- The paper presents a comprehensive evaluation of RAG models’ performance in evidence retrieval, selection, and response generation.
- It identifies key shortcomings, including only 22% relevant retrieval and low precision in evidence selection, which undermine factual accuracy.
- The study proposes enhancements such as query reformulation and evidence filtering to boost LLM reliability in medical applications.
Rethinking Retrieval-Augmented Generation for Medicine: A Comprehensive Evaluation
Introduction
The integration of LLMs into the medical field has shown significant potential for diverse applications, such as medical question answering and treatment planning. However, these models face challenges in maintaining up-to-date medical knowledge and providing well-grounded, evidence-based responses. Retrieval-Augmented Generation (RAG) approaches have been proposed to address these issues by enabling models to augment generated outputs with retrieved external evidence. This paper delivers a detailed evaluation of RAG's performance in medical contexts, questioning its reliability in producing factual and evidence-based results.
Methodology
The study undertakes a large-scale expert evaluation, engaging 18 medical specialists who annotated over 80,502 responses across varying RAG configurations using models like GPT-4o and Llama-3.1. The evaluation focuses on three core stages within the RAG framework: evidence retrieval, evidence selection, and response generation.
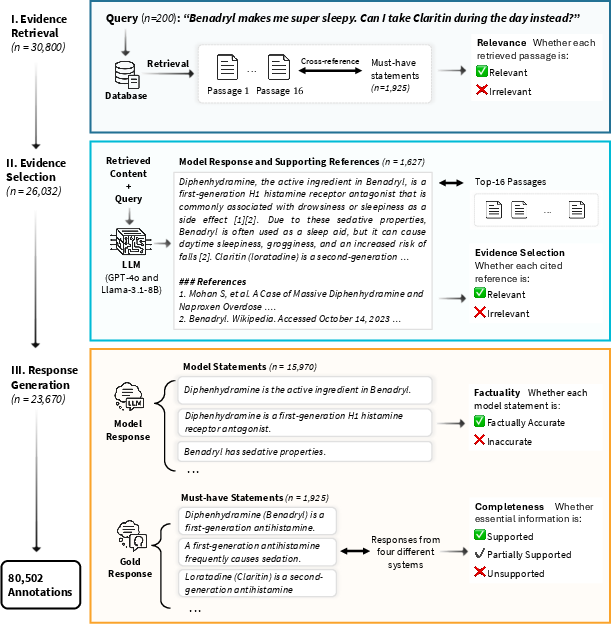
Figure 1: Study design and evaluation framework, highlighting stages such as evidence retrieval, selection, and response generation.
The evaluation method meticulously decomposes the RAG pipeline. The framework begins with assessing the relevance of retrieved passages (evidence retrieval), evaluates the accuracy of the evidence usage in model responses (evidence selection), and finally, examines the factuality and completeness of the generated outputs (response generation).
Findings and Evaluation
Evidence Retrieval
The retrieval process revealed a significant challenge in acquiring relevant passages. Only 22% of the top-16 retrieved passages were deemed relevant, with even lower performance noted for specific query types.
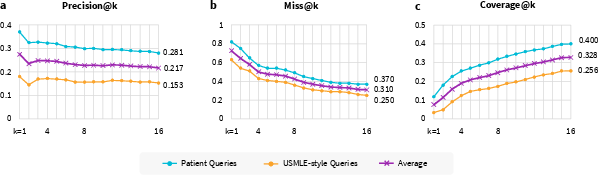
Figure 2: Evidence retrieval performance, indicating poor precision and high miss rates.
The coverage of essential content was limited, often failing to support necessary medical information. This indicates a bottleneck at the retrieval stage, leading to inadequate context provision for the LLMs.
Evidence Selection
Evidence selection posed another challenge, with low precision and recall observed in selecting relevant evidence from retrieved passages. The analysis showed that LLMs frequently incorporated irrelevant content, indicating a poor discernment capability in distinguishing useful information from misleading content.
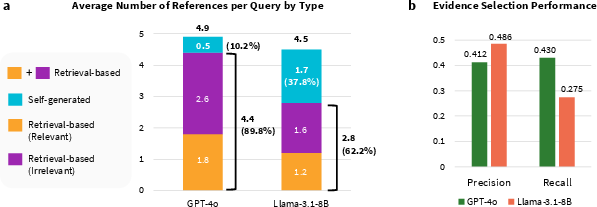
Figure 3: Analysis of citation types and evidence selection performance, highlighting discrepancies between retrieved and self-generated references.
Response Generation
The efficiency of RAG in improving the factual accuracy and completeness of model responses was scrutinized, showing that these models often underperformed when compared to non-RAG models.
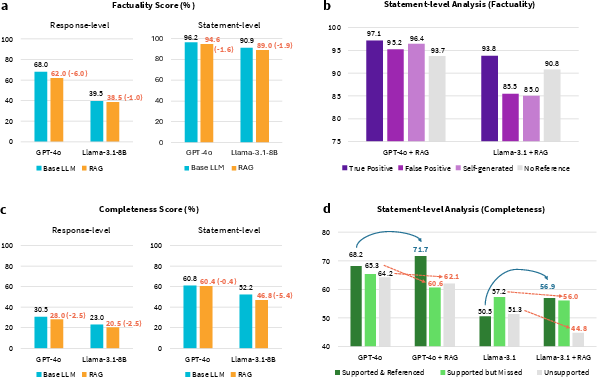
Figure 4: Factuality and completeness analysis of responses, showing consistently lower performance for RAG models.
The research demonstrated that the reliance on irrelevant passages significantly impacted the factuality and completeness of responses, with factuality dropping by up to 6% in some model configurations.
Enhanced RAG Pipeline
To address the challenges identified, the study proposed enhancements to the RAG pipeline, including query reformulation and evidence filtering. These modifications aim to refine retrieval accuracy and effectively filter out irrelevant evidence, thus improving the generation stage's quality.
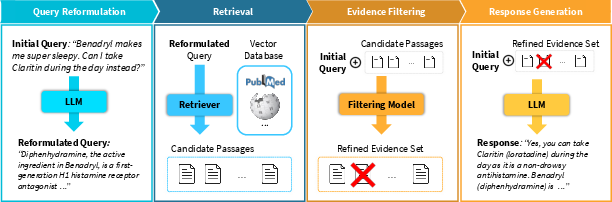
Figure 5: Enhanced RAG pipeline introducing query reformulation and evidence filtering.
These enhancements showed notable improvements across various QA datasets, suggesting that targeted strategies could mitigate some inherent limitations of the standard RAG approach.
Conclusion
The comprehensive evaluation of RAG in medical applications demonstrates several critical shortcomings, particularly in retrieval accuracy and evidence selection. Despite its potential, RAG, in its current form, may not consistently enhance the factual accuracy or usefulness of LLMs. The study underscores the importance of a systematic, stage-aware evaluation of RAG pipelines and highlights the potential benefits of incorporating simple yet effective strategies like evidence filtering and query reformulation to bolster existing frameworks. These findings encourage a reconsideration of RAG's application in medicine and call for innovations to improve LLM reliability in clinical settings.