Large Language Models for Scientific Idea Generation: A Creativity-Centered Survey
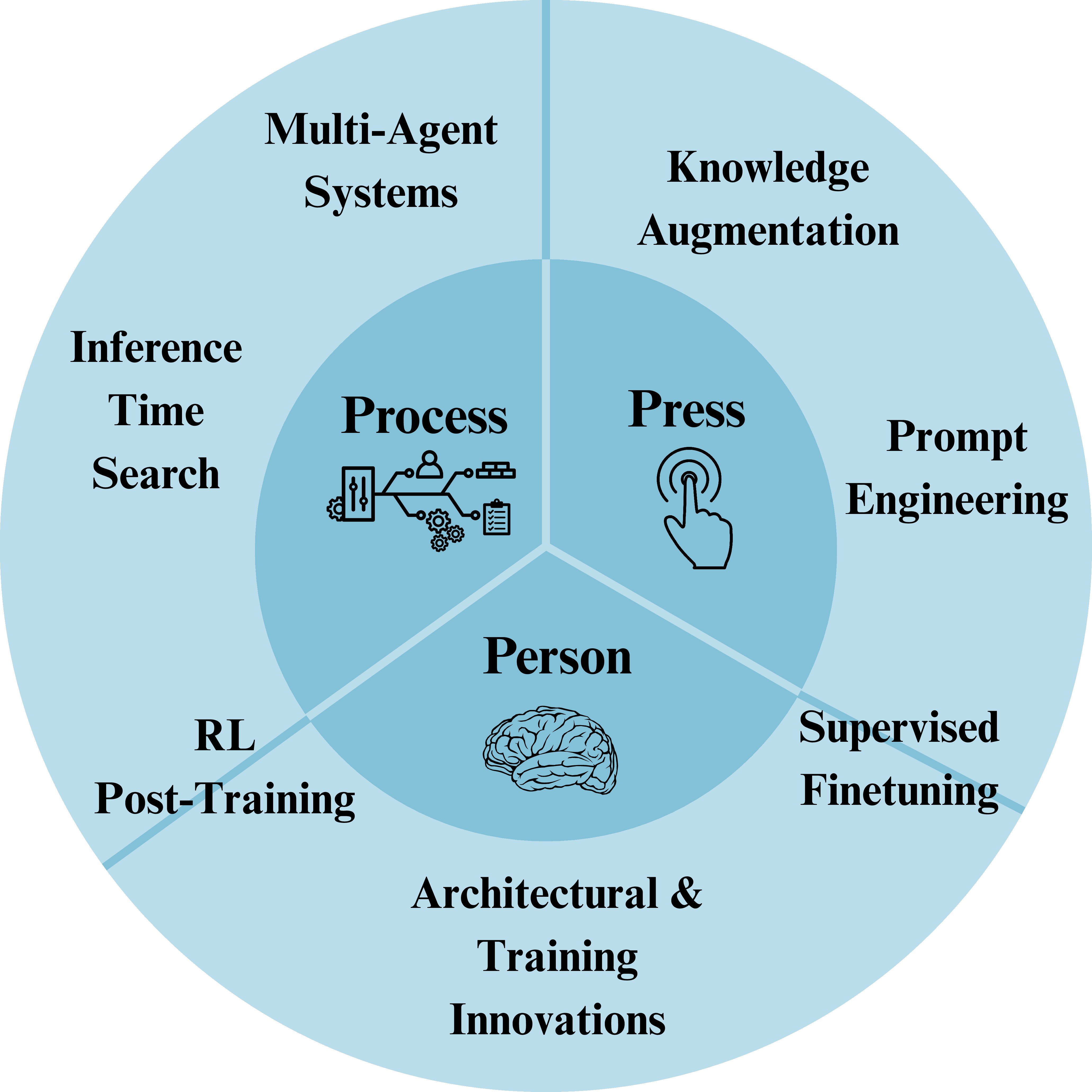
Abstract: Scientific idea generation is central to discovery, requiring the joint satisfaction of novelty and scientific soundness. Unlike standard reasoning or general creative generation, scientific ideation is inherently open-ended and multi-objective, making its automation particularly challenging. Recent advances in LLMs have enabled the generation of coherent and plausible scientific ideas, yet the nature and limits of their creative capabilities remain poorly understood. This survey provides a structured synthesis of methods for LLM-driven scientific ideation, focusing on how different approaches trade off novelty and scientific validity. We organize existing methods into five complementary families: External knowledge augmentation, Prompt-based distributional steering, Inference-time scaling, Multi-agent collaboration, and Parameter-level adaptation. To interpret their contributions, we adopt two complementary creativity frameworks: Boden taxonomy to characterize the expected level of creative novelty, and Rhodes 4Ps framework to analyze the aspects or sources of creativity emphasized by each method. By aligning methodological developments with cognitive creativity frameworks, this survey clarifies the evaluation landscape and identifies key challenges and directions for reliable and systematic LLM-based scientific discovery.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Knowledge Gaps
Knowledge gaps, limitations, and open questions
The paper outlines promising directions for LLM-driven scientific ideation but leaves several concrete gaps and unresolved questions that future work can address:
- Lack of standardized, domain-agnostic benchmarks for scientific ideation that jointly measure novelty and valueness, with time-split decontamination to ensure ideas are genuinely new relative to pretraining and retrieval corpora.
