Neural Computation Without Slots: Steps Towards Biologically Plausible Memory and Attention in Natural and Artificial Intelligence
Abstract: Many models used in artificial intelligence and cognitive science rely on multi-element patterns stored in "slots" - dedicated storage locations - in a digital computer. As biological brains likely lack slots, we consider how they might achieve similar functional outcomes without them by building on the neurally-inspired modern Hopfield network (MHN; Krotov & Hopfield, 2021), which stores patterns in the connection weights of an individual neuron. We propose extensions of this approach to increase its biological plausibility as a model of memory and to capture an important advantage of slot-based computation in contemporary LLMs. For memory, neuroscience research suggests that the weights of overlapping sparse ensembles of neurons, rather than a dedicated individual neuron, are used to store a memory. We introduce the K-winner MHN, extending the approach to ensembles, and find that within a continual learning regime, the ensemble-based MHN exhibits greater retention of older memories, as measured by the graded sensitivity measure d', than a standard (one-neuron) MHN. Next, we consider the powerful use of slot-based memory in contemporary LLMs. These models use slots to store long sequences of past inputs and their learned encodings, supporting later predictions and allowing error signals to be transported backward in time to adjust weights underlying the learned encodings of these past inputs. Inspired by these models' successes, we show how the MHN can be extended to capture both of these important functional outcomes. Collectively, our modeling approaches constitute steps towards understanding how biologically plausible mechanisms can support computations that have enabled AI systems to capture human-like abilities that no prior models have been able to achieve.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
The paper asks: How could a brain remember and pay attention like today’s AI systems, without using “slots” (separate storage places) like a computer does? The authors build brain-inspired models that store memories in the strengths of connections between neurons, rather than keeping each memory in its own dedicated slot. They also explore how a brain-like system might do something transformers do very well: use past information to make good predictions and to learn from future feedback, without literally keeping a long list of past items “active” in memory.
The main questions the paper tackles
- Can we design a memory system that:
- stores each item across a small team of neurons (not in a dedicated slot),
- has a fixed capacity (like real brains),
- and still retrieves old memories well?
- Can we get a brain-like system to capture a key advantage of transformers:
- using past context to predict the future,
- and sending “credit” (learning signals) back to earlier items,
- but without keeping every past item in an active slot?
How the authors approached it (with everyday analogies)
1) Rethinking memory: From “slots” to “shared connections”
- Slot-based memory (like lockers): Many computer models store each memory in its own “locker” (slot). Retrieval means searching all lockers to find the best match.
- Brains probably don’t use lockers. Instead, they adjust the strengths of connections between neurons. Think of it as writing lightly across a shared chalkboard; many memories overlap on the same board.
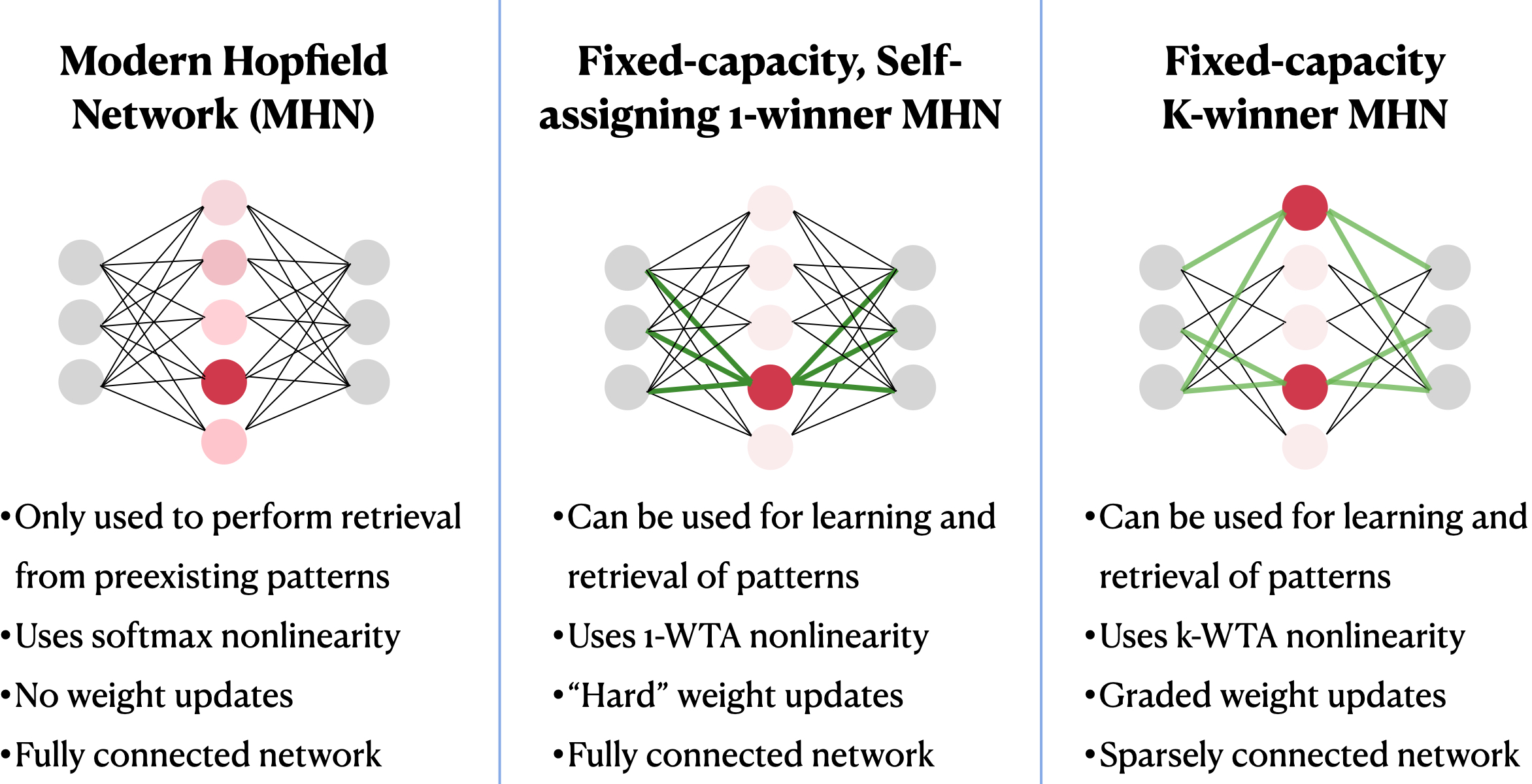
- The authors start from a well-known model called a modern Hopfield network (MHN). In a basic MHN, each memory is linked to one “memory unit” (a bit like assigning a single locker). They make it more brain-like by spreading each memory across a small team of units, not just one.
2) The K-winner MHN: A “small team” wins and learns
- K-winner means: when a new item arrives, the top K most responsive “memory units” (a small team) get to learn it.
- Each of these units tweaks its connection strengths a little, rather than overwriting everything. That way, old memories aren’t wiped out in one shot.
- Sparse connections: Each memory unit only “listens” to part of the input (like a specialist hearing only certain instruments in an orchestra). This is more realistic and efficient.
Key ideas in plain language:
- Pattern completion: If you only see half a picture, can you fill in the rest? These models aim to do that—retrieve a full memory from a partial cue.
- Sensitivity (d′): A score for “how well can you tell a real learned memory from a look-alike?” Higher is better.
3) Rethinking attention and learning over time (transformers without slots)
- Transformers (like those in LLMs) keep a long list of “keys” and “values” from past tokens in slots, and use “queries” to look them up. This makes it easy to learn from future feedback and assign credit back to earlier items—but keeping thousands of past states “active” is probably not how brains work.
- The authors propose storing these keys and values in connection weights rather than in active slots. It’s like carving notches in wood (connection changes) instead of keeping all the lights on (active memory). They explore versions that can still learn from future errors and adjust how past items were represented.
