- The paper demonstrates that small orthogonal rotations can shift Adam’s bias from complex nonlinear to inferior linear decision boundaries.
- The study employs both theoretical analysis and empirical experiments to reveal Adam’s vulnerability to data orientations compared to gradient descent.
- The paper introduces an EGOP-based reparameterization that restores rotational invariance, thereby improving Adam’s generalization performance.
The Effect of Simple Data Rotations on the Implicit Bias of Adam
Introduction
The paper "How do simple rotations affect the implicit bias of Adam?" (2510.23804) presents a detailed theoretical and empirical study on how orthogonal (rotation) transformations of the feature space impact the implicit bias of coordinate-wise adaptive gradient methods, particularly Adam, in the context of binary classification with two-layer ReLU neural networks. It extends prior analysis of optimizer-induced bias and reveals that Adam's well-documented bias towards nonlinear (richer) decision boundaries, claimed to often approach Bayes-optimality more closely than gradient descent (GD), is not invariant to seemingly innocuous data rotations. In fact, small rotations of the input can substantially degrade the generalization performance of Adam—often producing linear predictors with inferior risk relative to those found by GD, whose bias is orthogonally invariant. The paper further demonstrates that this fragility can be remedied by a data-driven reparameterization derived from the expected gradient outer product (EGOP) matrix, thereby restoring rotation equivariance to adaptive methods.
Implicit Bias of Adam and Sensitivity to Rotations
The "richness bias" of Adam and related adaptive methods has been characterized in recent theoretical work, showing that for binary classification tasks where the Bayes-optimal decision boundary is nonlinear, Adam optimizers converge to nonlinear predictors closer to the Bayes-optimal solution than those produced by standard (stochastic) gradient descent [vasudeva2025rich]. This effect is most pronounced in synthetic settings with carefully controlled data distributions, such as mixtures of labeled Gaussians, and network architectures with fixed second-layer weights.
However, Adam's coordinate-wise adaptation is fundamentally non-equivariant to rotations in parameter or data space, due to its reliance on diagonal preconditioning. This lack of rotational invariance means that the implicit solution found by Adam can change dramatically if the input is rotated, even by a small amount. The authors first replicate the canonical setup of [vasudeva2025rich], demonstrating that when γ=0 (no rotation), Adam and SignGD (an Adam variant with β1=β2=0) produce nonlinear boundaries approximating the Bayes predictor (Figure 1).
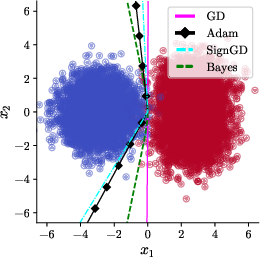
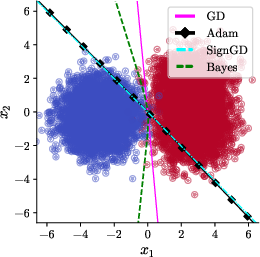
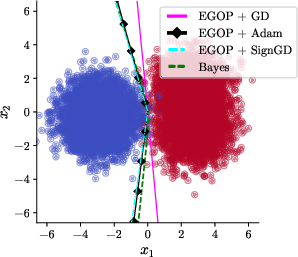
Figure 1: Data rotation γ=0, learning with base algorithms. Adam and SignGD yield nonlinear, rich predictors compared to GD.
Upon the introduction of a small rotation (γ=32π), Adam and SignGD's bias abruptly shifts: both yield linear decision boundaries (specifically, x1=−x2), and the learned classifier generalizes worse than the boundary found by gradient descent—which remains optimal among linear predictors and rotates together with the data distribution (Figure 2).
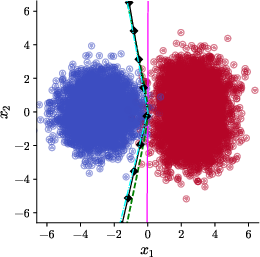
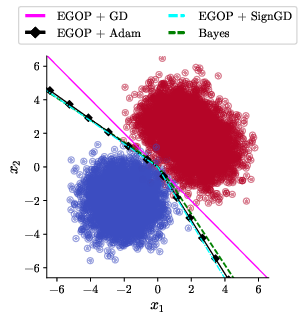
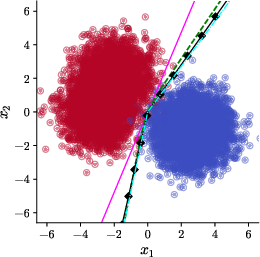
Figure 2: γ=0, Adam/SignGD, base algorithms. Rotations of the dataset result in a failure of Adam’s richness bias and the emergence of a linear, sub-optimal decision boundary.
These results are formalized via an explicit construction of a class of data distributions and a detailed analysis of the SignGD update rule. The paper shows analytically that the gradient's sign structure, under mild assumptions on the rotation and data parameters, forces convergence to an axis-aligned linear solution (see Theorem~1 and its supporting Lemmas).
