Sparking Scientific Creativity via LLM-Driven Interdisciplinary Inspiration
Abstract: Despite interdisciplinary research leading to larger and longer-term impact, most work remains confined to single-domain academic silos. Recent AI-based approaches to scientific discovery show promise for interdisciplinary research, but many prioritize rapidly designing experiments and solutions, bypassing the exploratory, collaborative reasoning processes that drive creative interdisciplinary breakthroughs. As a result, prior efforts largely prioritize automating scientific discovery rather than augmenting the reasoning processes that underlie scientific disruption. We present Idea-Catalyst, a novel framework that systematically identifies interdisciplinary insights to support creative reasoning in both humans and LLMs. Starting from an abstract research goal, Idea-Catalyst is designed to assist the brainstorming stage, explicitly avoiding premature anchoring on specific solutions. The framework embodies key metacognitive features of interdisciplinary reasoning: (a) defining and assessing research goals, (b) awareness of a domain's opportunities and unresolved challenges, and (c) strategic exploration of interdisciplinary ideas based on impact potential. Concretely, Idea-Catalyst decomposes an abstract goal (e.g., improving human-AI collaboration) into core target-domain research questions that guide the analysis of progress and open challenges within that domain. These challenges are reformulated as domain-agnostic conceptual problems, enabling retrieval from external disciplines (e.g., Psychology, Sociology) that address analogous issues. By synthesizing and recontextualizing insights from these domains back into the target domain, Idea-Catalyst ranks source domains by their interdisciplinary potential. Empirically, this targeted integration improves average novelty by 21% and insightfulness by 16%, while remaining grounded in the original research problem.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper introduces Idea-Catalyst, a tool that helps researchers come up with creative, cross‑discipline ideas. Instead of jumping straight into running experiments, it focuses on the early “brainstorming” stage. It uses AI (LLMs, or LLMs—smart text tools like chatbots) to fetch useful ideas from other fields and combine them with a researcher’s own field. Think of it as a helpful matchmaker that connects a problem in one subject with clever solutions from other subjects.
What the authors wanted to find out
In simple terms, the paper asks:
- How can we help scientists think more creatively by borrowing ideas from different fields without getting stuck too early on one solution?
- Can an AI assistant find ideas from distant fields (like psychology or sociology) that actually help with problems in computer science, biology, and more?
- Does a structured way of brainstorming lead to ideas that are more novel (new) and insightful (thought‑provoking), while still being relevant?
How the approach works
The authors design a step‑by‑step process that mirrors “thinking about your thinking” (this is called metacognition). Here’s the basic flow, explained with everyday analogies:
- Start with a goal: You give the tool a short description of your research problem (for example, “improve how humans and AI work together”).
- Break it into questions: Like turning a big homework task into smaller, clearer questions so you know what to tackle first.
- Spot the gaps: The tool searches scientific papers in your field to see what’s already known and where people are still stuck. It separates “technical details” from “big idea” problems that keep causing trouble.
- Rephrase the problem in everyday terms: It rewrites the tough, field‑specific challenge in plain, general language. This makes it easier to compare to other subjects.
- Look across other fields: It searches other disciplines (like psychology, sociology, control theory) for similar problems and the principles they use to solve them. Analogy: If your bike keeps wobbling, maybe a principle from tightrope walking helps—balance is balance, even in different settings.
- Recontextualize (remix) the insight: It translates those outside ideas back into your field’s language and shows how they could help your specific problem.
- Prioritize the best ideas: It ranks the “idea fragments” by their potential—how novel they are, how well they address the gap, and how plausible they seem.
Technical note in simple terms:
- “Retrieval” means the tool uses online scientific databases to grab short, relevant text snippets from papers.
- “LLM” means a powerful text‑prediction program that can read, summarize, and rewrite ideas clearly.
What they found and why it matters
Main results:
- Ideas produced by Idea-Catalyst were, on average, 21% more novel and 16% more insightful than ideas from other AI brainstorming methods the authors tested.
- The ideas stayed grounded in the original research problem instead of becoming vague or unrealistic.