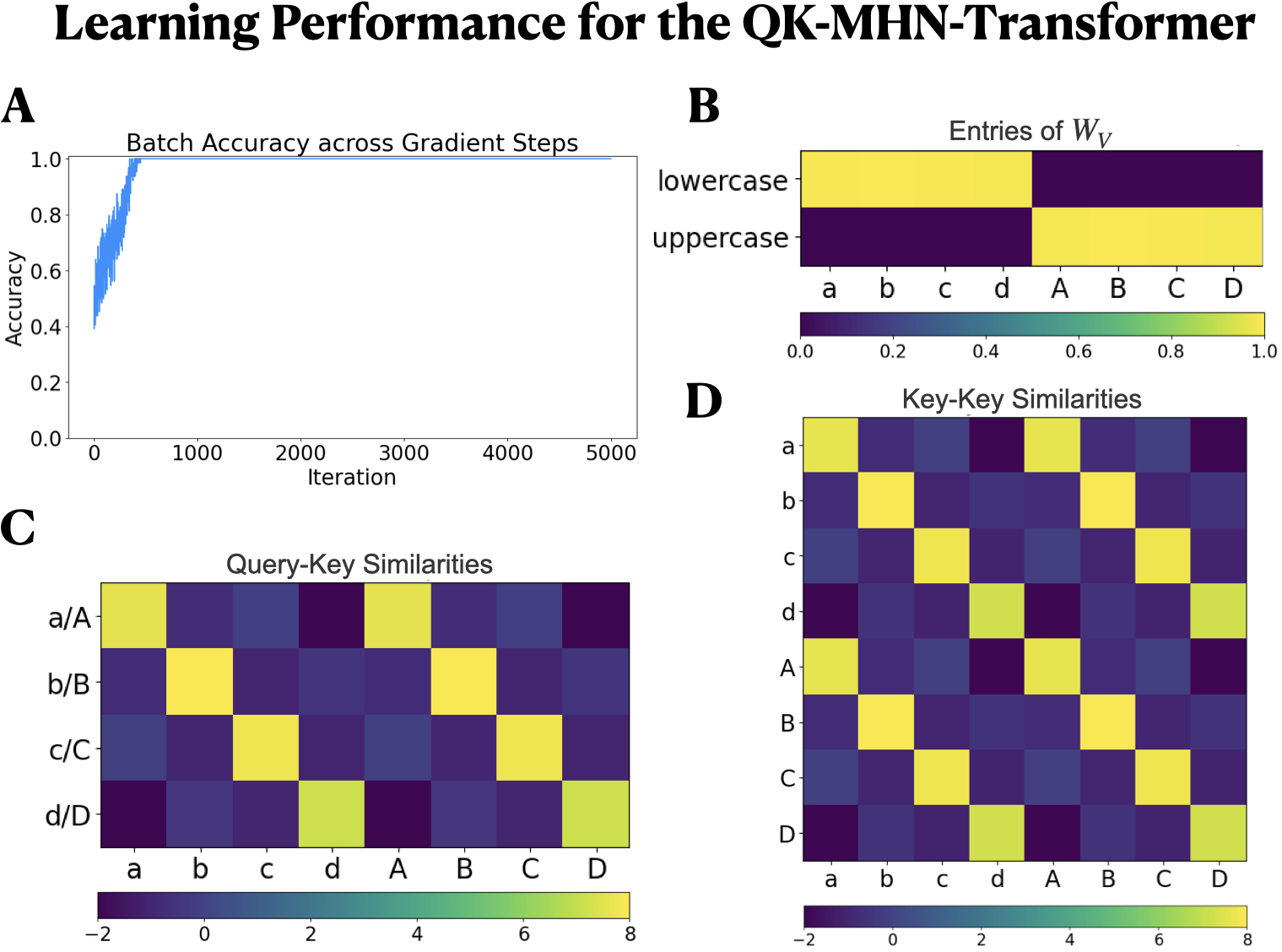
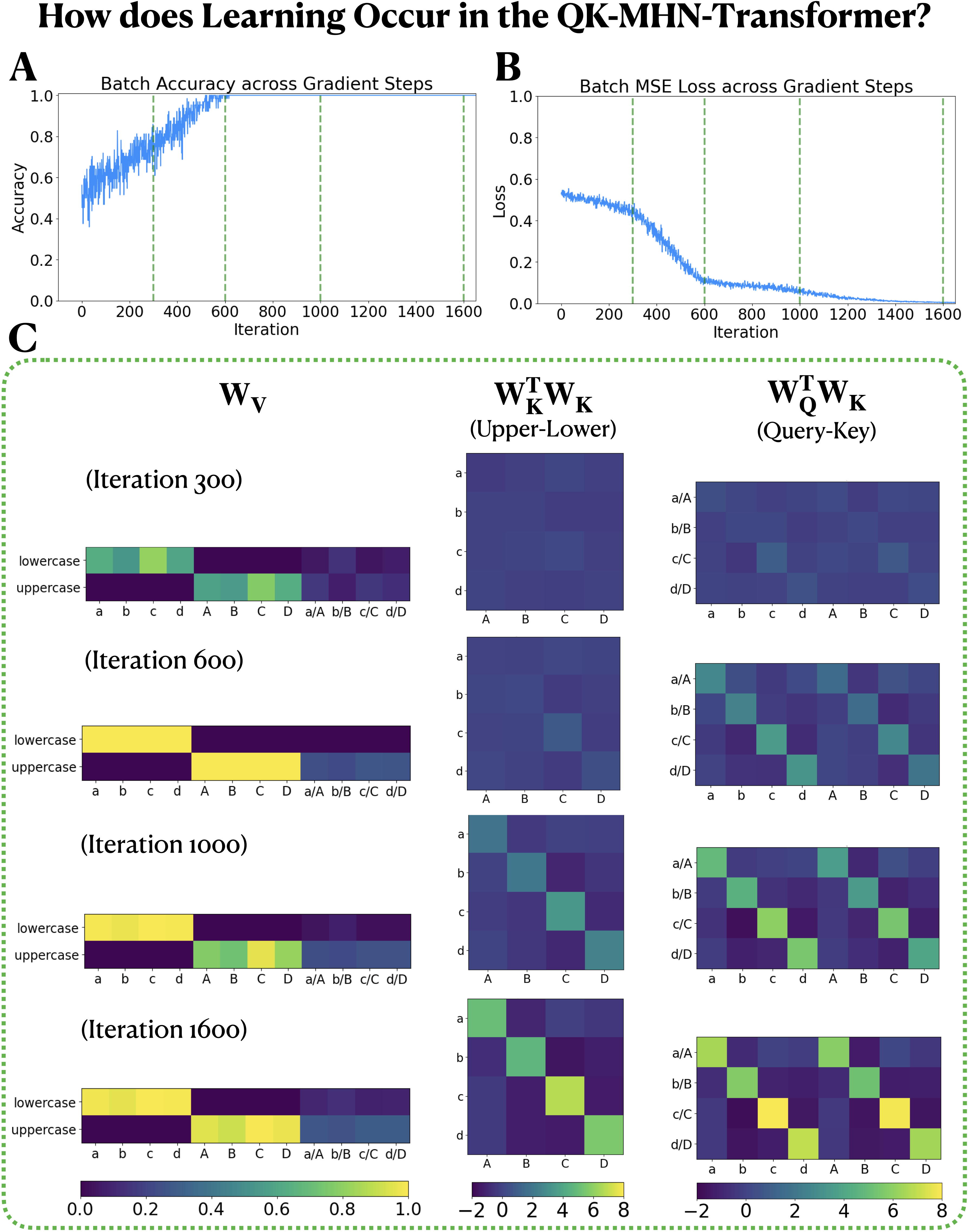
- They test their ideas on a simple “case sequence” task (figuring out a letter’s case—uppercase/lowercase—when asked later), which forces the model to learn useful keys, queries, and values.
