 2 scored highest or near-highest on their benchmark, especially on math formulas, tables, and multi-column pages—areas where OCR usually struggles.
- Big improvement over their first release: About +14 points overall on their benchmark within six months.
- Unit tests work great for training: Using simple pass/fail checks as rewards made reinforcement learning very effective. It helped the model learn “what counts as correct” in a practical sense.
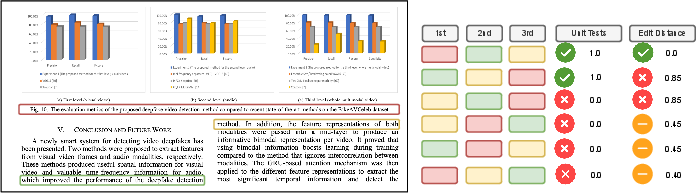
- Better than using “edit distance” alone: Edit distance is a score that counts how many changes you need to turn one text into another. It can be misleading for documents. For example:
- Caption placement: A caption could appear before or after the main text and still be correct. Unit tests can treat these as equally right; edit distance might unfairly punish one.
- Math formulas: Two different LaTeX strings can render to the same visual equation. Unit tests check how it displays, which is what readers care about.
Why it’s important
Accurate OCR helps:
- Students and researchers search and reuse information from PDFs.
- Accessibility tools read documents out loud in the right order.
- Data analysis systems extract tables and formulas correctly.
- Companies digitize reports without losing structure or meaning.
Implications and Impact
What could this change in the future?
- Better document understanding: Systems can more reliably bring structure (headings, columns, tables) and content (formulas, text) into plain, usable formats.
- Open science: The team released the model, data, and code under permissive licenses, so others can build on their work.
- Smarter training: Using unit tests as rewards can guide AI learning in a way that matches real-world correctness, not just string similarity.
- Next steps: They plan to expand their synthetic pipeline to cover even more document types and explore when unit tests vs continuous scores are best for both evaluating and training OCR systems.
Overall, the paper shows a practical, clever way to teach AI to read complex documents more accurately by giving it clear, pass/fail goals—and it works.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a consolidated list of specific gaps and unresolved questions left by the paper that future work could address:
- Multilingual generalization: No evaluation on non-English scripts (CJK, Arabic/Hebrew RTL, Devanagari), mixed-script pages, vertical text, or non-Latin numerals; extend unit tests and benchmark to multilingual scenarios.
- Handwriting and annotations: No coverage of handwriting, marginalia, stamps, signatures, or pen markings common in scanned archives.
- Camera-captured documents: Generalization to mobile photos, perspective distortion, shadows, glare, and non-flat pages is untested.
- Low-quality scan robustness: Stress-test robustness to skew, blur, noise, bleed-through, compression artifacts, and low DPI; quantify failure modes.
- Complex figure/chart extraction: Unit tests do not assess figures, plots, or diagrams (e.g., axis labels, legends, data traces, OCR of embedded raster text).
- Cross-page coherence: No unit tests for footnote continuation, references across pages, multi-page tables/figures, or headings that carry structure across pages.
- Advanced table structure: Tests sample relative positions of cells with certain values but do not evaluate merged cells, header/body detection, multi-header hierarchies, column typing, or table-to-markdown fidelity.
- Math semantics beyond rendering: KaTeX render-based equality may miss semantic differences; evaluate semantic equivalence, numbering, alignment, macros, and inline vs display consistency.
- Floating element association: System correctness for linking captions to the correct figure/table and disambiguating multiple nearby floats is not directly tested.
- Document semantics and structure: Limited assessment of higher-level structure (TOC, section hierarchy, citations, references, hyperlinks, footnotes/endnotes mapping).
- Forms and interactive elements: No evaluation on forms (checkboxes, radio buttons, text fields), form field extraction, or layout-to-schema mapping.
- Reading order edge cases: RTL, bidirectional text, sidebars, footnotes within columns, and complex magazine-style layouts are not separately stress-tested.
- Text normalization: Treatment of hyphenation across line/column breaks, ligatures, small caps, and font-based semantics (bold/italics as meaning) is not systematically evaluated.
- Color and visual semantics: Color-coded meaning (e.g., redline edits), highlights, and annotations are outside the current unit tests.
- PDF internals and vector graphics: No evaluation of extracting text embedded in vector graphics, shapes, or layered content (e.g., hidden text, overlays, watermarks).
