- The paper presents a novel diversity-steered sampling method that improves semantic uncertainty quantification by discouraging redundant outputs.
- It utilizes NLI models and semantic clustering to accurately estimate aleatoric and epistemic uncertainties with enhanced sample efficiency.
- The approach is broadly applicable across autoregressive and masked diffusion models, reducing computational overhead in low-resource settings.
Efficient Semantic Uncertainty Quantification in LLMs
Introduction
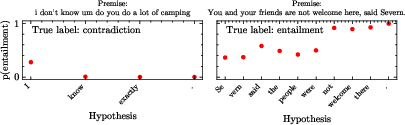
The paper "Efficient semantic uncertainty quantification in LLMs via diversity-steered sampling" (2510.21310) addresses a significant challenge in natural language processing: accurately estimating semantic aleatoric and epistemic uncertainties in LLMs, particularly in free-form question-answering tasks. The authors propose a novel diversity-steered sampling method that enhances sample efficiency by discouraging semantically redundant outputs during decoding. This approach leverages natural language inference (NLI) models fine-tuned on partial prefixes or intermediate diffusion states to inject a semantic-similarity penalty into the proposal distribution of the model.
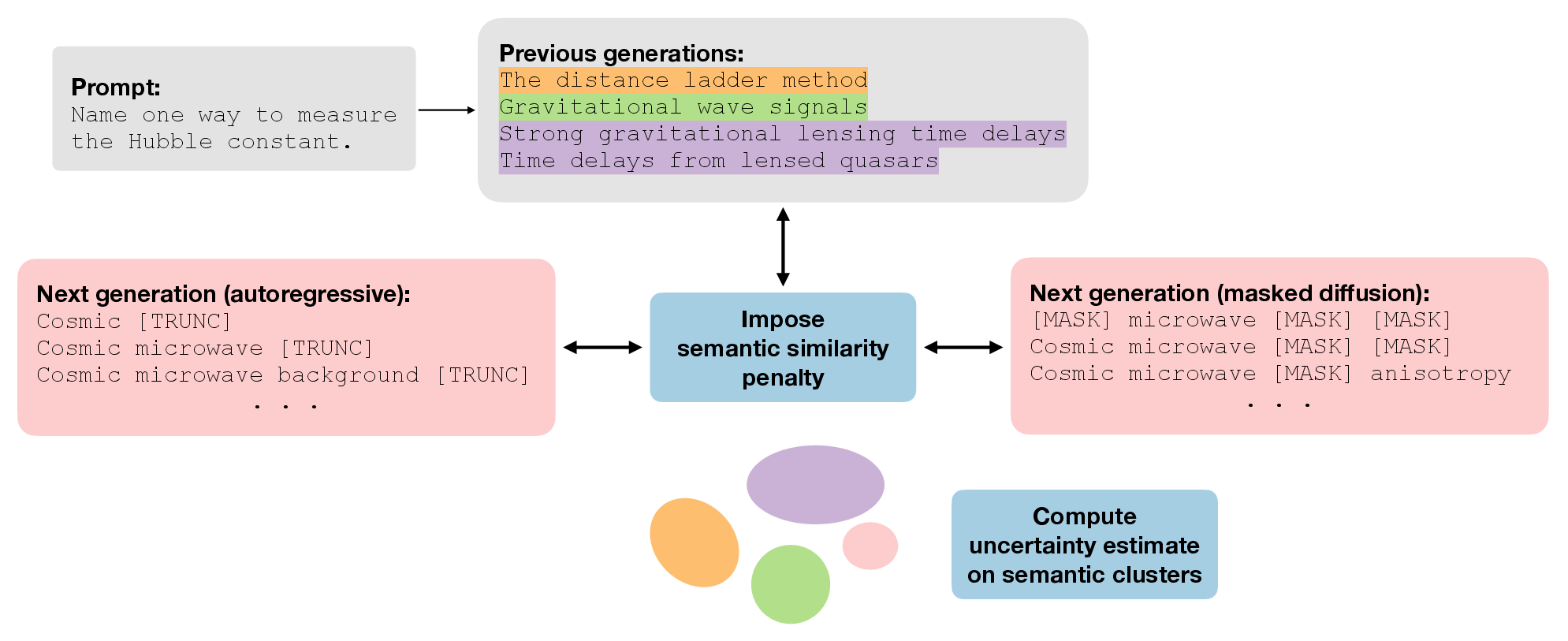
Figure 1: Our sampling workflow illustrated with a prompt that induces high aleatoric uncertainty. Given previous generations, we guide the LLM's next token away from semantically redundant outputs. The semantic clusters of resulting generations are used to estimate downstream uncertainty.
Methodology
The proposed framework is modular and adaptable, requiring no gradient access to the base LLM. It operates by integrating a continuous semantic similarity penalty calculated through NLI models during decoding. This penalty discourages semantically redundant samples, allowing the method to cover both autoregressive models (ARMs) and masked diffusion models (MDMs).
Diversity-Steered Sampling: By modifying the token-level conditional distributions, the diversity-steered sampler promotes semantic novelty. The process involves several steps:
- Semantic Clustering: Utilizes semantic clusters to evaluate downstream uncertainty, distinguishing aleatoric uncertainty (semantic entropy) and epistemic uncertainty.
- Importance Reweighting: Corrects any sampling bias introduced by the diversity penalty through importance weighting.
- Variance Reduction: Employs control variates to shrink estimation variance, enhancing the stability of the uncertainty estimates.
This approach is particularly beneficial for low-resource settings due to its sample efficiency and reduced computational overhead compared to traditional Monte Carlo sampling methods.
Results and Discussion
The framework was applied across four QA benchmarks, demonstrating it could match or surpass baseline performances while using fewer samples to cover more semantic clusters. Notable findings include:
The implications of this work extend to various domains where LLMs operate under uncertainty, such as medical diagnosis, legal document analysis, and automated customer support systems. By providing reliable uncertainty estimates, this method enhances trust and safety in AI deployments.
Conclusion
This paper presents a robust framework for semantic uncertainty quantification that improves over existing methods by reducing the semantic redundancy in sampled outputs. Its general applicability to different LLM types and its efficiency in resource-constrained environments make it a valuable addition to the field of AI uncertainty quantification.
The diversity-steered sampling method sets the stage for future research in optimizing uncertainty estimates and exploring its integration with reinforcement learning models for adaptive LLM training. Further exploration could focus on enhancing robustness by adapting semantic clustering to better handle the nuances of natural language generation, including marginalizing over possible semantic clusters or prompt templates for improved generalization.