What they found and why it matters
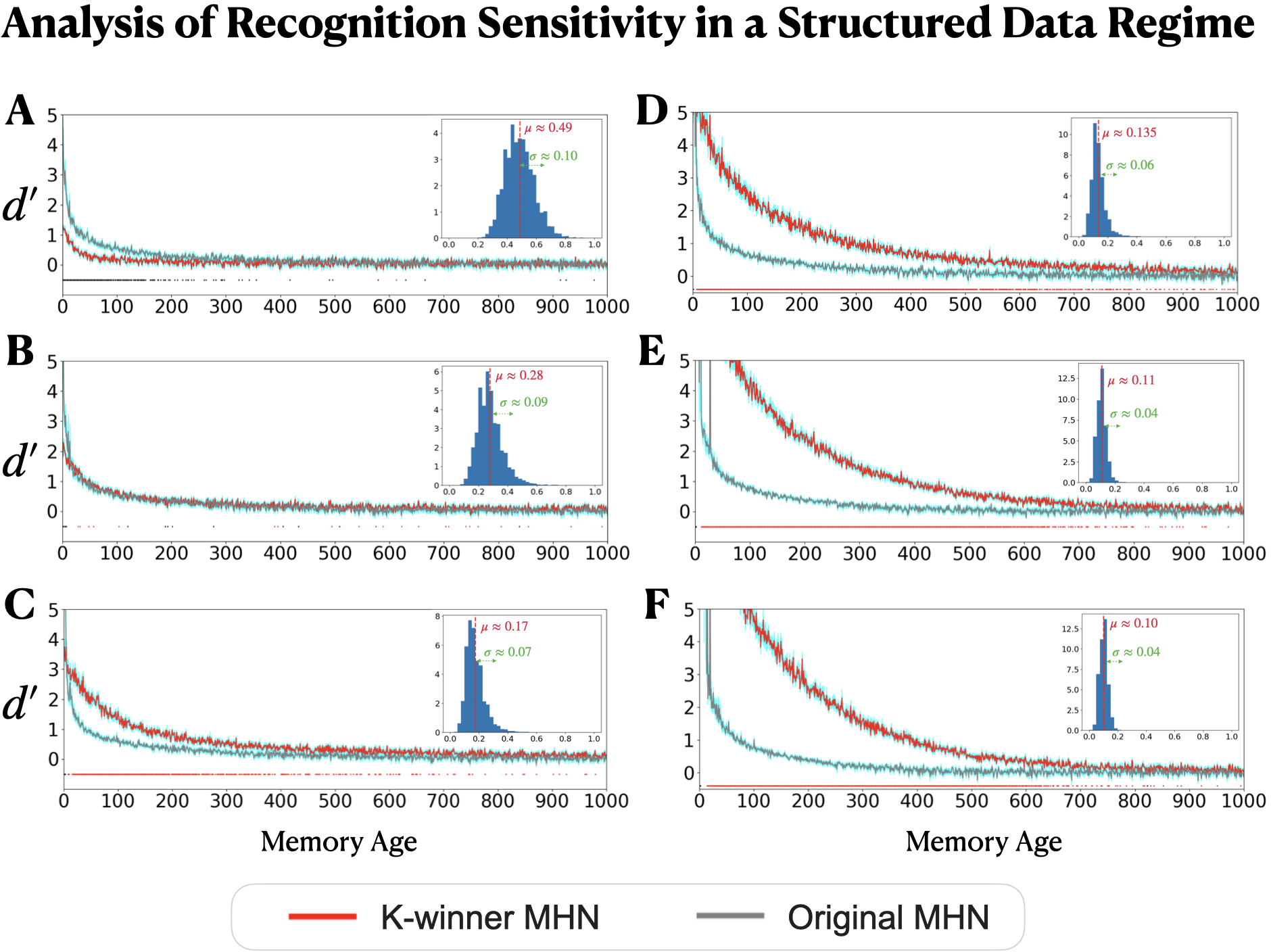
Memory (K-winner MHN) results
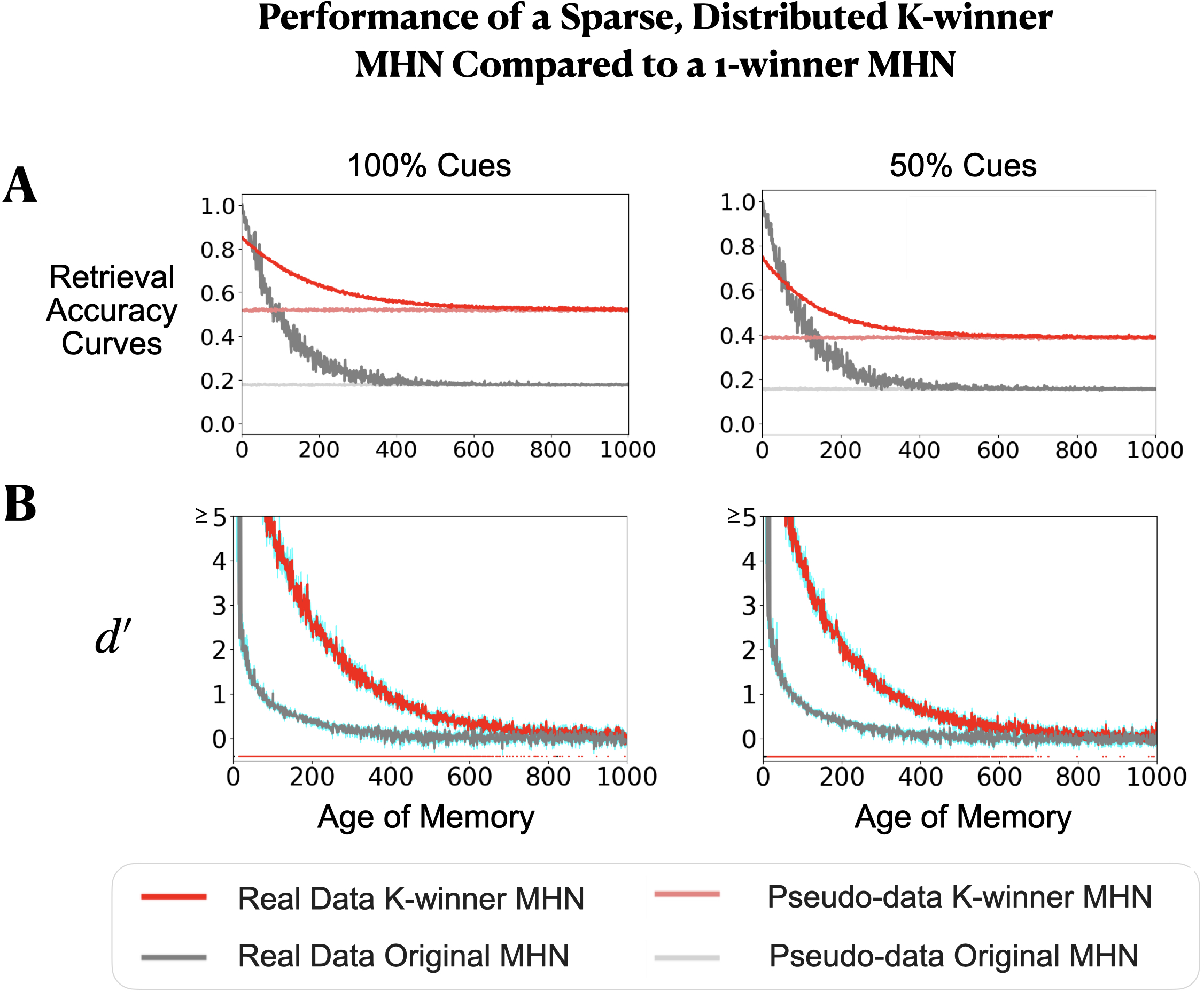
- Better for older memories: Compared to the one-memory-unit-per-item approach (a “1-winner” MHN), the K-winner MHN held onto older memories better. Because each new memory only nudges connection strengths (instead of overwriting a whole slot), old memories fade more slowly.