- Unit test coverage quantification: No measurement of coverage/recall of unit tests per page; what proportion of critical content is actually verified?
- Unit test quality auditing: Absent estimates of false positives/negatives in synthetic unit tests; no reported manual audit rates or inter-annotator reliability for a sampled subset.
- Reward weighting and balance: All tests appear equally weighted; investigate category-weighted rewards, coverage-aware weighting, or curricula to avoid over-optimizing easy tests.
- Reward sparsity and credit assignment: Binary page-level pass-rate reward may be sparse; explore hierarchical/section-level rewards and shaping signals to improve learning stability.
- Reward hacking risk: Validate that improvements do not arise from exploiting test artifacts (e.g., minimal outputs that pass presence/absence checks); add adversarial tests to detect gaming.
- Binary vs continuous rewards: No controlled comparison between binary unit-test rewards and continuous signals (edit distance variants, structural similarity metrics) for RL effectiveness.
- GRPO design choices: Lack of ablations on GRPO hyperparameters (beyond β), number of completions (28), group size, and sampling strategies; quantify stability/sensitivity.
- Importance sampling variants: No reported ablation isolating benefits of token-level vs sequence-level importance sampling in RL training.
- Contribution disentanglement: “Synth data, RLVR, souping” are introduced together; missing ablations to quantify each component’s standalone and combined effect.
- Souping methodology: No details on averaging scheme (uniform vs weighted), variance across seeds, or whether souping introduces overfitting to the benchmark.
- Compute and cost scaling: Training cost/time, inference latency/throughput, and energy use are not reported; explore cost-performance trade-offs and smaller/larger model variants.
- Decoding strategy rigor: Dynamic temperature scaling is introduced without a systematic comparison to nucleus/beam decoding, constrained decoding, or restart policies across domains.
- Image resolution selection: Claimed sweep but no quantitative results; investigate tiling/high-resolution encoders and adaptive resolution per page complexity.
- Output format implications: YAML chosen for reliability, but downstream schema stability, compatibility with consumers, and lossiness vs structured JSON/HTML are not evaluated.
- Benchmark external validity: Results are centered on olmOCR-Bench; evaluate on external, diverse benchmarks (e.g., OmniDocBench v1.5, DocLayNet, PubTables-1M, DocVQA) to test generalization.
- Train–test contamination checks: No explicit analysis of overlap between training sets (SFT/synthetic) and evaluation documents; perform de-duplication and leakage audits.
- Synthetic pipeline fidelity: Quantify similarity of VLM-generated HTML to original PDFs (layout/element metrics) and correlate fidelity with RL gains.
- General VLM dependence: Synthetic generation relies on closed-source models (Claude, GPT-4.1); test replacing with open VLMs and measure impact on data quality and final performance.
- Scale and diversity of synthetic data: Only 2,186 pages (~30k tests); study scaling laws for number/diversity of synthetic pages and test types vs performance saturation.
- Category-wise robustness: Provide deeper per-domain analyses (legal, financial, scientific, government forms, patents, newspapers) to identify domain-specific failure modes.
- Human-centered evaluation: Correlate unit-test scores with human judgments of OCR usefulness and editability; verify that unit-test gains translate to practical utility.
- Safety and adversarial robustness: Assess resilience to adversarial content (invisible text, overlapping layers), prompt-injection-like embedded text, and watermark/annotation interference.
- Lifecycle and maintenance: How stable are unit tests across renderer/toolchain changes (KaTeX, HTML/CSS engines)? Evaluate brittleness to environment drift.
Glossary
- Alt text: Textual descriptions attached to images for accessibility and machine understanding. "includes basic alt text for images."
- Binary unit tests: Pass/fail tests used to verify specific properties of OCR outputs. "where our rewards are a diverse set of binary unit tests."
- Bounding box: A rectangular region specifying the position and size of a visual element. "relative bounding box positions of rendered equation DOM elements"
- Chain of thought: Step-by-step reasoning traces used by models to solve complex tasks. "by using chain of thought to dedicate more inference compute to difficult document sections."
- Checkpoint averaging: Combining multiple model checkpoints by averaging weights to improve robustness. "model checkpoint averaging or ``souping''"
- DOM: The Document Object Model representing the structure of HTML/XML documents as a tree of elements. "rendered equation DOM elements"
- Dynamic temperature scaling: Adjusting the sampling temperature during inference to mitigate repetition or non-termination. "we use dynamic temperature scaling starting at 0.1 and continually increasing it to 0.2, 0.3 and so on up to a max of 0.8."