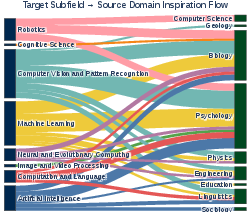
- The system avoided being stuck in the same field and successfully pulled helpful concepts from distant disciplines.
Why this is important:
- Big breakthroughs often happen when different fields inspire each other (like how modern machine learning got ideas from psychology and control theory). This tool makes that kind of cross‑pollination easier and more systematic.
- It focuses on the brainstorming phase, which is when being too strict or testing too early can kill creativity. By keeping things exploratory and structured, it helps researchers think wider without drifting into nonsense.
How they tested it (in simple terms)
- They used a collection of real research cases where one field inspired another.
- Their AI tool (an LLM) generated cross‑field ideas, and another AI (plus human checks) compared these ideas against known, published inspirations.
- They also compared Idea-Catalyst with two common baselines: one that just grabs sources freely, and another that retrieves in both the target and source fields but without the careful “abstract‑then‑match” process. Idea-Catalyst did better on novelty and insightfulness.
What this could lead to
- Better human‑AI teamwork in research: The tool can act like a creative partner, nudging scientists to consider useful ideas they might never think to search for.
- More boundary‑breaking discoveries: By making cross‑discipline thinking easier, this approach could speed up breakthroughs in areas like healthcare, climate science, and AI safety.
- Smarter AI assistants: It shows how future “AI co‑scientists” can support creativity—not just automate experiments—by guiding the early thinking process in a structured, open‑minded way.
In short, Idea-Catalyst helps researchers keep an open mind, borrow the best ideas from other fields, and turn those into promising directions—without getting locked into one solution too soon.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to be actionable for future research.
- Lack of large-scale human expert evaluation across disciplines: outcomes are primarily judged by an LLM (gpt-oss-120b) with minimal reported human studies; no inter-rater agreement, domain calibration, or expert panel validation is provided.
- Limited ecological validity: no longitudinal or real-world studies showing that Idea-Catalyst’s fragments lead to executed projects, publications, or downstream scientific impact in lab or field settings.
- Evaluation bias and ceiling effects: comparing to a single “ground truth” inspiration from CHIMERA may penalize equally valid but different interdisciplinary links; no protocol for judging alternative-but-sound inspirations.
- No statistical significance reporting: improvements (e.g., +21% novelty, +16% insightfulness) lack confidence intervals, variance, or significance tests; robustness of gains is unclear.
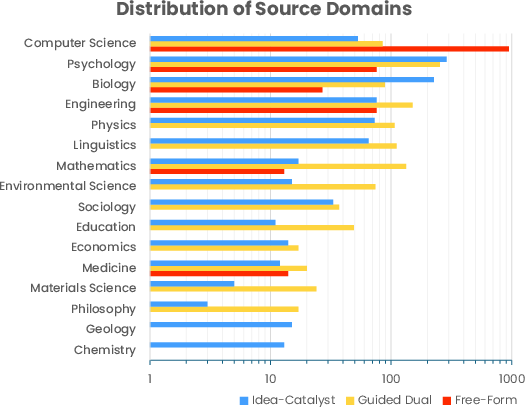
- Generalization across domains is untested: evaluation focuses on arXiv/CHIMERA (CS-heavy) cases; performance in wet-lab sciences, medicine, social sciences, and engineering with different norms and data types is unknown.
- Sparse analysis of model dependence: only Qwen3-14B is evaluated for generation and a single judge model is used; sensitivity to model size, architecture, prompting strategies (e.g., chain-of-thought), and instruction-tuning remains unexplored.
- Unknown robustness to parametric knowledge leakage: although retrieval is time-gated, LLMs may still recall post-cutoff knowledge; there is no control for or analysis of leakage via parametric memory.
- Black-box retrieval limitations: reliance on Semantic Scholar Snippets API provides no control over indexing, ranking, or snippet quality; recall, precision, and coverage (e.g., non-English, paywalled, or non-arXiv domains) are not evaluated.
- Retrieval parameter sensitivity is unreported: choices like top-k=20, majority relevance >50%, and query formulation are not stress-tested; no ablation on retrieval depth, domain filters, or alternate search engines/corpora.