- Absence of validated, operational metrics for Boden’s creativity levels (combinatorial, exploratory, transformational) and their reliable mapping to observed outputs across scientific domains.
- Limited empirical evidence that current methods ever achieve transformational creativity; need protocols and tasks that can elicit and verify conceptual-space changes rather than recombination or exploration.
- No consensus evaluation protocol for predictive validity: do AI-generated hypotheses lead to testable studies and subsequent empirical confirmations over months/years? (i.e., longitudinal, downstream impact studies).
- Insufficient guidance on inter-rater reliability and rubric design for expert human evaluation of scientific ideas (plausibility, feasibility, originality, impact), including cross-discipline comparability.
- Overreliance on LLM-as-judge or RLHF-aligned evaluators without robust defenses against reward hacking, verbosity bias, sycophancy, or superficial plausibility; need adversarially trained or audited verifier suites.
- Poor calibration of internal self-evaluation signals (confidence, self-consistency); need methods to calibrate or debias self-critique and avoid self-reinforcing loops.
- Sparse analysis of how beam/tree search heuristics and pruning criteria systematically bias novelty vs feasibility; need ablations on search breadth/depth vs quality and diversity across domains.
- No established procedures for dynamically selecting and adapting the abstraction level of search nodes (tokens, sub-ideas, hypotheses, study designs) to maximize exploratory potential while controlling cost.
- Limited compute-aware policies for inference-time scaling that balance creativity gains with resource constraints (e.g., anytime algorithms, bandit allocation across branches, Pareto frontiers for novelty/feasibility/compute).
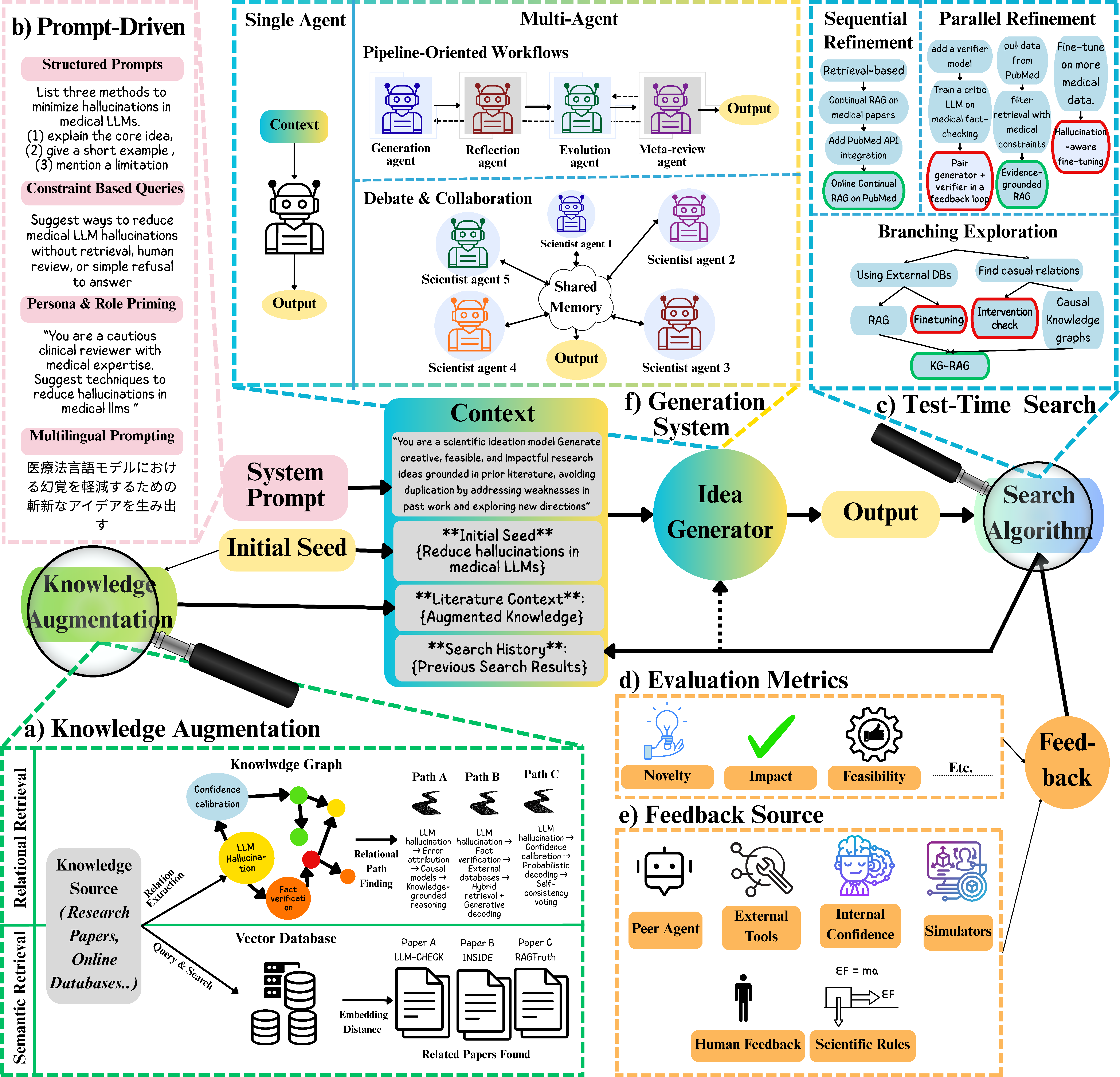
- Lack of principled hybridization of retrieval and exploration: how to couple RAG/KG grounding with explicit divergence mechanisms (e.g., counterfactual retrieval, contradiction-seeking retrieval, novelty-biased sampling).