- Edit distance: A string similarity metric measuring the minimum number of edits needed to transform one string into another. "While popular OCR benchmarks often use a form of edit distance"
- EOS token: A special end-of-sequence marker indicating the completion of a generated output. "whether the model completion ends with the EOS token"
- FP8: An 8-bit floating point format used to accelerate and reduce memory for model inference/training. "olmOCR-2-7B-1025-FP8"
- GRPO: Group Relative Policy Optimization, an RL algorithm variant for training generative models. "We apply Group Relative Policy Optimization (GRPO) to olmOCR using our synthetic verifiable unit tests as binary-valued reward signals."
- H100 GPU: NVIDIA’s Hopper-generation accelerator used for high-performance training/inference. "using an 8xH100 GPU node."
- Importance sampling: A technique that biases sampling toward more informative instances to improve learning or estimation efficiency. "We used importance sampling at both the token level (3 runs) and the sequence level (3 runs)"
- KaTeX: A fast math typesetting library for rendering LaTeX equations in the browser. "visually renders the same way with KaTeX"
- KL divergence: Kullback–Leibler divergence, a measure of how one probability distribution differs from another. "We use the Hugging Face TRL library, with KL divergence ."
- LaTeX: A document preparation system widely used for typesetting mathematical formulas. "post-rendered correctness of a LaTeX formula"
- Layout analysis: Detecting and characterizing structural components (columns, tables, headers) of a document page. "Layout analysis. We first use the VLM with a picture of a randomly sampled page from PDF documents and ask it to analyze the document."
- Linearizing content: Converting spatially laid-out content into a coherent, sequential reading order. "extracting and linearizing content from digitized print documents like PDFs."
- Model souping: Averaging weights from multiple trained models/checkpoints to achieve better generalization. "model checkpoint averaging or ``souping''"
- N-gram: A contiguous sequence of n tokens used in text modeling and evaluation. "Baseline Robustness: Checks that long repeated -grams or non-target language characters do not appear."
- Natural reading order: The human-expected sequence in which text should be read across a complex layout. "Natural Reading Order: Checks sentences for reading order correctness"
- Prompt caching: Reusing fixed parts of prompts to reduce latency and compute during repeated inference. "placing any fixed text first allows for prompt caching by the inference engine."
- Rasterized image: A pixel-based representation produced by rendering vector or document content. "best represents the rasterized image of a page."
- Reinforcement learning with verifiable rewards (RLVR): RL training where reward signals are derived from externally checkable criteria. "trained using reinforcement learning with verifiable rewards (RLVR)"
- Semantic HTML: HTML that uses meaningful tags (e.g., header, footer, table) to express structure and content. "render this document as clean, semantic HTML"
- Supervised fine-tuning (SFT): Additional training on labeled data to adapt a pretrained model to a specific task. "Alongside olmOCR2-synthmix-1025, we use a refreshed mix for supervised fine-tuning, olmOCR-mix-1025."
- TRL library: Hugging Face’s reinforcement learning toolkit for training LLMs. "We use the Hugging Face TRL library"
- Unit test rewards: RL reward signals computed from the pass/fail results of unit tests. "Unit test rewards for olmOCR 2's RLVR training."
- Vision LLM (VLM): A multimodal model that understands images and generates or interprets text. "a specialized, 7B vision LLM (VLM) trained using reinforcement learning with verifiable rewards (RLVR)"
- YAML: A human-readable data serialization format often used for configurations and structured outputs. "We switched to YAML, which reduced the retry rate dramatically."
Practical Applications
Immediate Applications
The following applications can be deployed today, using the released open-source model (olmOCR-2-7B-1025), data, and code, or by directly integrating the provided workflows.
- High-fidelity enterprise PDF ingestion for RAG and search (Sector: software, enterprise IT) — Tools/Workflows: Use olmOCR 2 to convert PDFs into clean, naturally ordered Markdown/HTML with accurate tables and equations; chunk outputs for vector indexes; preserve structure with YAML metadata. — Assumptions/Dependencies: 7B VLM inference (GPU recommended; FP8 model variant available), images resized to ~1288px longest edge, documents predominantly printed (not handwriting), English-first performance.