- Small trade-off for newest items: The very latest memory is sometimes retrieved a little less perfectly than in the 1-winner setup, but the payoff is much better retention over time.
- Partial cues: With incomplete hints (like seeing only half the features), the K-winner model still fills in the rest well—and again keeps older items more accessible.
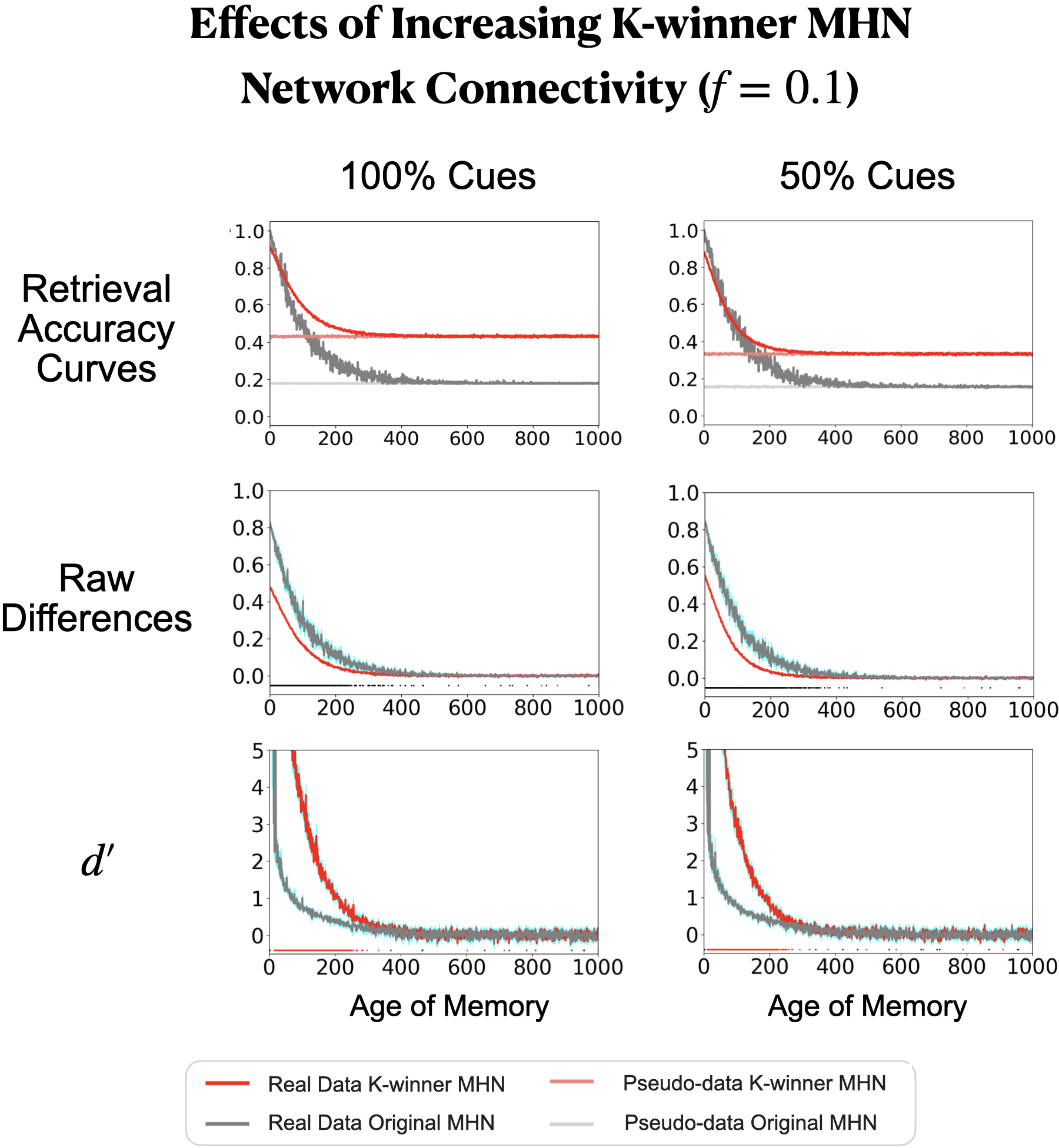
- Connectivity trade-offs: If each unit listens to more of the input (stronger connectivity), initial accuracy can be near-perfect, but very old memories may fade faster. This reveals a real-world trade-off: optimizing for perfect immediate recall vs. long-term retention.
- Structured data: When memories are more similar to each other (like many related items), the K-winner MHN’s advantage depends on how similar they are. With moderate similarity, it still has a strong edge on older memories; with very high similarity, separating items can be harder (a known challenge that brain theories address with “pattern separation”).
Bottom line: Spreading each memory across a small team and learning gradually (instead of all-or-nothing) improves how long memories last, a very brain-like benefit.
Slot-free attention and learning over time
- The authors propose ways to store “keys” and “values” from past items in connection weights instead of active slots, and to still send learning signals back in time to improve earlier representations.
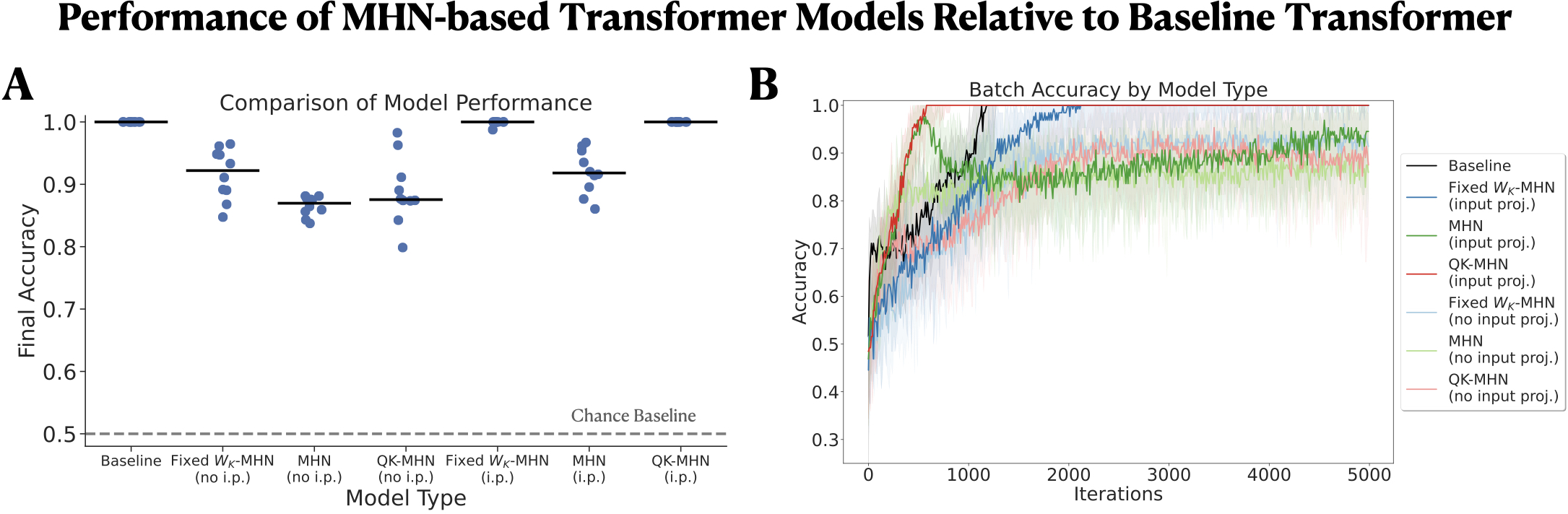
- On a simple, diagnostic task that needs this ability, one of their slot-free variants came close to the performance of a standard (slot-using) transformer.
- This suggests a path toward brain-like attention that achieves transformer-like benefits without the heavy cost of keeping long past sequences actively stored.