- Relevance determination pipeline is opaque: how “relevance” is assessed for pruning and takeaway extraction (LLM prompts, criteria, thresholds) is not specified or validated for reliability.
- Domain-distance heuristic is underspecified: “exclude nearby subfields” is described qualitatively; no formal distance metric, threshold tuning, or analysis of the novelty–feasibility trade-off as a function of domain distance.
- Abstraction faithfulness is unvalidated: transforming domain-specific questions into domain-agnostic forms risks loss of nuance or mis-specification; there is no human or automated check for semantic fidelity of abstractions.
- No mechanism to detect or mitigate superficial analogies: the system lacks structured analogical mapping or structural correspondence checks to prevent shallow cross-domain transfers.
- Integration fidelity and provenance are weakly enforced: while takeaways cite papers, there is no fine-grained evidence tracking (e.g., claim–snippet alignment) or fact-checking to guard against hallucination or misinterpretation.
- Ranking by “interdisciplinary potential” lacks operational clarity: criteria (depth of integration, innovation payoff, etc.) are qualitative; scoring/rubric design, calibration, inter-rater reliability, and sensitivity to criteria weights are not provided.
- Self-evaluation bias in ranking is unaddressed: if the same (or closely related) LLM performs both generation and pairwise ranking, preference bias may inflate performance; no cross-model or human-in-the-loop ranking audits are reported.
- Limited baseline coverage: comparisons omit state-of-the-art ideation systems (e.g., SCIMON, IdeaBench leaders, interactive tools like DiscipLink/IdeaSynth) and human brainstorming baselines, restricting conclusions about relative gains.
- No study of user experience or cognitive load: despite metacognition framing, there is no assessment of how the framework affects researchers’ mental workload, trust, controllability, or iterative refinement behaviors.
- Scalability and compute cost are unclear: the number of questions, domains, retrieval rounds, and pairwise comparisons could grow combinatorially; runtime and memory profiles, and pruning strategies are not quantified.
- Handling conflicting or incompatible source insights is unaddressed: the framework lacks strategies for reconciling contradictory theories across domains or for surfacing assumptions that limit transferability.
- Transition from exploration to feasibility is undefined: there is no principled mechanism or trigger for shifting from ideation to grounding/validation, risking impractical or unimplementable ideas.
- Domain coverage and inclusivity gaps: focus on English-language, text-only snippets may miss non-textual knowledge (figures, code, datasets) and non-English or gray literature critical in some fields.
- Limited support for multi-modal and formal knowledge: the approach does not integrate equations, symbolic formalisms, or knowledge graphs/citation networks that could improve analogy quality and domain selection.
- Sparse ablations on metacognitive components: beyond a few high-level ablations, there is no fine-grained evaluation of each metacognitive behavior (self-awareness, context awareness, strategy selection, goal management, evaluation).
- Fragile reproducibility: stochastic generation (temperature=0.7) and external APIs may yield non-deterministic outputs; seeds, versioning, and run-to-run variability are not reported.
- Ethical and credit considerations are not discussed: mechanisms for proper attribution of source-domain ideas, avoidance of misappropriation, and equitable recognition across disciplines remain unexamined.
- No error taxonomy: the paper lacks an analysis of failure modes (e.g., trivial analogies, mis-scoped challenges, irrelevant domains, hallucinated takeaways) and targeted mitigations.
- Applicability to low-resource target domains is uncertain: it is unclear how the framework performs when the target-domain literature is sparse or nascent, or when ground truth is limited.
Practical Applications
Below are practical, real-world applications that flow from the paper’s methods and findings, organized by time horizon. Each item notes likely sectors, tools/workflows that could emerge, and assumptions or dependencies that affect feasibility.
