- The paper introduces a novel pipeline that decouples foreground and background dynamic Gaussian splatting using sparse mask supervision to enhance reconstruction fidelity.
- It employs targeted densification and a modified temporal opacity function to accurately capture high-frequency RTD textures and dynamic scene details.
- Quantitative results show up to 3 PSNR improvement with half the model footprint, underscoring its advances in sparse multi-view reconstructions.
Splatography: Sparse Multi-View Dynamic Gaussian Splatting for Filmmaking Challenges
Introduction and Motivation
The complexity of reconstructing photorealistic, dynamic 3D scenes for filmmaking is exacerbated by sparse multiview video (MVV) configurations, especially when budgets or practical constraints preclude dense camera arrays. Standard dynamic Gaussian Splatting (GS) methods, while effective under dense MVV, have limited robustness in sparse settings: they tend to overfit backgrounds and underfit foregrounds, particularly when reflective, transparent, or dynamic (RTD) textures are present—a common scenario in cinematographic content. Moreover, state-of-the-art (SotA) GS approaches typically require dense segmentation or masking, which is infeasible for many real-world scenes due to the presence of RTD phenomena and the complexity of manual mask creation.
The paper "Splatography: Sparse multi-view dynamic Gaussian Splatting for filmmaking challenges" (2511.05152) addresses these core deficiencies by introducing a novel pipeline that disentangles, separately optimizes, and adaptively densifies foreground and background GS representations using a sparse set of masks, specialized objectives, and domain-informed dynamics modeling.
Limitations of Prior Art
Canonical GS pipelines for dynamic scene reconstruction attribute Gaussian importance according to full-image reconstruction quality, which, in sparse MVV, generally allocates more modeling capacity to large, static backgrounds compared to smaller, dynamic foregrounds. This misallocation leads to over-reconstruction artifacts in backgrounds and insufficient modeling of critical, high-frequency foreground details (Figure 1).

Figure 1: Novel views (right) reveal over-reconstructed backgrounds and under-reconstructed foregrounds in SotA GS pipelines.
Attempts to address this via dense per-frame mask priors (e.g., with SAM2 or MiVOS) are stymied by the challenges of accurately segmenting RTD content, such as smoke, fire, or transparent objects, all of which are pervasive in practical filmmaking. Furthermore, current GS methods often struggle with initializing robust canonical representations in the SV3D regime, which negatively affects subsequent dynamic reconstruction performance.
Foreground/Background Disentanglement and Training
The central innovation is to segment the initial canonical GS point cloud at t=0 into foreground (Gf) and background (Gb) components using only a sparse set of binary masks—one per camera. Foreground and background Gaussians are then separately trained using specialized loss functions designed to (a) suppress classic floaters and mask-edge artifacts in the foreground, and (b) attenuate view-dependent occlusions and leakage at the background boundary. This approach improves the initialization balance and interpretability of each component and sets the stage for subsequent tailored dynamics modeling.