Why this is important
- More biologically plausible: The models move away from “one slot per item” toward memory distributed in connection strengths, which aligns better with how many neuroscientists think the brain works.
- Efficient and scalable: Storing information in weights is space- and energy-efficient compared to keeping many items “active.” Brains have vastly more connections than neurons; these models use that fact.
- Bridges AI and neuroscience: The work shows how brain-realistic mechanisms can approach the performance of today’s slot-heavy AI systems, especially on attention and learning from sequences.
What this could lead to
- Better memory systems in AI: Using small teams and gradual updates could help AI keep old memories without forgetting, while still learning new things—useful for lifelong learning.
- Brain-inspired attention: If we can transport learning signals back in time without storing long histories in slots, AI might become more brain-like and more efficient.
- New tools for cognitive science: The models give testable ideas about how the brain might store and retrieve memories, and how it might “attend” to the past without holding everything in working memory.
In short, the paper takes real steps toward AI that remembers and learns in ways that look and feel more like a brain—keeping older memories alive, handling partial information, and learning from sequences—without relying on separate “slots” for each memory.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, consolidated list of what remains missing, uncertain, or unexplored in the paper, framed to be concrete and actionable for future research.
- Lack of formal capacity analysis for the K-winner MHN: derive theoretical storage capacity and retrieval error bounds as functions of , , , , , , and , and compare to classic Hopfield/MHN capacities under continual learning.
- Missing principled selection of and : develop criteria or adaptive policies for choosing and tuning , , and online to balance initial retrieval accuracy versus long-term retention, rather than relying on exploratory simulation picks.
- No mechanism for resource allocation and homeostasis: specify and evaluate biologically plausible policies (e.g., usage balancing, metaplasticity, inhibitory competition) to prevent overuse of the same hidden units and to allocate limited capacity across items and time.
- One-step retrieval simplification: quantify how iterative MHN dynamics (multi-cycle settling) would change retention, pattern completion, and interference compared to the paper’s one-step approximation.
- Symmetric weight assumption is biologically unrealistic: test asymmetric forward/backward connections and assess how this affects storage, retrieval, and stability.
- Binary, hard k-WTA activations limit biological plausibility: evaluate graded activations, stochastic spiking, soft k-WTA, and realistic inhibitory circuits; compare performance/retention to the current binary model.
- Absent pattern-separation module implementation: implement and test a dentate gyrus-like preprocessing layer to reduce input similarity; quantify its impact across the similarity spectrum used in TGCRP trees.
- Limited noise/robustness testing: assess retrieval under synaptic noise, weight drift, sparsity fluctuations, cue corruption beyond 50%, and non-stationary input distributions; measure stability over long timescales.
- Sparse connectivity trade-offs only partially explored: systematically map how impacts initial accuracy, interference, and long-term retention; identify regimes (and rules) where increased fan-in helps without accelerating forgetting.
- No analytical characterization of the similarity threshold where K-winner MHN gains/loses to 1-winner MHN: derive a criterion linking mean overlap/structure to expected advantages, and validate empirically.
- Evaluation restricted to synthetic binary data: benchmark on naturalistic inputs (images, text embeddings, auditory features) and non-binary/continuous patterns; assess ecological validity and generalization.
- Generalization vs exact recall not fully disentangled: design tasks to separately measure (a) exact episodic recall and (b) similarity-based generalization, and quantify trade-offs between these outcomes across models.
- Continual learning without consolidation/replay: incorporate biologically inspired consolidation (e.g., offline replay, synaptic tagging, neuromodulation) and evaluate whether they improve retention without slots.
- No policy for forgetting/prioritization: develop adaptive forgetting/importance weighting strategies (e.g., age-, utility-, or surprise-based) to manage finite capacity under streaming inputs.
- Transformer's slot-free temporal credit assignment remains under-specified: formalize and test local learning rules (e.g., three-factor rules, eligibility traces, tag-and-capture) that approximate backprop-through-time without storing activity sequences.
- Attention computation without slots is unclear at scale: specify how softmax-normalized similarity can be implemented from weight-stored keys at large context lengths, and analyze computational and biological feasibility.
- Hetero-associative MHN variant uses 1-winner units; distributed ensembles not explored: extend hetero-associative MHN to K-winner ensembles for keys/values and evaluate whether this improves retrieval and credit assignment.
- Minimal transformer scope is too narrow: scale slot-free variants to multi-head attention, stacked layers, residual/MLP blocks, and longer contexts; quantify performance gap to standard transformers.
- Capacity and interference in slot-free transformer not quantified: analyze how many past key/value pairs can be stored in weights before severe interference; derive/store-update policies that mitigate this.
- Error signal source and routing in biological approximation is unclear: specify plausible neuromodulatory/global signals that gate local updates, and test whether they suffice for aligning queries/keys and learning values.
- No energy/space efficiency analysis: quantify memory/compute/energy costs of weight-based storage versus slot-based activity maintenance, using realistic synapse/neuromodulation assumptions.
- Mapping to hippocampal circuitry is superficial: build and test a more detailed DG–CA3–CA1-inspired architecture (pattern separation, autoassociative pooling, heteroassociative outputs) and compare to K-winner MHN behavior.
- Reinstatement mechanism not rigorously described or validated: define the “item reinstatement” weights, their learning rule, and demonstrate temporal credit assignment on tasks with longer lags and more confounds.
- In-context learning task is toy-scale and under-described: expand beyond the Case Sequence Task to richer, multi-step reasoning datasets; provide full task specification (e.g., , , data generation, distributions) and test generalization to held-out schemas.
- Absence of formal proofs of equivalence/approximation: prove conditions under which weight-based MHN retrieval approximates transformer attention outputs and gradient transport; quantify approximation error.
- Parameter-matched comparisons may not be compute/fairness matched: supplement parameter-count matching with compute and retrieval-cost analyses to ensure fair comparisons across models.
- Reproducibility and benchmarking: release code/data prior to journal publication; include comprehensive ablations, hyperparameter sweeps, and baselines (e.g., classic Hopfield variants, modern associative memory models).
- Integration of contributions left for future work: design and evaluate a unified architecture combining the K-winner autoassociative memory with the slot-free hetero-associative transformer for end-to-end tasks.
These items identify where additional theory, biological grounding, algorithmic specification, and empirical validation are needed to advance slot-free memory and attention mechanisms toward both biological plausibility and parity with slot-based AI systems.
Practical Applications
Immediate Applications
The following applications can be deployed now, leveraging the paper’s K-winner MHN and slot-free transformer ideas in constrained or domain-specific settings.
- Edge personalization and continual learning on devices (software, mobile, IoT)
- Use case: On-device adaptation for keyboards/autocomplete, smart thermostats, wearables, and camera apps that learn user-specific patterns without cloud storage.
- Workflow: Insert a K-winner MHN “memory layer” that performs local, graded weight updates during use; retrieve via k-WTA from partial cues; manage fixed capacity with a memory budget.
- Tools/products: PyTorch/TensorFlow module for K-winner MHN; an on-device “Memory Controller” to set k, f, ε; retention dashboards with tracking.
- Assumptions/dependencies: Works best when input patterns aren’t excessively similar; requires careful hyperparameter tuning to balance initial accuracy vs retention; on-device privacy policies needed because weights still encode information.
- Energy-aware attention replacement in small models (software, energy, embedded ML)
- Use case: Replace slot-based self-attention in small transformers with weight-based context storage for tasks with simple dependencies (e.g., pattern matching, short-sequence queries).
- Workflow: Swap attention heads with hetero-associative MHN that stores keys/values in weights; query compares against stored keys; values retrieved as weighted combinations without maintaining long activity traces.
- Tools/products: “Slot-free Attention” layer; configuration tooling for temporal credit approximation; inference-time local learning routines.
- Assumptions/dependencies: Comparable performance currently on minimal/structured tasks; inference-time updates challenge standard deployment workflows; GPU/CPU memory savings depend on avoiding large context buffers.