- Accurate table extraction for analytics pipelines (Sector: finance, insurance, pharma, manufacturing) — Tools/Workflows: Convert tables to HTML from PDFs (reports, statements, lab reports) and load into BI tools or data warehouses; integrate header/footer suppression to reduce noise and duplicates. — Assumptions/Dependencies: Table-heavy PDFs; robust post-processing to map HTML tables into columnar formats; quality scans.
- STEM publishing and education content conversion (Sector: publishing, education) — Tools/Workflows: Convert equations to LaTeX with visually validated equivalence (via KaTeX rendering); produce web-ready HTML/Markdown for textbooks, lecture notes, and arXiv-like PDFs. — Assumptions/Dependencies: KaTeX-based visual equivalence checks; complex inline vs display math conventions respected in output; primarily English-language material.
- Accessibility remediation and EPUB production (Sector: government, higher-ed, accessibility services) — Tools/Workflows: Ensure natural reading order for multi-column pages; strip headers/footers/page numbers; produce screen-reader-friendly text and structured HTML; integrate into Section 508/WCAG remediation workflows. — Assumptions/Dependencies: Reading-order-sensitive content; downstream EPUB/HTML pipelines; image alt text may need augmentation beyond the basic metadata emitted.
- Digitization of public archives and records (Sector: cultural heritage, government archives) — Tools/Workflows: Apply to legacy scans from archives; output normalized, deduplicated text with robust layout handling; create searchable, accessible repositories. — Assumptions/Dependencies: Image quality of scans; non-handwritten text; domain mismatch may require custom unit tests or SFT for specialized documents.
- E-discovery, compliance, and audit-ready text extraction (Sector: legal, regulated industries) — Tools/Workflows: Use header/footer filtering and natural reading order to produce deposition-ready text; log OCR provenance and model/version metadata; apply post-OCR PII checks. — Assumptions/Dependencies: On-prem deployment for confidentiality; chain-of-custody tracking; acceptance criteria may adopt unit-test gates.
- Unit-test-based OCR acceptance and QA (Sector: software/ML engineering across industries) — Tools/Workflows: Adopt the paper’s binary unit-test approach to define acceptance tests (text presence/absence, layout order, math rendering, table cell positions); integrate into CI/CD to block regressions. — Assumptions/Dependencies: Synthetic or curated pages to derive ground-truth tests; KaTeX environment for math checks; deterministic renderers.
- Open, cost-effective OCR API or on-prem service (Sector: SaaS, internal platforms) — Tools/Workflows: Serve the Apache-licensed model behind a REST API (or use the demo/API partners mentioned); leverage dynamic temperature scaling and EOS checks for stable inference; output YAML to reduce retries. — Assumptions/Dependencies: GPU inference budget; throughput targets vs image resolution; service hardening (timeouts, retry logic, prompt caching).
- Improved LLM data pipelines and deduplication (Sector: LLMOps, data engineering) — Tools/Workflows: Use header/footer/page-number absence tests to reduce repeated n-grams; produce higher-quality corpora for pretraining/RAG; chunk by sections based on YAML/HTML cues. — Assumptions/Dependencies: Proper segmentation and chunking policy; dedup and long n-gram checks aligned with downstream models’ tokenization.
- RL with verifiable rewards as a training recipe (Sector: ML research/engineering) — Tools/Workflows: Port the paper’s RLVR+GRPO recipe to other domain-specific parsers; generate synthetic HTML and derive unit tests to create binary rewards; “soup” multiple seeds for robustness. — Assumptions/Dependencies: Access to a general VLM (authors used Claude) to bootstrap synthetic HTML and tests (~$0.12/page cited); TRL library; careful reward design to avoid reward hacking.
- Vendor benchmarking and procurement (Sector: enterprise IT, public sector) — Tools/Workflows: Replace/edit-distance scoring with binary unit tests to compare OCR systems fairly on practical correctness (reading order, math visual equivalence, table cell placement). — Assumptions/Dependencies: Test-set coverage matches internal document types; reproducible renderers and deterministic environments.
- Developer productivity for OCR pipelines (Sector: software tooling) — Tools/Workflows: Adopt YAML outputs to reduce parsing errors and repetition loops; integrate dynamic temperature scaling and EOS-based failure recovery; maintain model+inference settings under version control. — Assumptions/Dependencies: Inference stack supports prompt caching and temperature schedules; monitoring for repetition loops and retries.
