- The paper demonstrates that logits matrices from diverse language models exhibit a universal low-rank structure that simplifies sequence prediction.
- It employs singular value analysis to reveal power law decay, quantifying the low-dimensional properties inherent in these models.
- The study introduces the Lingen method, which leverages low-rank approximations to generate coherent text from even non-salient prompts.
Sequences of Logits and Low Rank Structures in LLMs
Introduction
The paper "Sequences of Logits Reveal the Low Rank Structure of LLMs" (2510.24966) presents a compelling study into the inherent low-dimensional structure of LLMs. It addresses the importance of understanding this structure from a model-agnostic perspective by focusing on sequential probabilistic models. The research investigates the manifestation of low-rank structures in matrices formed from model logits across various modern LLMs, prompting insights into generative capabilities derived from these structures. Additionally, the paper explores theoretical implications alongside empirical observations, notably positing a universal abstraction that is both empirically testable and mathematically tractable.
Empirical Findings: Low-Rank Structure
The study identifies that matrices composed of logits from LLMs exhibit low approximate rank regardless of the model's architecture. This consistent low-rank property is evident in models spanning various architectures, such as transformers and ISAN networks. The paper details that such low-dimensional representations allow for compressed probabilistic mapping that effectively aids in sequence predictions.
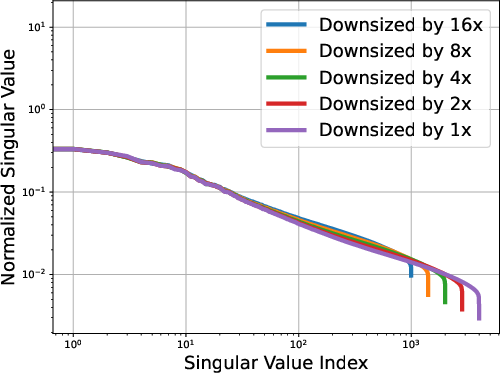
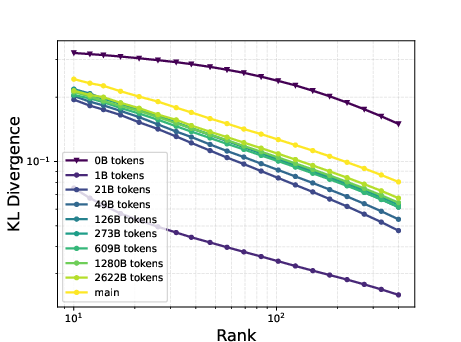
Figure 1: OLMo-7b singular values; Power law exponent α≈0.536
The low-rank trait extends beyond single token prediction matrices, propagating through the entire extended logit matrix that encompasses sequences. For instance, the singular value decay in OLMo models follows a discernible power law, with the exponent hovering around 0.5, signaling a threshold impacting the effectiveness of low-rank approximations. This structural insight is not a legacy of training checkpoints but appears early and evolves throughout the training process.
Exploiting Low-Rank for Generation
Leveraging the low-rank nature described, the paper unveils a fascinating ability to generate textual sequences from given prompts using unrelated or nonsensical prompts, purely via linear combinations of model outputs. This reflects on the generative aspects where low-rank assumptions facilitate coherent continuations akin to original models, hence challenging traditional prompt-response generation strategies.