- Robotics local mapping and environment adaptation (robotics)
- Use case: Store recent observations and retrieve from partial cues (e.g., occlusions) to stabilize navigation; resist catastrophic forgetting across brief missions.
- Workflow: K-winner MHN maintains a sparse, distributed memory of recent frames or features; pattern completion aids recognition under partial information; fixed capacity prevents unbounded growth.
- Tools/products: ROS node integrating a K-winner MHN; parameter auto-tuning for fan-in and k; evaluation via retrieval sensitivity () over time.
- Assumptions/dependencies: Preprocessing for pattern separation (e.g., whitening or hashing) may be required in highly structured scenes; interference management with SLAM pipelines.
- Adaptive audio processing in assistive devices (healthcare, consumer electronics)
- Use case: Hearing aids or earbuds learn ambient noise profiles and retrieve denoising parameters from partial cues for recurring environments.
- Workflow: K-winner MHN stores sparse spectral patterns with graded updates; partial cue retrieval completes missing information when environments change abruptly.
- Tools/products: Firmware module for memory-based noise profiling; tuning assistant for sparsity and learning rate.
- Assumptions/dependencies: Benefits highest for moderate similarity noise profiles; must meet latency and battery constraints.
- Session-level recommenders (software, commerce)
- Use case: Fast, ephemeral session memory to adapt recommendations without large slot caches or replay buffers.
- Workflow: Hetero-associative MHN encodes recent actions as keys/values in weights; queries produce context-aware recommendations via similarity-weighted retrieval.
- Tools/products: Microservice that wraps MHN retrieval; “Memory Budget Planner” to manage fixed capacity.
- Assumptions/dependencies: Works best for short sessions; requires drift control and unlearning mechanisms for regulatory compliance.
- Neuroscience simulation and experiment design (academia)
- Use case: Test hypotheses about hippocampal sparse distributed coding, memory retention, and pattern separation using analyses.
- Workflow: Simulate K-winner MHN under varying sparsity and fan-in; design experiments predicting retention vs recency trade-offs; analyze structured vs unstructured stimuli.
- Tools/products: Open-source code for K-winner MHN; analysis scripts for sensitivity and pattern completion.
- Assumptions/dependencies: Mapping model parameters to biological regimes requires care; translation from synthetic tasks to lab paradigms is nontrivial.
- Teaching and curriculum materials (education)
- Use case: Classroom modules demonstrating slot-free memory, pattern completion, and continual learning trade-offs.
- Workflow: Jupyter notebooks illustrating MHN vs K-winner MHN behaviors; exercises on sensitivity and parameter effects.
- Tools/products: Lightweight pedagogy toolkit with ready-to-run demos.
- Assumptions/dependencies: Suitable for introductory to intermediate courses; minimal dependencies beyond standard ML packages.
- Privacy-aware on-device learning (policy, daily life)
- Use case: Reduce exposure of explicit session contents by avoiding long-lived slot buffers; store information in distributed weights.
- Workflow: Adopt slot-free modules; enforce retention windows and decay; provide explainability for weight storage.
- Tools/products: Compliance guidelines and auditing tools for weight-based data retention.
- Assumptions/dependencies: Weights still store personally relevant information; right-to-delete requires unlearning support.
- Energy and retention benchmarking (industry R&D, policy)
- Use case: Evaluate energy savings and retention profiles vs slot-based systems to inform procurement and sustainability goals.
- Workflow: Benchmark tasks with and without slot-free modules; report over ages and energy use; inform policy targets.
- Tools/products: Measurement suite for retention-energy trade-offs.
- Assumptions/dependencies: Hardware differences (GPU vs neuromorphic) affect outcomes; representative tasks needed for fair comparisons.
Long-Term Applications
These applications require further research, scaling, algorithmic development, or hardware co-design.
- Hybrid LLMs with hippocampal-like memory (software/AI)
- Use case: Integrate K-winner MHN modules to improve lifelong learning, reduce catastrophic forgetting, and retrieve older facts or skills.
- Workflow: Augment transformer stacks with weight-based memory and consolidation policies; leverage pattern separation to handle high-similarity inputs.
- Tools/products: “K-winner Memory Layer” for LLMs; consolidation/decay schedulers; compatibility with training pipelines.
- Assumptions/dependencies: Robust temporal credit assignment approximations must scale; training/inference boundaries blur due to local updates; evaluation on realistic tasks needed.
- Slot-free transformers at scale (software, energy, data centers)
- Use case: Reduce VRAM and energy by avoiding long slot buffers in long-context models; store context into weights with local rules.
- Workflow: Develop loss-compatible local learning rules that approximate backprop through time; implement item reinstatement mechanisms to support prediction.
- Tools/products: “Slot-free Attention” library for billion-parameter models; inference-time update and rollback infrastructure.
- Assumptions/dependencies: Stability of online weight updates; accuracy on complex, multi-hop reasoning tasks; co-training strategies to avoid drift.
- Neuromorphic hardware for sparse distributed memory (semiconductors, energy)
- Use case: Exploit synaptic sparsity, k-WTA circuits, and associative arrays for energy-efficient memory and attention.
- Workflow: Co-design chips supporting k-WTA, fan-in constraints, symmetric weight updates; provide SDKs for MHN variants.
- Tools/products: ASICs/accelerators with native k-WTA and local learning; compilers and libraries mapping MHN primitives.
- Assumptions/dependencies: Significant R&D and fabrication costs; ecosystem maturity needed; software-hardware co-evolution.
- Clinical modeling of memory disorders (healthcare)
- Use case: Model retention/interference profiles (e.g., aging, hippocampal pathologies) to inform protocols and interventions.
- Workflow: Fit K-winner MHN parameters to patient data; explore how fan-in/sparsity changes impact trajectories; simulate therapy effects.
- Tools/products: Clinical research platform for slot-free memory modeling; diagnostic decision support.
- Assumptions/dependencies: Data access and validation; ethical and regulatory approvals; translational rigor.
- Adaptive educational platforms using memory curves (education)
- Use case: Tailor spaced repetition schedules to retention dynamics analogous to K-winner MHN, improving durable learning.
- Workflow: Estimate learner-specific “memory parameters”; schedule reviews balancing initial performance vs long-term retention.
- Tools/products: LMS plugins implementing biologically plausible review policies; analytics dashboards for -like measures.
- Assumptions/dependencies: Empirical linkage between synthetic retention and human learning; extensive A/B testing.
- Long-term autonomous robotics (robotics)
- Use case: Persistent map and skill retention across missions without catastrophic forgetting; robust pattern completion under occlusions.
- Workflow: Integrate slot-free memory with SLAM and policy learning; staged consolidation and decay; pattern separation preprocessing.
- Tools/products: Autonomy stack modules for K-winner memory; mission-level retention planners.
- Assumptions/dependencies: Safety certification; real-world robustness; handling highly structured visual similarity.
- Regime-aware financial models (finance)
- Use case: Reduce recency bias; retain signatures of older market regimes with controlled interference.
- Workflow: Use distributed memory to encode regime features and retrieve with partial cues; set capacity and decay strategies.
- Tools/products: Portfolio research toolkit with slot-free memory components; compliance-aware unlearning protocols.
- Assumptions/dependencies: Rigorous backtesting; risk management; regulatory alignment; sensitivity to structural breaks.
- Policy frameworks for energy-efficient and on-device continual learning (policy)
- Use case: Standards and incentives for deploying weight-based memory approaches to reduce energy and data movement.
- Workflow: Define measurement protocols (energy, memory retention); procurement guidelines; privacy and right-to-delete policies for weight-stored data.
- Tools/products: Certification schemes; audit tools for memory and energy metrics.
- Assumptions/dependencies: Cross-industry consensus; enforcement capability; alignment with privacy laws.
- Data governance and unlearning for weight-based memory (policy, software)
- Use case: Methods to remove learned information from distributed weights to comply with user data deletion.