Long-Term Applications
These uses require further research, domain adaptation, scaling, or engineering beyond what the paper immediately provides.
- Multilingual and script expansion (Sector: global content platforms, public sector) — Tools/Products: Extend synthetic HTML and unit-test generation to multiple languages/scripts; train RLVR with language-specific tests (reading order, numerals, punctuation). — Assumptions/Dependencies: Multilingual datasets; font/script coverage; renderers for math and text across scripts.
- Handwriting, forms, and structured field extraction (Sector: healthcare, logistics, finance) — Tools/Products: Add form-field unit tests (key-value presence, logical constraints); RLVR with schema-validation rewards; handwriting-specific SFT and synthetic generation. — Assumptions/Dependencies: Handwriting datasets and augmentations; robust field-level constraints; privacy-preserving training data.
- Schema-aligned, verifiably correct JSON outputs (Sector: finance/XBRL, procurement, regulatory reporting) — Tools/Products: Replace generic Markdown with strict schemas (e.g., XBRL/HL7/FHIR); use binary rewards for schema validity and field-level invariants. — Assumptions/Dependencies: High-quality schema maps; ground-truth for unit tests; validators integrated in training loop.
- On-device and real-time OCR (Sector: mobile scanning, field operations) — Tools/Products: Distill/quantize the 7B VLM to edge-friendly sizes; streaming inference; battery-optimized pipelines. — Assumptions/Dependencies: Model compression without eroding layout/math/table fidelity; hardware acceleration; privacy constraints.
- Audited and legally defensible OCR (Sector: legal, finance, government) — Tools/Products: “Verifiable OCR” pipelines that log unit-test pass-rates per page, model hashes, and deterministic renders as evidence; certification frameworks. — Assumptions/Dependencies: Standards for OCR evidence; third-party certification; reproducibility of render environments.
- Large-scale scientific corpus conversion and knowledge graphs (Sector: academia, biotech, energy) — Tools/Products: Equation-level extraction with symbol grounding; table-to-graph conversion; automated linking of entities across millions of PDFs. — Assumptions/Dependencies: Entity/linking infrastructure; sustained compute for bulk conversion; license clearance for corpora.
- Procurement and policy standards for OCR evaluation (Sector: public procurement, compliance) — Tools/Products: Define unit-test-based acceptance criteria (reading order, accessibility, math/table correctness) in RFPs; require transparent, reproducible scoring. — Assumptions/Dependencies: Consensus on test design; open benchmarks and fixtures; governance for updates.
- Generalizing RLVR + synthetic unit tests to related domains (Sector: software, UI automation, data extraction) — Tools/Products: Apply the method to UI parsing, chart/figure extraction, receipts, and invoices, where pixel-to-HTML unit tests can be defined. — Assumptions/Dependencies: Reliable HTML/SVG render pipelines; domain-specific verifiable checks (e.g., axis consistency for charts).
- Ultra-high-resolution and specialty documents (Sector: engineering, construction, geospatial) — Tools/Products: Blueprints, maps, and CAD-like PDFs with tiling/patch hierarchies and cross-page references; unit tests for scale bars, legends, and callouts. — Assumptions/Dependencies: Memory-efficient high-res processing; domain ontologies; multi-page consistency checks.
- Accessibility at scale with richer semantics (Sector: accessibility tech, education) — Tools/Products: Auto-generate or validate alt text, ARIA roles, heading structures; unit tests rewarding screen-reader semantics beyond text order. — Assumptions/Dependencies: Datasets with high-quality accessibility annotations; standardized audits (WCAG) embedded in reward functions.
- Fully open, self-hosted synthetic-data generation (Sector: ML platforms) — Tools/Products: Replace proprietary VLMs in the HTML synthesis pipeline with open models; reduce per-page cost; expand to domain-specific templates safely. — Assumptions/Dependencies: Open VLMs that can reliably render and refine HTML; tooling to detect and mitigate hallucinations.
- Document agents with evidence-grounded reasoning (Sector: enterprise productivity) — Tools/Products: Chain-of-thought and tool-use augmented OCR agents that answer questions over converted corpora, with evidence spans tied to unit-test-validated text blocks. — Assumptions/Dependencies: Multi-step RL with verifiable rewards; integration with retrievers; UX for evidence inspection.
Collections
Sign up for free to add this paper to one or more collections.