Immediate Applications
- Interdisciplinary brainstorming assistant for R&D teams
- Sectors: software, robotics, materials, pharma/biotech, energy
- Tools/workflows: a web app or Slack/Teams bot that ingests a 1–2 sentence problem statement, decomposes it into research questions, retrieves literature snippets, proposes ranked “idea fragments” with references
- Assumptions/dependencies: access to Semantic Scholar Snippets (or an alternative retrieval stack); organizational approval for AI-assisted ideation; LLM quality and guardrails to reduce hallucinations; secure handling of proprietary prompts
- Grant and manuscript ideation support
- Sectors: academia, healthcare research, government labs
- Tools/workflows: Overleaf/Zotero/Mendeley plugin that surfaces unresolved challenges and cross-domain inspirations, with citations and “interdisciplinary potential” rankings for motivating sections
- Assumptions/dependencies: compliance with journal and funder policies on AI use; accurate citation retrieval and deduplication; human oversight to ensure scholarly integrity
- Patent landscaping and inventive-step generation
- Sectors: IP/legal, corporate R&D across industries
- Tools/workflows: workflow that maps a target problem to domain-agnostic challenges, retrieves prior art (papers + patents), suggests non-obvious cross-domain combinations for novelty
- Assumptions/dependencies: integration with patent databases (USPTO, EPO, WIPO); legal review; careful provenance tracking to avoid IP contamination
- Product and feature strategy ideation via cross-domain analogies
- Sectors: software, consumer electronics, fintech, healthtech
- Tools/workflows: PRD assistant that decomposes product goals, flags open challenges (e.g., user trust/calibration), pulls analogies from psychology/sociology/control theory, and ranks candidate directions
- Assumptions/dependencies: linking to internal product telemetry and design docs improves relevance; requires privacy controls and approval workflows
- Enterprise knowledge reuse across divisions
- Sectors: large multi-domain companies (e.g., conglomerates, pharma, aerospace)
- Tools/workflows: internal retrieval-augmented “Idea-Catalyst” that maps unresolved problems in one unit to solutions and frameworks from other units/domains
- Assumptions/dependencies: enterprise search across walled-garden corpora; taxonomy for “domain-agnostic challenges”; data access controls
- Editorial and peer review novelty support
- Sectors: academic publishing, conferences
- Tools/workflows: reviewer dashboard module that highlights whether a submission’s contributions overlap with prior solutions, flags potential cross-domain inspirations authors may have overlooked
- Assumptions/dependencies: integration with publisher databases; clear positioning as an aid (not a gatekeeper); bias and false-positive monitoring
- Interdisciplinary curriculum builder and classroom activity tool
- Sectors: education (undergraduate capstones, graduate seminars, professional programs)
- Tools/workflows: LMS plugin that generates question decompositions, curated cross-domain readings, and ranked idea fragments for team projects
- Assumptions/dependencies: instructor oversight; curated domain sets to avoid off-target suggestions; stable API access for literature snippets
- Policy option scanning and evidence synthesis
- Sectors: public policy, public health, urban planning, education policy
- Tools/workflows: policy-lab assistant that reframes a policy challenge (e.g., vaccine uptake, traffic safety) into domain-agnostic questions, retrieves solutions and mechanisms from other sectors (e.g., behavioral econ, safety engineering), and ranks options
- Assumptions/dependencies: policy-relevant datasets and literature corpora; ethical review to avoid overgeneralizing evidence across contexts
- Translational research ideation in healthcare
- Sectors: hospitals, clinical research, quality improvement teams
- Tools/workflows: lab-notebook plugin to identify persistent clinical challenges (e.g., adherence), surface social/behavioral science mechanisms, and propose testable interventions
- Assumptions/dependencies: IRB and clinical safety oversight; careful separation of ideation from clinical decision support; integration with medical bibliographic sources (e.g., PubMed)
- Research portfolio planning and roadmapping
- Sectors: corporate and academic R&D management, venture studios
- Tools/workflows: dashboard that aggregates a program’s problem statements, identifies partially addressed vs. open conceptual gaps, and ranks cross-domain bets by interdisciplinary potential
- Assumptions/dependencies: alignment with organizational strategy; periodic refresh; human-in-the-loop prioritization to balance novelty and feasibility
- Creativity benchmarks and LLM evaluation/training
- Sectors: AI research, ML product teams
- Tools/workflows: adopt the paper’s structured outputs, CHIMERA-derived data, and prompts to evaluate ideation along novelty/insightfulness/usefulness; train models with preference signals for interdisciplinary creativity