- Workflow: Develop local-rule-compatible unlearning algorithms; audit trails for weight changes; verification procedures.
- Tools/products: Unlearning toolkits; compliance reporting plugins.
- Assumptions/dependencies: Research on effective unlearning in distributed memory; provable guarantees desirable.
- Developer toolkits and products
- Use case: Broad adoption of slot-free memory and attention.
- Workflow: Create libraries and SDKs for K-winner MHN, hetero-associative MHN attention, item reinstatement mechanisms, and memory budget planning.
- Tools/products: “Slot-free Attention” library; “K-winner Memory Layer”; “Memory Budget Planner”; visualization tools for and interference.
- Assumptions/dependencies: Open-source community engagement; maintenance and interoperability with major ML frameworks.
Cross-cutting assumptions and dependencies
- The K-winner MHN’s retention advantage depends on input similarity; high similarity may require pattern separation preprocessing (e.g., whitening, random projections, sparse hashing).
- The slot-free transformer variants currently approach performance on minimal tasks; scaling to complex language, vision, or multimodal tasks needs new temporal credit assignment algorithms compatible with local learning.
- Many deployments assume inference-time updates; production systems must manage stability, rollback, and auditability of changing weights.
- Energy savings are more pronounced on hardware that favors local, sparse updates; conventional GPUs may not fully realize the potential without software optimization or specialized accelerators.
- Right-to-delete and privacy compliance require unlearning capabilities and governance that treat weights as potentially sensitive data.
Glossary
- attention mask: A mechanism in transformers that restricts which tokens can attend to which others by zeroing or disallowing certain attention weights. "This specific architecture entails using an attention mask such that the items do not interact with one another and the query item has access to the keys and values of all previous context items."
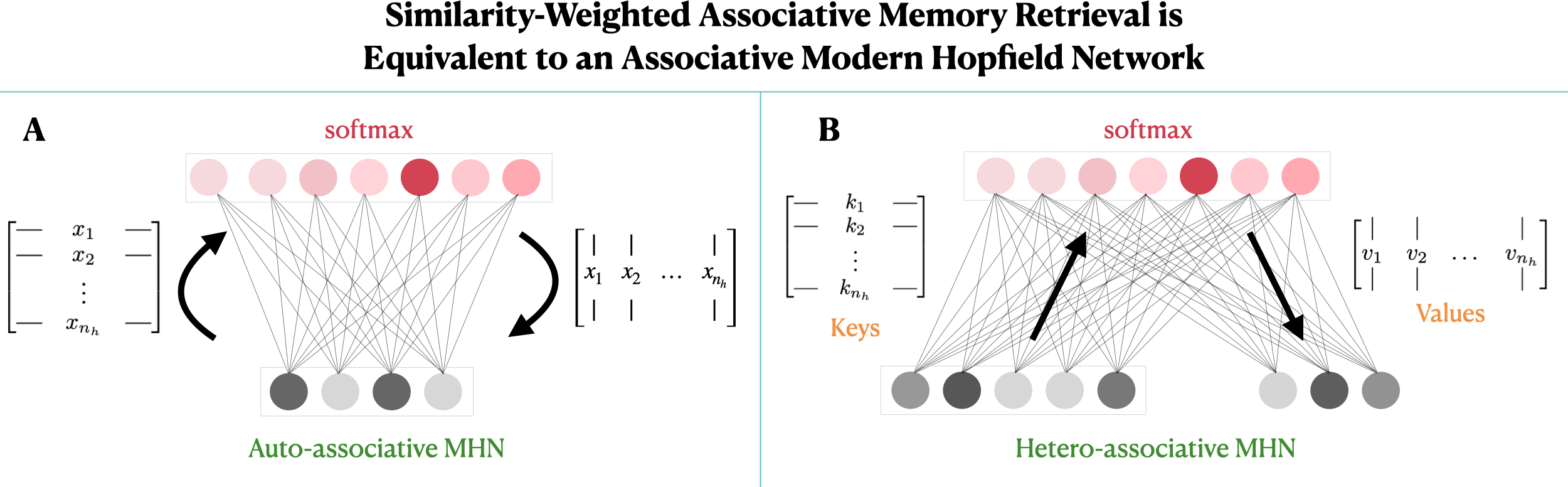
- auto-associative MHN: A modern Hopfield network variant that stores patterns so they can retrieve themselves (the output pattern matches the input). "A. The original auto-associative MHN, as conceived by Krotov and Hopfield \cite{KrotovHopfield2021}."
- autoencoder: A neural network that learns to reconstruct its input via an encoder–decoder structure, often used to realize associative memories. "Such a computation may be realized within an autoencoder architecture with bidirectional connection weights storing the 's."
- backpropagation: The gradient-based learning algorithm that propagates error derivatives from outputs back through network parameters. "it is trained using the backpropagation learning algorithm."
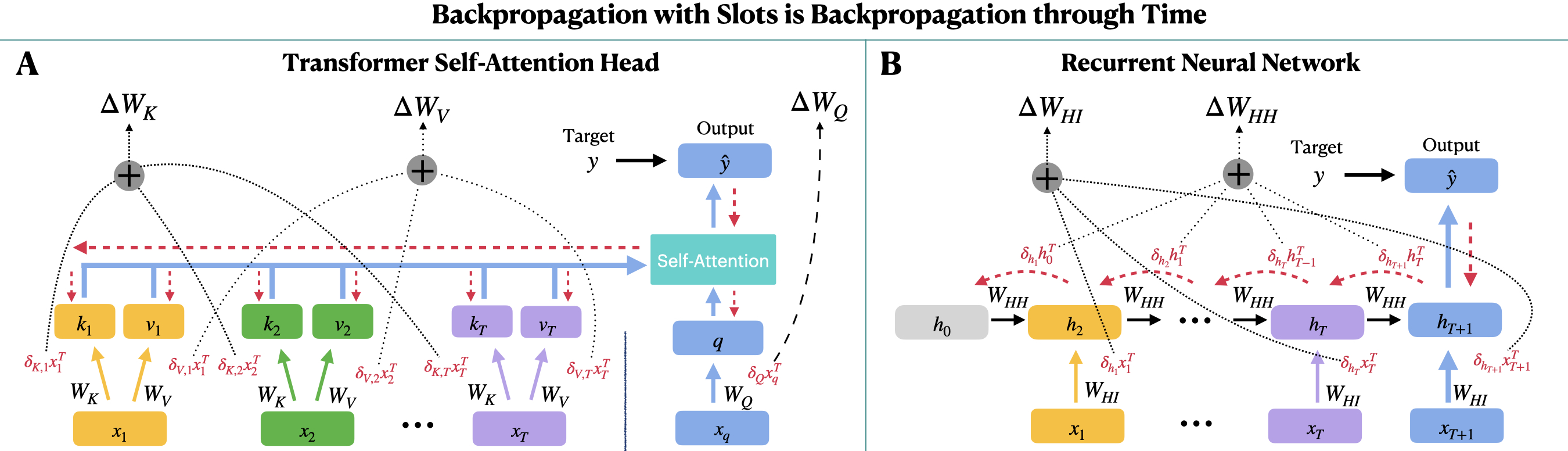
- backpropagation through time (BPTT): The extension of backpropagation to recurrent or sequential models by unrolling through time to assign credit to earlier states. "Notably, retention of long sequences of prior state information is also required for the backpropagation through time algorithm \cite{werbos1990bptt} that is often used to train a wide range of recurrent neural architectures on long temporal sequences of information \cite{hochreiter1997long, van2016wavenet, wu2016google, wang2017learningreinforcementlearn, Wayneetal2018} (Fig. \ref{fig:slotbased_backprop}B)."
- continual learning: Learning from a sequence of tasks or items without resetting parameters, under limited capacity and potential interference. "within a continual learning regime, the ensemble-based MHN exhibits greater retention of older memories, as measured by the graded sensitivity measure , than a standard (one-neuron) MHN."