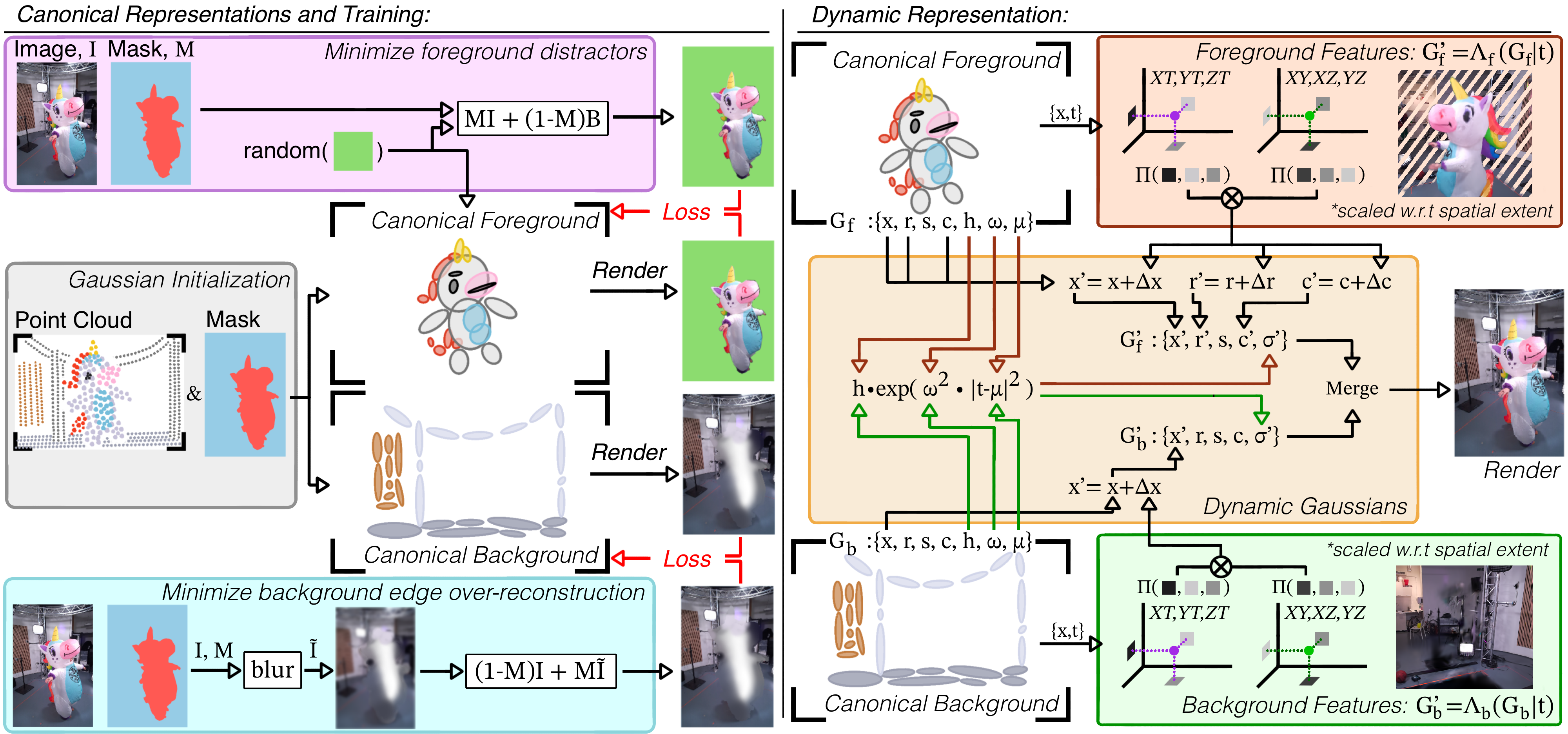
Figure 2: Left: The canonical representation is constructed by masking the initial point cloud and training the foreground and background representations Gf and Gb on specialized objectives to mitigate over-/under-reconstruction. Right: Dynamics for Gf and Gb are decoupled, with Gf receiving full hex-plane modeling and Gb constrained to displacement only.
By treating the foreground and background separately, the method avoids the prevalent error where backgrounds, by virtue of their area, dominate the reconstruction objective in sparse-view scenarios. Foreground attention is maximized with minimal mask supervision.
Dynamics Modeling and Densification
For the dynamic phase, Gf and Gb are associated with separate hex-plane deformation fields. In alignment with cinematographic conventions, backgrounds are assumed to be static or weakly dynamic (e.g., minimal film crew motion, static lighting), so the background deformation field only models spatial displacement Δx. Foregrounds are modeled with higher expressiveness: position, rotation, and color variations are learned via plane-based features.
Densification of GS points is applied exclusively to the foreground using a reference-free, quantile-based scheme. Points undergoing the largest temporal displacements are duplicated, promoting temporal detail preservation only where it is necessary. This avoids the dominant background-driven densification seen in legacy pipelines that use full-reference metrics, which is particularly detrimental in sparse MVV.
Temporal Opacity and Dynamic Textures
Accurate modeling of RTD textures (e.g., flames, smoke, glass) is achieved by a modified event-based temporal opacity function. Unlike prior works using polynomial or stationary models, opacity in Splatography evolves with a mean and bandwidth, enabling modeling both instantaneous and stationary texture transitions. Regularization is introduced to encourage stable, temporally-consistent density and prevent degenerate solutions at texture boundaries or under sparse masking.
Quantitative and Qualitative Results
The method is evaluated on 2.5D and 3D entertainment datasets (ViVo [azzarelli2025vivo], DyNeRF [li2022neural]), with highly sparse camera configurations. Visually, the method reconstructs transparent and semi-transparent dynamics (such as a key-chain, fire, or hands) with fidelity beyond SotA alternatives. Quantitative metrics show up to 3 PSNR higher performance with half the model footprint on 3D scenes; foreground segmentation is also achieved with minimal labeling overhead.

Figure 3: Full and Zoom Temporal Comparison: Only Splatography reconstructs the semi-transparent key-chain in the ViVo-Bassist scene with accurate foreground segmentation and dynamics.
In per-frame and per-view analysis (Figure 4), the method maintains superior and stable PSNR across both test frames and camera viewpoints, indicating successful generalization and dynamic modeling. The reconstructed foreground objects (hands, instruments, moving props) are notably more visually appealing and temporally stable compared to alternative GS techniques.

Figure 4: PSNR plots and zoomed temporal frame comparisons in ViVo-Pianist; Splatography maintains higher and more consistent numerical and perceptual fidelity over time and across views.