- Assumptions/dependencies: licensing and redistribution permissions; careful validation that LLM-judge preferences align with expert judgments in target fields
Long-Term Applications
- Autonomous “co-scientist” that couples metacognitive ideation with execution
- Sectors: life sciences, materials, energy, robotics
- Tools/workflows: closed-loop systems that ideate, design, and (carefully) trigger experiments or simulations; maintain separation between exploratory ideation and feasibility checks to avoid premature convergence
- Assumptions/dependencies: robust lab automation; strong safety/ethics governance; traceable provenance from idea to experiment; high-accuracy retrieval across multi-modal sources
- Cross-domain knowledge graph linking domain-agnostic challenges to mechanisms
- Sectors: knowledge management, AI research tooling
- Tools/workflows: continually updated ontology that maps “conceptual challenges” to theories, mechanisms, and exemplars across fields; supports explainable transfer
- Assumptions/dependencies: sustained curation; community standards for taxonomy; multilingual, multi-disciplinary coverage
- Secure enterprise-grade interdisciplinary ideation platform (SaaS)
- Sectors: highly regulated industries (finance, healthcare, defense)
- Tools/workflows: on-prem or VPC deployment; connectors to internal document stores; audit trails; risk tiers for cross-domain suggestions
- Assumptions/dependencies: security certifications; red-teaming for dual-use concerns; integration with DLP and access controls
- Personalized ideation models tuned to an organization’s corpus
- Sectors: any knowledge-intensive enterprise
- Tools/workflows: fine-tuned LLMs that learn favored frameworks, past successes/failures, and domain boundaries to yield more actionable fragments
- Assumptions/dependencies: sufficient high-quality internal data; continual learning pipelines; governance for model drift and bias
- Policy co-design platforms with transparent interdisciplinary provenance
- Sectors: government, NGOs, international development
- Tools/workflows: participatory tools that present options with evidence trails, cross-domain analogies, and assumptions; support scenario analysis and stakeholder negotiation
- Assumptions/dependencies: structured policy datasets; reproducible evidence chains; calibration of transferability between domains and jurisdictions
- Multi-modal ideation (papers, patents, code, datasets, protocols, figures)
- Sectors: software/ML, chemistry, bioengineering
- Tools/workflows: retrieval and synthesis across patents, code repositories, datasets, and experimental protocols to build richer idea fragments
- Assumptions/dependencies: high-quality parsing of non-text modalities; license-compliant use; improved grounding to reduce hallucinations
- Education: adaptive tutors for interdisciplinary reasoning
- Sectors: higher education, workforce upskilling
- Tools/workflows: tutors that teach metacognitive strategies (decomposition, challenge abstraction, source-domain search), provide feedback on novelty/usefulness, and track skill growth
- Assumptions/dependencies: validated assessment rubrics; alignment with accreditation/academic integrity policies
- Safety and ethics layers for cross-domain transfer
- Sectors: all, with emphasis on dual-use risk areas
- Tools/workflows: risk classifiers that detect sensitive cross-domain mappings (e.g., optimizing spread dynamics), apply constraints, and route to human review
- Assumptions/dependencies: up-to-date risk ontologies; governance boards; continuous monitoring for misuse
- Global, open benchmark and leaderboard for creative ideation
- Sectors: AI research community
- Tools/workflows: standardized tasks and human+LLM judging protocols for interdisciplinary novelty/usefulness; community submissions and peer review
- Assumptions/dependencies: consensus on evaluation criteria; mechanisms to reduce gaming and maintain diversity of domains
- Multilingual, cross-cultural interdisciplinary ideation
- Sectors: international academia and industry
- Tools/workflows: ingestion of non-English literature and regional policy documents; culturally aware mapping from challenges to solutions
- Assumptions/dependencies: multilingual LLMs and retrieval; partnerships to expand corpora; bias mitigation and validation with local experts
- Human–AI collaboration environments (AR/VR-enabled) for live “idea fragment” co-creation
- Sectors: design, architecture, advanced manufacturing, robotics
- Tools/workflows: collaborative canvases where teams pose problems and receive ranked cross-domain fragments in real time; track selection, critique, and synthesis paths
- Assumptions/dependencies: ergonomic interfaces; logging for provenance; studies showing impact on team creativity and outcomes
Notes on feasibility across applications
- Core dependencies: reliable literature retrieval (Semantic Scholar Snippets or enterprise alternatives), high-quality LLMs, and a taxonomy for “domain-agnostic challenges.”
