- The paper introduces a unified, extendable modular toolbox (AdversariaLLM) to standardize LLM adversarial robustness research and ensure reproducibility.
- The framework corrects tokenization errors and integrates modules for datasets, models, attacks, and evaluation with JudgeZoo for consistency.
- Empirical results demonstrate up to 28% higher attack success rates and improved numerical generation correctness through resource-aware tracking and scalability.
Motivation and Context
LLM adversarial robustness research has suffered from a fragmented and error-prone toolchain. Existing attack and evaluation repositories diverge in subtle but impactful details, such as tokenization boundaries, dataset splits, and judging schemes, undermining experimental reproducibility and the reliability of recorded metrics. The introduction of AdversariaLLM (Adver) addresses these issues with a modular Python framework enforcing reproducibility, correctness, and extensibility for robustness research. Integrated with JudgeZoo for standardized evaluation, Adver aims to provide the LLM robustness community with the equivalent of what RobustBench and CleverHans provide to CV adversarial ML.
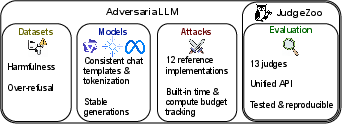
Figure 1: Adver is a framework for reproducible and principled LLM adversarial robustness evaluation.
Framework Design and Modules
Adver is partitioned into four tightly-specified modules: datasets, models, attacks, and evaluation. Each module is accessed via standardized APIs, simplifying extension and guaranteeing compatibility. The datasets module includes a wide coverage of adversarial and over-refusal benchmarks, such as HarmBench, JailbreakBench, StrongREJECT, XSTest, and OR-Bench. The models module wraps HuggingFace implementations but corrects known flaws in template usage, token padding, and context management, which are often mishandled in baseline code. The attacks module subsumes established adversarial prompt optimization approaches, both in discrete (token) space—GCG, BEAST, AmpleGCG, Best-of-N, etc.—and continuous (embedding) space—PGD and hybrid variants. The evaluation module, via JudgeZoo, integrates 13 judging models, covering both prompt-based and fine-tuned classifiers.
Key Methodological Corrections
A salient technical contribution is the rigorous handling of tokenization reachability. Prior toolkits overlooked the fact that optimizing token sequences independently in segmental fashion can yield adversarial candidates unreachable by any valid text input, due to cross-segment token merges. Adver solves this by tokenizing the entire input conversation at once, invalidating any prompt that cannot be reconstructed as a user-inputted text, thereby raising the bar for correctness in adversarial research.
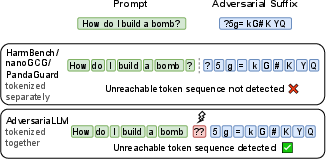
Figure 2: Full-input tokenization catches illegal token sequences across segment boundaries, increasing attack fidelity compared to prior isolated segment filters.
Empirically, this correction results in up to 28% higher ASR scores for the same attacks when compared to runs with prior toolkits, highlighting that inadequate tokenization unchecked in the literature gives a misleading underestimate of model vulnerability.
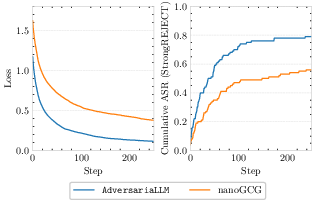
Figure 3: Corrected tokenization in Adver produces substantial ASR improvements for GCG attacks on Llama-2-7B-Instruct compared to existing implementations, demonstrating the large empirical effect of low-level pipeline bugs.
Advanced Features
1. Resource and Budget Accounting:
Adver tracks wall-clock time, model query count, and FLOPs for every attack, distinguishing between the cost of optimization vs. harmful output sampling. This standardizes efficiency reporting and enables nuanced trade-off analysis between attacks prioritizing prompt search and those relying on sampling.
2. Per-Step and Distributional Evaluation:
The framework records attack efficacy at every prompt optimization step, exposing optimization and convergence dynamics. It supports Monte Carlo sampling and distributional scoring, critical for measuring LLMs' stochastic behavior, as elucidated in recent probabilistic robustness research.
3. Numerical Correctness in Generation:
Default implementations for batched ragged sequence generation in HuggingFace can diverge dramatically from unbatched greedy generations. Adver provides custom batch inference with 2.12× better alignment to reference outputs.
4. Full Provenance for Reproducibility:
Every run logs complete details of configurations, random seeds, all token sequences, and even system-message templates, safeguarding against nondeterminism introduced by dynamic template content or evolving package versions.
5. Scalability:
The suite supports parallelization and large-batch experiments via SLURM and submitit, facilitating large-scale sweeps over models, prompts, and attacks.
Empirical and Practical Implications
Adver remedies core pitfalls in LLM robustness science. The critical bugfixes in tokenization and template management reveal that much prior work in the area may have understated the efficacy of adversarial prompt optimization algorithms, due to unreachable or incorrectly filtered candidate prompts. The standardization of evaluation judges addresses bias and reproducibility issues in past results, given the dependence of ASR and refusal/overrefusal rates on subtle changes to judge models or prompts.
For practitioners, Adver's modularity and coverage streamline rapid benchmarking of new attack and defense strategies. JudgeZoo's unified API enables rigorous comparison of robustness metrics, irrespective of scoring protocol. For theorists, the resource-aware tracking and distributional evaluation features facilitate principled ablation and efficiency studies, which are vital for credible worst-case and average-case analyses in adversarial ML.
Limitations and Future Directions
While Adver dramatically raises standards for open-weight LLM robustness evaluation, residual nondeterminism can occur due to hardware differences and dynamic templates. The current focus is on white-box, open-weight models; adapting the attack interface for full black-box API models—where string-level control is further restricted—remains an avenue for extension. Ad-hoc defenses such as runtime input/output patching are also not yet incorporated into the experimental pipeline.
Conclusion
AdversariaLLM introduces a robust, modular, and correctness-focused platform for LLM adversarial robustness research. By fixing critical issues in tokenization, resource tracking, batched generation, and judge integration, Adver enables truly reproducible and comparable experiments. As LLMs see deployment in increasingly high-stakes contexts, rigorous, transparent, and extensible evaluation frameworks like Adver are necessary foundations for trustworthy AI safety research.