On the DyNeRF benchmarks with only four widely separated cameras, alternative methods fail to reconstruct the core RTD features while Splatography successfully models flame and cooking dynamics.

Figure 5: Frame-by-frame test view on the sparse DyNeRF dataset; only Splatography reconstructs masked fire dynamics.
Ablation studies (Figure 6) show that the proposed separation, targeted densification, and updated opacity modeling all contribute to improvements. Unified dynamics, canonical training as in prior work, or legacy densification lead to qualitative or flow metric degradation, especially for high-frequency dynamic content.
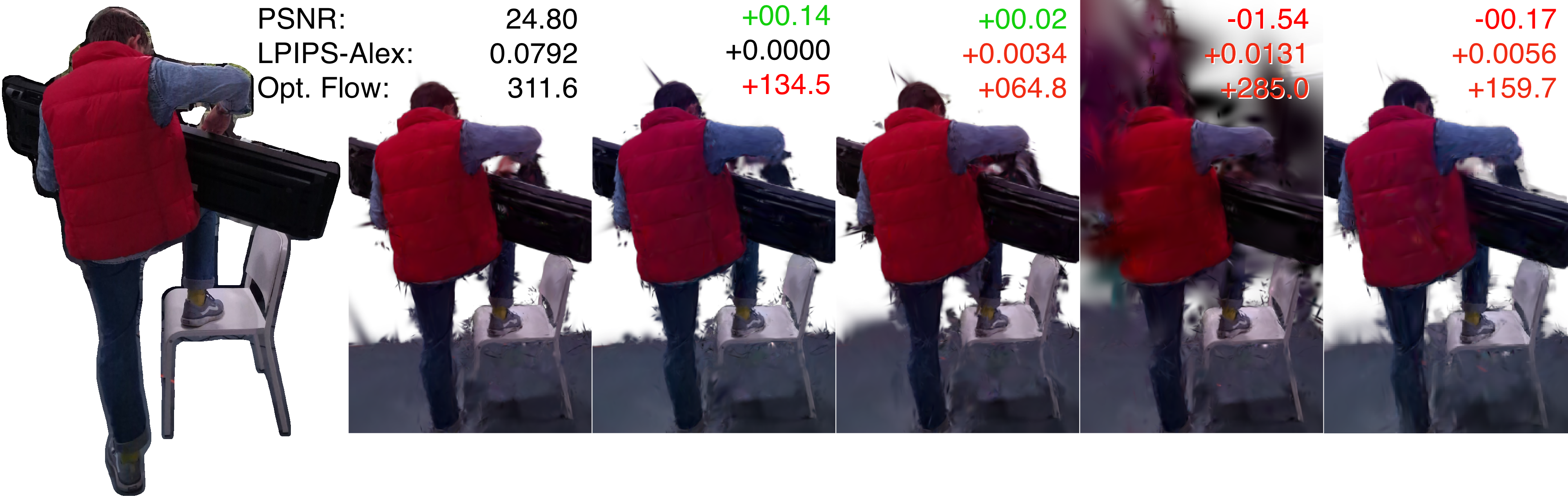
Figure 6: Visual and masked metric results from ablations; Splatography yields sharper foregrounds and better optical flow.
Practical and Theoretical Implications
Splatography demonstrates that robust, photorealistic, and editable dynamic 3D reconstructions are feasible in practical filmmaking environments using sparse MVV, minimal mask supervision, and no precomputed dense segmentations. The foreground/background disentanglement relaxes the requirements for large-scale camera arrays and dense annotation, which are prohibitive in production settings.
From an algorithmic perspective, constraining background dynamics and foreground densification reflects an observation about scene saliency and training signal allocation that is likely to generalize to other structured video capture domains. The approach also provides a basis for future work on unsupervised or weakly supervised segmentation, more efficient scene compression, or integration of additional priors such as depth maps.
Potential Future Directions
Potential extensions include:
- Incorporating implicit or learned priors for RTD texture boundaries, extending robustness to even sparser masks or auto-deduced semantic regions.
- Applying the foreground-background paradigm to human/scene-centric 4D synthesis, particularly for volumetric compression or editing applications.
- Integrating cross-modal cues (audio, IMU) for more robust temporal consistency under extreme sparsity, or leveraging additional sparse sensing (e.g., LIDAR, pseudo-depth).
- Generalizing the dynamic separation framework for unsupervised object-level decomposition in arbitrary scenes.
Conclusion
"Splatography" establishes a state-of-the-art SV3D pipeline for dynamic scene reconstruction under practical filmmaking constraints. Through explicit separation, specialized objectives, and targeted densification, it achieves quantitative and qualitative performance gains on benchmark tasks where classical GS methods fail. The capacity for semantically meaningful segmentation using minimal supervision has direct utility in content creation and post-production, and the architectural insights can inform further developments in dynamic 3D scene representations for sparse capture scenarios.