- decoder-only transformer: A transformer architecture composed of causal decoder blocks that generate outputs conditioned on previous tokens. "decoder-only variants of the transformer as used in GPT models \cite{brown2020gpt3}."
- d' (d-prime): A sensitivity index from signal detection theory quantifying discriminability of signal vs. noise. "as measured by the graded sensitivity measure ,"
- entorhinal cortex: A medial temporal lobe region providing major input to the hippocampus, often modeled as an input stage. "We see the visible layer as a proxy for the input to the hippocampus (i.e., the entorhinal cortex) while the hidden layer is a simplified proxy for the hippocampus."
- episodic memory: Memory for specific events or episodes; in modeling, a slot-like store of distinct experiences. "in cognitive science -- as \"episodic memory\" \cite{botvinick2019reinforcement, lu2022neural, giallanza2024EGO, webb2024relational, Beukers2024working} --"
- external memory: A differentiable memory module or store external to a network’s main parameters, used for slot-based retrieval. "in artificial intelligence -- as \"external memory\" \cite{Graves2014NeuralTM, Graves2016, santoro2016metalearning, pritzel2017neural, Wayneetal2018, Ritter2018beenthere}."
- fan-in: The number or fraction of input connections into a neuron, often used to enforce sparse connectivity. "Additionally, we incorporate the concept of synaptic sparsity via a binary \"fan-in\" matrix "
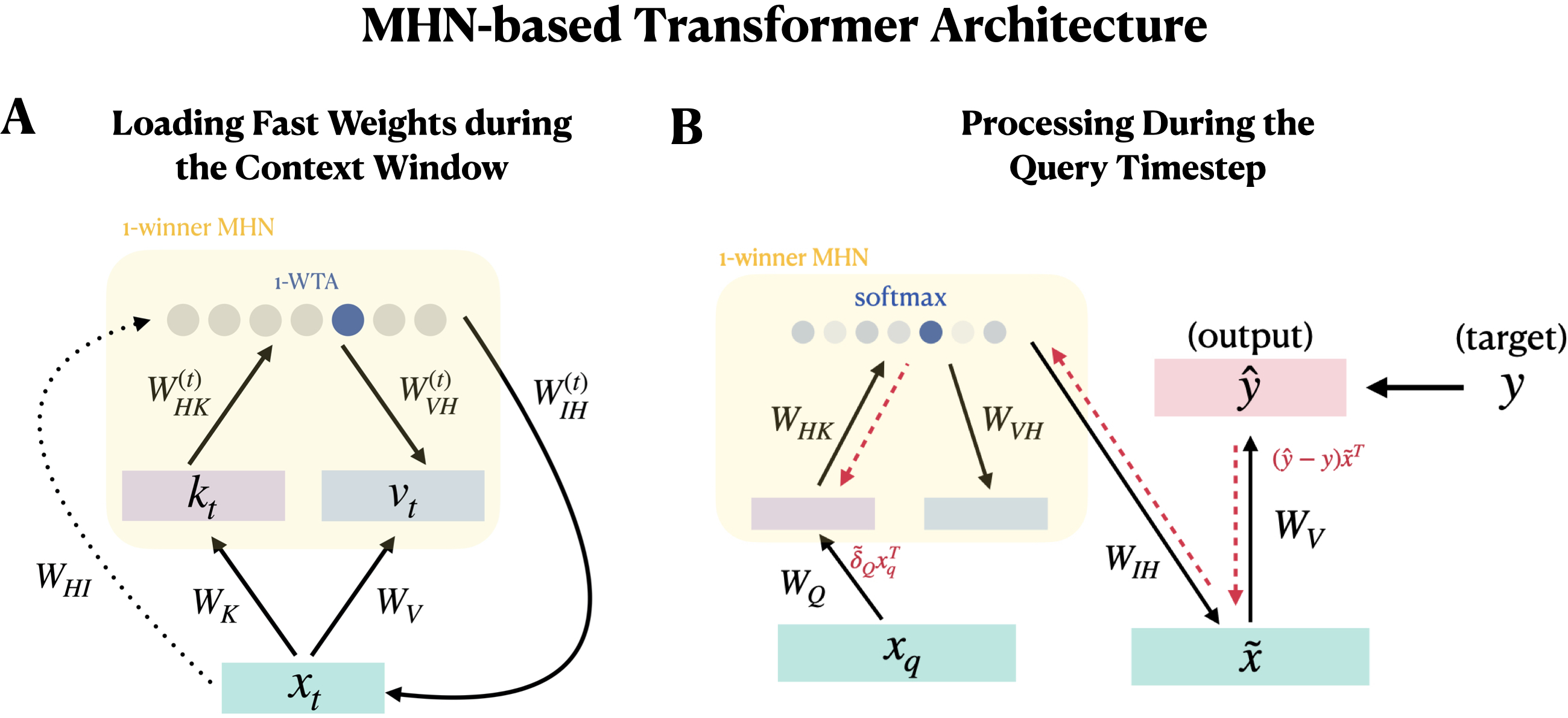
- hetero-associative MHN: An MHN variant that stores associations between different vectors (e.g., keys and values) rather than an item with itself. "B. A hetero-associative MHN that stores pairs of vectors---keys and values---and that uses keys to retrieve associated values."
- hippocampus: A brain region central to episodic memory formation and retrieval. "the hippocampus, the brain region generally viewed as the storage site of episodic memories \cite{squire1992memory}."
- k-winner-take-all (k-WTA): A selection rule that keeps only the top k activations in a layer, setting others to zero. "For simplicity, the functions () are hard k-winner-take-all (k-WTA) functions,"
- K-winner MHN: A proposed MHN extension that stores memories across an ensemble of K “winning” hidden units with sparse connectivity and graded updates. "We introduce the K-winner MHN, extending the approach to ensembles,"
- modern Hopfield network (MHN): A high-capacity associative memory model that stores patterns in connection weights to support rapid retrieval. "the modern Hopfield network (MHN) \cite{KrotovHopfield2021}."
- outer product: The matrix formed by multiplying a column vector by a row vector, used here to express gradient updates. "gradients (shown via red arrows) backpropagate through the self-attention computation and iteratively produce gradient updates (i.e. for the key and value weights) that consist of an outer product between the gradient of a given key or value with the current context item ;"
- pattern completion: The retrieval of a full stored pattern from a noisy or partial cue by settling dynamics or associative lookup. "serve to capture a process called pattern completion, whereby presentation of a noisy or incomplete memory and subsequent iteration of the network for multiple cycles (via the neuron's incoming and outgoing weights) gradually settles to a stable state"
- pseudo-memory: An untrained baseline pattern sampled from the same distribution as memories, used to estimate chance retrieval. "For each age , we also consider an untrained \"pseudo-memory\" (with )"
- self-attention: The mechanism in transformers that computes attention weights over a set of keys and values derived from the same sequence as the query. "The resulting network's computation coincides with that of the transformer self-attention mechanism."
- signal detection theory: A statistical framework for measuring detection performance, including sensitivity indices like d'. "the measure from signal detection theory \cite{green1966signal}"
- slot-based computation: A computational approach that uses dedicated storage “slots” for items, enabling direct retrieval and credit assignment. "slot-based computations lie at the heart of the transformer \cite{vaswani2017attention}---the architectural backbone of today's LLMs---"
- sparse distributed memory: A memory representation where information is distributed across many units with only a small fraction active, often with sparse connectivity. "we consider whether aspects of their behavior can be captured as emergent properties of sparse distributed memory systems."
- sparsity: The property that only a fraction of units in a vector or layer are active (non-zero) at any time. "The visible layer receives binary patterns with fixed sparsity ,"
- temporal credit assignment: Assigning learning updates to parameters responsible for representations at earlier time steps based on later errors. "both in performing query-based retrieval (called 'attention' in such models) and in enabling temporal credit assignment, as we will discuss below."
Collections
Sign up for free to add this paper to one or more collections.