- Human-in-the-loop: many applications require expert oversight to validate relevance, avoid superficial analogies, and transform fragments into executable plans.
- Risks/bias: overemphasis on distant domains can yield infeasible ideas; English-language and field-coverage biases may skew outputs; LLM-judge preferences may not fully align with experts in specialized areas.
- Governance: IP, privacy, and dual-use concerns require traceable provenance, clear policies on AI assistance, and domain-appropriate safety reviews.
Glossary
- Ablation: A controlled removal of components in a system to assess their individual contributions to performance. "We evaluate three ablations to assess the contribution of individual components of Idea-Catalyst"
- AI co-scientists: A paradigm where AI systems assist or automate stages of scientific research such as ideation and experimentation. "has explored the notion of AI co-scientists, in which LLMs support (and in many cases automate) key stages of the research process"
- Black-box operation: Treating a process where internal workings are hidden as a module with known inputs and outputs. "this allows us to treat snippet retrieval as a black-box operation"
- Coarse-grained: Describing an analysis or categorization at a high, broad level rather than detailed granularity. "at a coarse-grained level of similarity"
- Conceptual takeaways: Literature-grounded, distilled insights capturing principles or mechanisms, independent of implementation details. "we only extract literature-grounded conceptual takeaways"
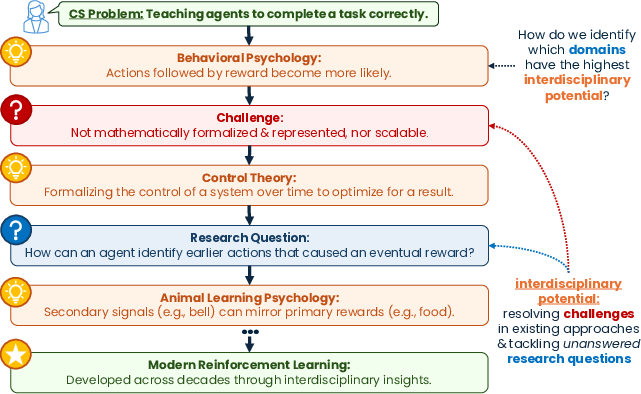
- Control theory: A mathematical framework for modeling and regulating dynamic systems. "control theory for formalization"
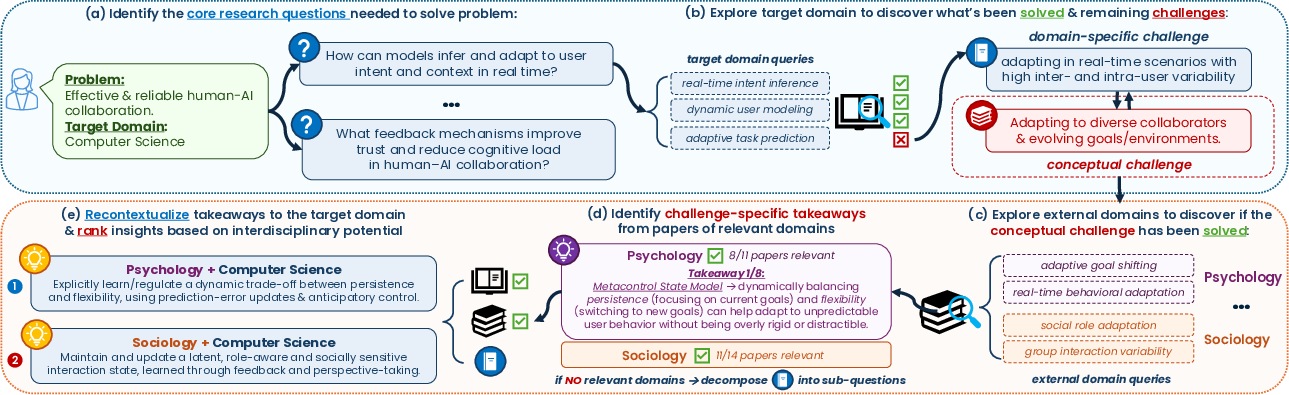
- Domain-agnostic: Independent of the terminology and assumptions of any particular field; applicable across domains. "These challenges are reformulated as domain-agnostic conceptual problems"
- Domain-specific formulation: A version of a question or problem expressed using the language and assumptions of a particular field. "Each question q_i is represented in two forms: a domain-specific formulation"
- Ground truth: The reference or gold-standard answer used for evaluation or comparison. "we present both the generated output and the ground truth to an LLM judge"
- Human-in-the-loop: An approach that keeps humans involved in the decision or design cycle of AI systems for guidance and oversight. "interactive, human-in-the-loop approaches"
- Idea fragment: A structured, partial proposal linking a target-domain challenge with source-domain concepts and rationale for integration. "We define an idea fragment as a structured, intermediate representation"
- Interdisciplinary potential: The expected value of a cross-domain idea for advancing a problem by addressing conceptual gaps and introducing non-trivial perspectives. "Interdisciplinary potential denotes the expected value of an idea fragment"
- Interdisciplinary synthesis: The integration of ideas from different fields to create more impactful, innovative contributions. "interdisciplinary synthesis yields substantially higher long-term impact"
- Just-in-time adaptive interventions: Timely, context-sensitive supports delivered dynamically to aid goal pursuit or behavior change. "Goal pursuit can be supported through just-in-time adaptive interventions that monitor behavior and provide context-sensitive support."