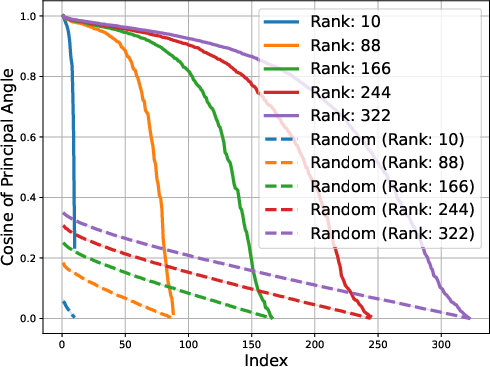
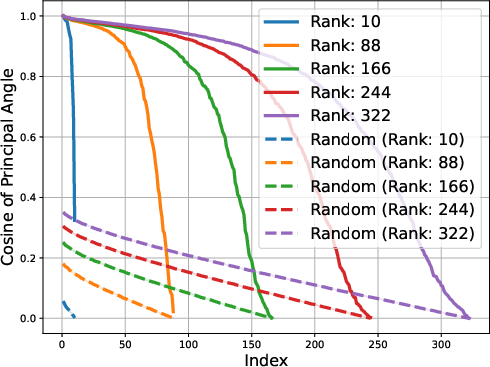
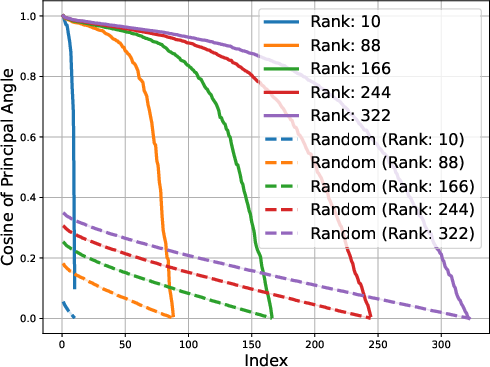
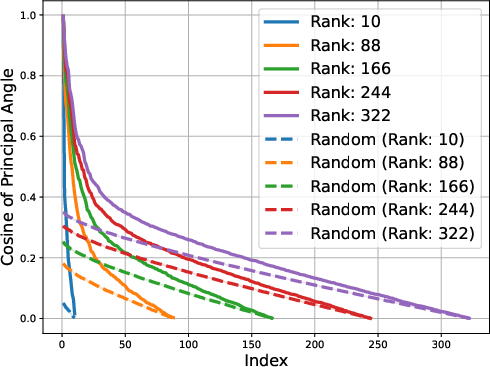
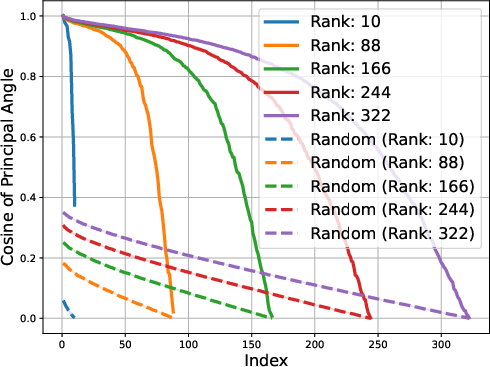
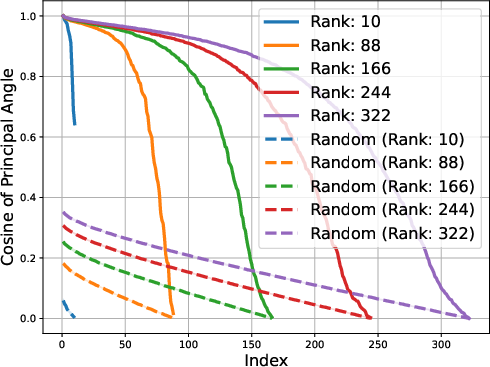
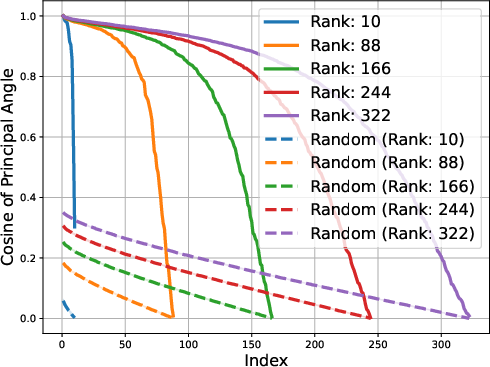
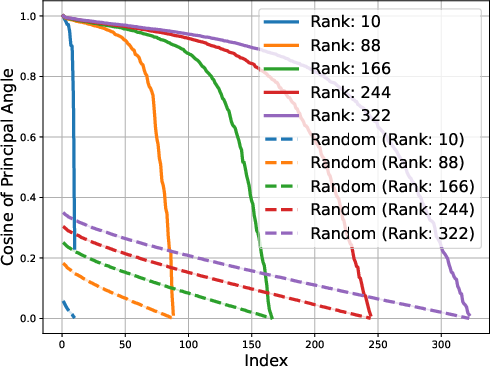
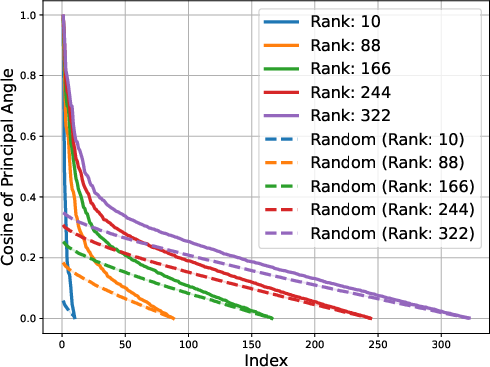
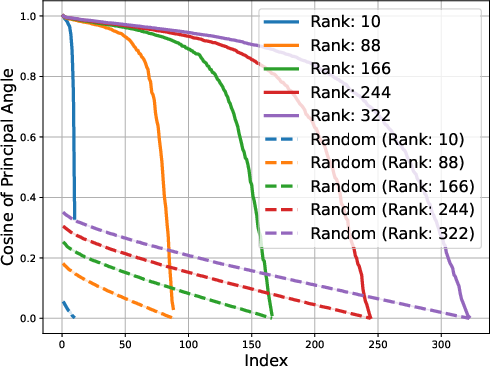
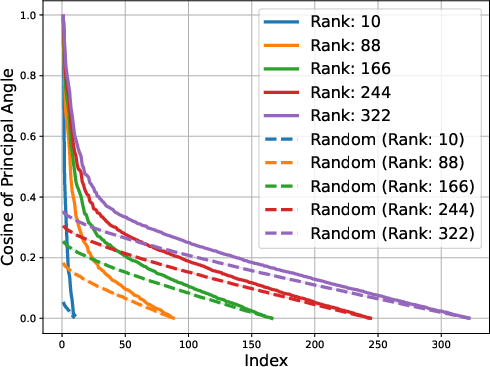
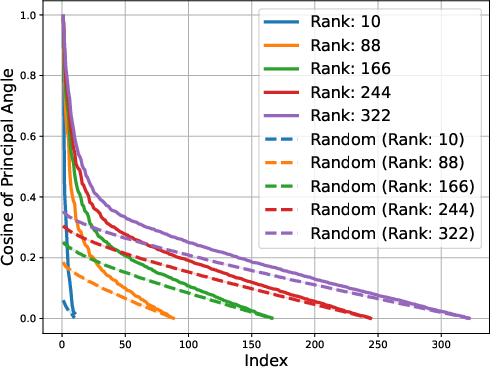
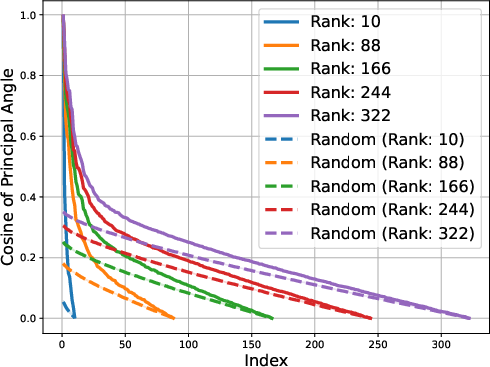
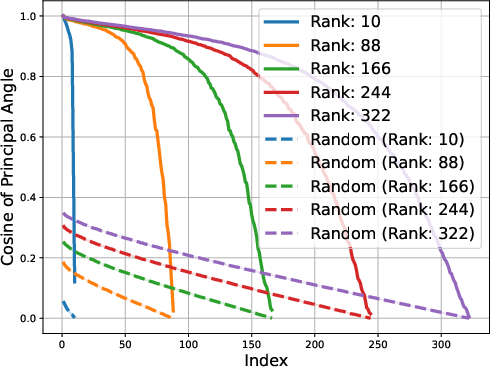
Figure 2: Gemma-1B vs Mamba-1.4B
Furthermore, Lingen, a proposed generation method, evidences superior generative performance against strong baselines even when initialized with non-salient prompts. This method potentially bypasses established filters or defenses, emphasizing implications for AI safety and exploring vulnerabilities in prompt-filtering scenarios.
Theoretical Foundations
The paper propounds substantial theoretical foundations by formulating a generative model within the time-varying ISAN framework. It underscores that low-rank structures correspond to precisely those generative distributions expressible through ISANs. This articulates a formulation where extended logit matrices are affine in nature, suggesting an equivalence between theory and observed generative capabilities.
Implications and Future Directions
The implications of this research span various domains including AI safety, interpretability, and efficient sequence modeling. The authors suggest that continued investigation might lead to refined training diagnostics, enhanced security protocols against unsafe prompt engagements, and robust theoretical models that accommodate approximate low-rank properties.
In future work, researchers may seek to exploit these insights for improved model interpretability, potentially deriving feature space representations that provide deeper insights into language representation and safety.
Conclusion
The paper encapsulates a comprehensive exploration of the low-rank structure prevalent within LLMs and forwards cogent arguments for its application in generative modeling and theoretical representation. These findings offer pathways to not only better understanding the structural intricacies of LLMs but also enhancing their application in tasks requiring robust interpretability and safety.