On the Faithfulness of Visual Thinking: Measurement and Enhancement
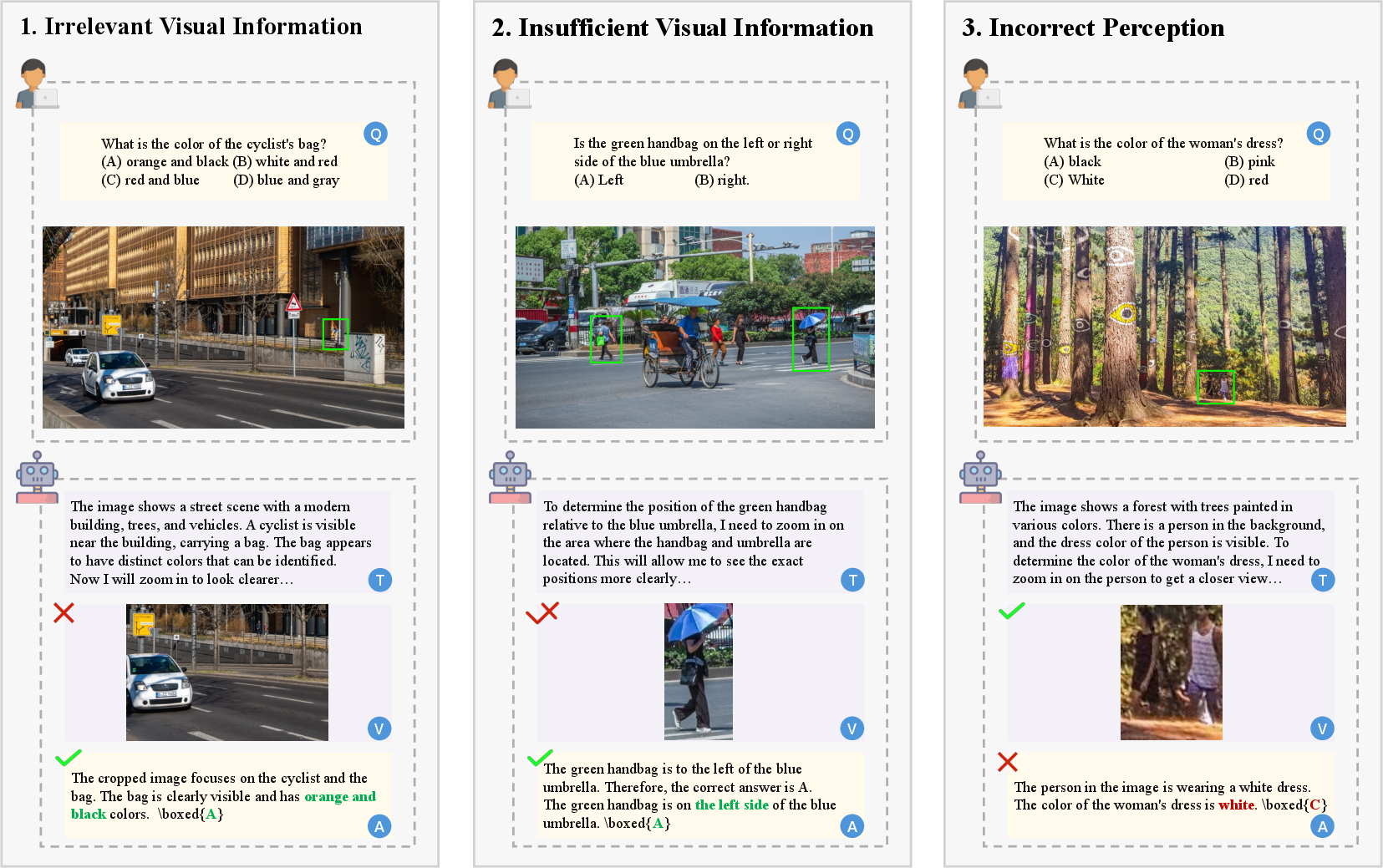
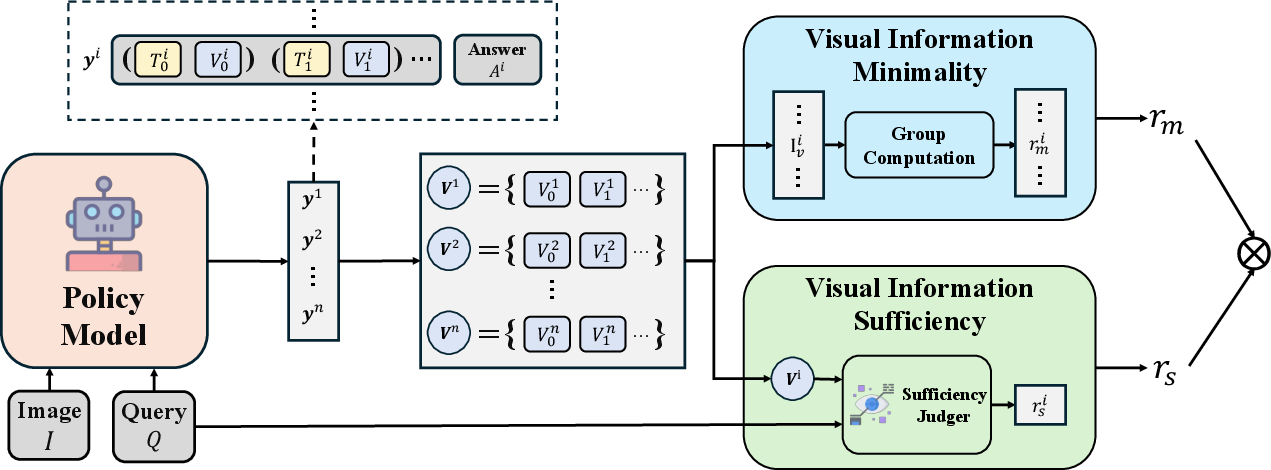
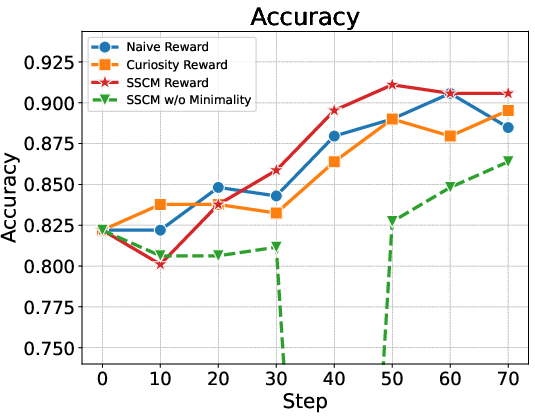
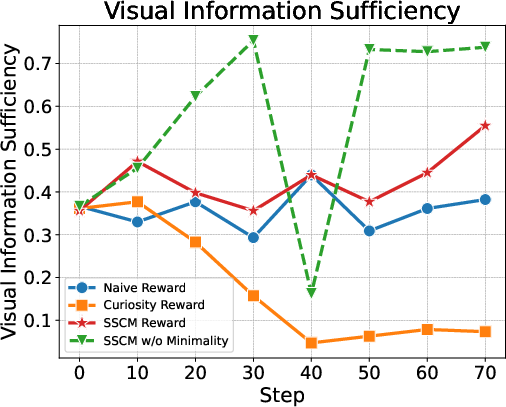
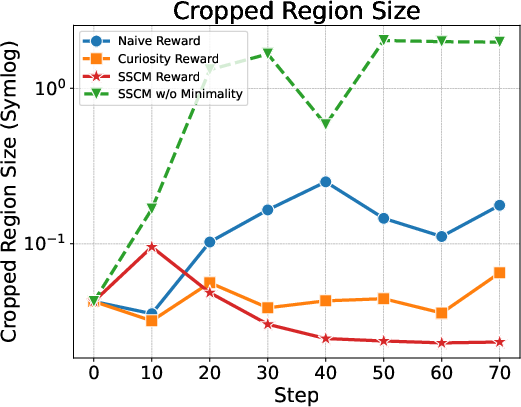
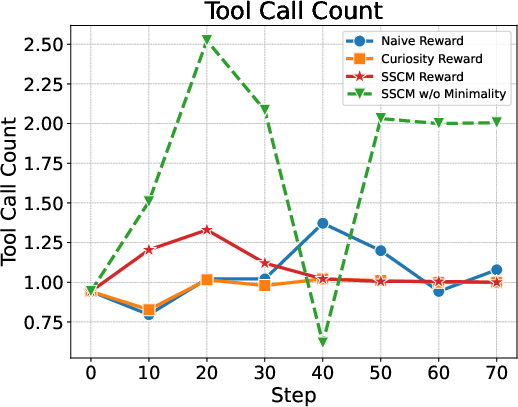
Abstract: Recent large vision-LLMs (LVLMs) can generate vision-text multimodal chain-of-thought (MCoT) traces after reinforcement fine-tuning (RFT). However, we observe that the visual information incorporated in MCoT is often inaccurate, though still yield correct answers, indicating a lack of faithfulness in the MCoT reasoning process. We attribute this unfaithfulness to the RL reward in RFT, which solely incentivizes the format of interleaved vision-text cues, ie, it encourages the model to incorporate visual information into its text reasoning steps without considering the correctness of the visual information. In this paper, we first probe the faithfulness of MCoT by measuring how much the prediction changes when its visual and textual thoughts are intervened. Surprisingly, the model's predictions remain nearly unchanged under visual intervention but change significantly under textual intervention, indicating that the visual evidence is largely ignored. To further analyze visual information, we introduce an automated LVLM-based evaluation metric that quantifies the faithfulness of visual cues from two perspectives: reliability and sufficiency. Our evaluation reveals that the visual information in current MCoT traces is simultaneously unreliable and insufficient. To address this issue, we propose a novel MCoT learning strategy termed Sufficient-Component Cause Model (SCCM) learning. This approach encourages the MCoT to generate sufficient yet minimal visual components that are independently capable of leading to correct answers. We note that the proposed SCCM is annotation-free and compatible with various RFT for MCoT in a plug-and-play manner. Empirical results demonstrate that SCCM consistently improves the visual faithfulness across a suite of fine-grained perception and reasoning benchmarks. Code is available at https://github.com/EugeneLiu01/Faithful_Thinking_with_Image.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.