- LLM judge: A LLM used to evaluate and compare the quality of generated outputs. "we present both the generated output and the ground truth to an LLM judge"
- Metacognition: Awareness and regulation of one’s own thinking and reasoning processes. "A central component of this process is metacognition: the ability to monitor, evaluate, and regulate one’s own reasoning"
- Metacognition-driven: Guided by self-monitoring and regulation strategies to structure reasoning and problem solving. "Idea-Catalyst is a metacognition-driven framework"
- Metacontrol State Model: A cognitive framework describing how behavior balances persistence and flexibility to adapt to changing conditions. "Metacontrol State Model: Goal-directed behavior reflects a balance between persistence (maintaining current goals) and flexibility (switching goals when conditions change)."
- Normalized entropy: A scaled measure of diversity or uncertainty, adjusted to allow comparisons across different distributions. "normalized entropy H_{\text{norm} = 0.326"
- Pairwise comparisons: An evaluation method that compares items two at a time to determine relative preference or ranking. "we conduct pairwise comparisons between idea fragments"
- Parametric knowledge: Information encoded in the parameters of a trained model, as opposed to retrieved from external data at inference time. "these systems typically rely on either user input or the LLM’s parametric knowledge"
- Preference-based evaluation: An assessment approach where outputs are compared and judged based on relative preferences rather than absolute scores. "We follow established practices in preference-based evaluation"
- Recontextualizing: Adapting insights from one domain to fit the assumptions, language, and constraints of another. "By synthesizing and recontextualizing insights from these domains back into the target domain"
- Retrieval-augmented: Enhanced by bringing in external documents or snippets during generation or reasoning. "Our retrieval-augmented, hierarchical ideation framework"
- Secondary reinforcement signals: Rewards that acquire value through association with primary rewards, guiding learning and behavior. "secondary reinforcement signals"
- Semantic Scholar Snippets API: A service that returns relevance-ranked text passages from scientific papers given a query. "using the Semantic Scholar Snippets API"
- Source domain: An external field from which transferable concepts are drawn to address challenges in the target domain. "A source domain D_s is a scientific field distinct from the target domain"
- Target domain: The primary field in which the research problem is situated and to which solutions are ultimately applied. "The target domain D_{target} denotes the primary scientific field"
- Theory of Mind (ToM): The capacity to attribute mental states (beliefs, intents) to others, used here to inform AI understanding of users. "Theory of Mind (ToM) and its role in predicting others' mental states"
- Top-k: Selecting the k highest-ranked items according to some relevance or scoring function. "we retrieve the top- papers"
- Win rate: The proportion of comparisons in which a system’s output is preferred over a baseline or ground truth. "We report the overall win rate against the ground truth"
Collections
Sign up for free to add this paper to one or more collections.