Theoretical Results: Invariance and Sensitivity
The crucial theoretical contribution is twofold. First, it demonstrates that Adam's nonlinear decision bias is not invariant under orthogonal rotations: for any nontrivial rotation, there exists a data distribution for which Adam returns a linear classifier whose generalization metric is strictly inferior to that of the Bayes classifier and also, in many instances, to that of GD. Second, the authors show that this vulnerability is not a mere artifact of the idealized setting but persists in practical neural architectures including networks with bias parameters and trainable outer layers (see empirical figures and supplementary analysis). Adam and coordinate-wise methods' lack of rotational equivariance thus represents a substantial fragility in geometric robustness and implicit regularization.
EGOP-Reparameterization: Rotation-Equivariant Adaptive Optimization
To address this issue, the authors propose leveraging a linear reparameterization of the model parameters informed by the EGOP matrix—a covariance-type object capturing average gradient outer products under the training data distribution. This EGOP-based transformation orthogonalizes the optimization landscape, enabling adaptive methods to operate in a parameter basis where rotations in data space do not affect the trajectory or implicit bias of the optimizer. The reparameterization framework is also theoretically justified: any deterministic first-order method, when applied to the EGOP-reparameterized problem, becomes equivariant to rotations. This restoration of rotational invariance translates, empirically, to Adam recovering its richness bias for all rotation angles γ (Figure 3 and corresponding generalization bounds).
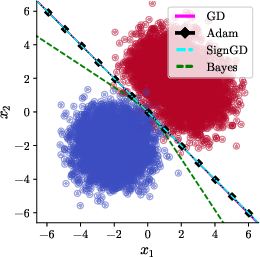
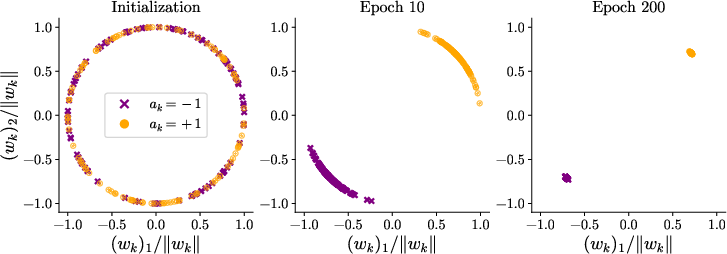
Figure 3: Nonlinear boundaries returned by EGOP-reparameterized Adam are equivariant under rotation and robustly approximate the Bayes-optimal solution across rotation angles.
Related algorithms including Shampoo and SOAP, which employ richer preconditioners, also fall within this invariance framework, as evidenced in the extended discussion and appendices.
Empirical Validation and Practical Observations
Numerical experiments corroborate the theoretical analysis. The robustness of the failure modes and the corrective power of EGOP-reparameterization is confirmed across a range of architectural and data-modeling details, including networks with bias, different hidden dimensions, and estimates of the EGOP matrix from finite samples. Notably, increasing Adam's ϵ parameter (intended to improve numerical stability) does not, by itself, restore the richness bias in the absence of reparameterization, as shown in further figures and ablation studies.
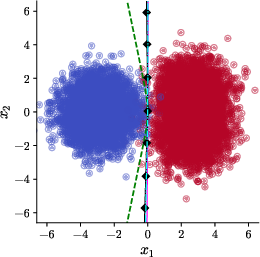
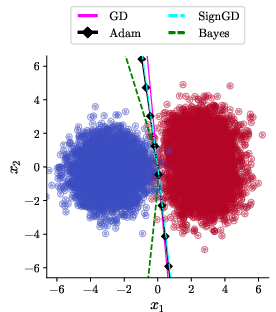
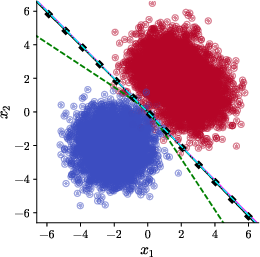
Figure 4: Empirical demonstration that varying ϵ in Adam/SignGD without reparameterization fails to restore rotation invariance or nonlinearity in learned decision boundaries.
Broader Implications and Future Directions
This paper highlights that Adam's celebrated ability to find complex, highly expressive predictors is highly contingent on the coordinate system in which data is presented. In practical learning scenarios where real-world data is rarely axis-aligned, this sensitivity represents a theoretical and applied limitation for coordinate-wise adaptive optimization. The results motivate further scrutiny of optimizer–data interaction beyond the narrow context of SGD vs. Adam, pushing toward a richer geometric understanding and the use of structure-aware or data-adaptive preconditioners for robust generalization.
Rotation-equivariant variants such as EGOP-reparameterized Adam (and analogously, Shampoo, SOAP) suggest a general procedure for removing undesirable artifacts induced by coordinate system choices. Future research directions include extending such equivariant frameworks to more general classes of transformations beyond rotations (e.g., adversarially chosen input representations), investigating their effects in overparametrized or highly corrupted regimes, and understanding the trade-offs with optimization efficiency and expressivity in large-scale neural architectures.
Conclusion
The work rigorously demonstrates that Adam's implicit bias towards complex, non-linear decision boundaries is not a generic property; rather, it is a fragile artifact of input axis alignment. Even minor data rotations can provoke substantial failures in generalization, contradicting prior assumptions about the optimizer's suitability for general machine learning scenarios. EGOP-based reparameterization and similar structure-aware approaches provide a principled and practical route to curing this sensitivity, equipping adaptive gradient methods with geometric invariance and preserving their desirable inductive biases. The results demand careful consideration of both algorithmic design and data representation in modern neural network training.