- Retrieval bias toward well-represented clusters remains unresolved; need algorithms that explicitly promote cross-disciplinary “distant links” (e.g., KG path planning with novelty priors, controllable semantic distance).
- Confirmation bias under RAG when external evidence conflicts with parametric knowledge; need methods for presenting balanced/conflicting evidence and training models to productively reconcile disagreement.
- Limited understanding of when knowledge graphs vs semantic retrieval most enhance creativity; need decision policies and hybrid controllers that switch or combine them based on task and gap structure.
- Data and tooling gaps for constructing, updating, and validating large-scale, domain-spanning KGs tailored for ideation (coverage, quality assurance, temporal/versioning, provenance).
- Prompt-driven creativity remains bounded by alignment constraints that reduce entropy and diversity; need safe mechanisms to temporarily relax “safety/normality priors” during ideation and re-tighten them during filtering.
- No systematic recipes for persona/role design that reliably increase novelty without sacrificing correctness or injecting bias; need libraries of audited personas and automated persona selection/adaptation.
- Constraint/adversarial prompting shows promise but lacks safeguards against degenerate solutions; need principled constraint schedules and fallback mechanisms to avoid infeasible or nonsensical outputs.
- Multilingual prompting as a creativity scaffold is underexplored for science; need multilingual evaluation sets, methods to mitigate translation drift, and analyses of cross-cultural knowledge effects on scientific novelty.
- Limited studies on multi-agent creativity mechanics: how agent diversity, debate protocols, and heterogeneity (different models/tools) affect genuine ideation vs echo chambers or “debate theater.”
- Missing stopping and consensus criteria for multi-agent systems that prevent unproductive loops while preserving unconventional hypotheses; need convergence diagnostics and diversity-preserving aggregation.
- Insufficient evidence that multi-agent deliberation yields more than combinatorial/exploratory creativity; need controlled experiments isolating debate, critique, and role specialization effects on creativity levels.
- Parameter adaptation (SFT/RL) for scientific creativity is under-specified: where to source high-quality training signals for novelty and feasibility, how to avoid overfitting to evaluator quirks, and how to retain factual grounding.
- Lack of datasets and reward models explicitly targeting scientific novelty (not just diversity) with domain-specific safeguards against hallucination and speculative overreach.
- Architectural limits of autoregressive transformers for creativity are hypothesized but untested; need comparative studies with architectures featuring long-term memory, program synthesis, world models, or neuro-symbolic components.
- Minimal exploration of “agent-level search” and open-ended algorithms (e.g., quality-diversity, novelty search) adapted to scientific ideation, and how to couple them with rigorous feasibility filters.
- Tool/ecosystem integration is incomplete: simulators, digital twins, and lab automation as feedback sources need reliability assessments, fidelity calibration, and protocols for safely closing the loop with real experiments.
- Unclear governance for high-novelty ideas that may be unsafe or unethical; need policy-aware filters, risk-classification pipelines, and escalation to human oversight during ideation and dissemination.
- Human–AI co-creativity workflows are not standardized: how to allocate tasks between scientists and models, measure synergy, minimize cognitive load, and ensure proper attribution and reproducibility.
- Limited cross-domain generalization analyses: methods validated in biomedicine or materials are rarely tested in physics, social sciences, or ecology; need broad, stratified benchmarks and transfer studies.
- Missing ablation studies on end-to-end pipelines combining retrieval, prompting, search, multi-agents, and parameter adaptation; need to quantify incremental gains and interactions between components.
- Provenance and decontamination practices for training/validation corpora are underspecified; need transparent pipelines to ensure novelty claims are not artifacts of data leakage.
Collections
Sign up for free to add this paper to one or more collections.