- The paper presents Idea2Story, a two-stage framework that separates offline knowledge graph construction from online research pattern generation to improve scientific discovery.
- It employs layered methodology extraction from over 13,000 peer-reviewed papers to build a canonicalized, compositional knowledge graph for structured retrieval.
- Experimental evaluation shows the system yields research patterns with superior novelty, specificity, and cross-domain compositionality compared to direct LLM approaches.
Pre-Computation-Driven Scientific Discovery with Idea2Story
Motivation and Context
The automation of scientific discovery using LLM-based agents has advanced rapidly, yet prevailing approaches perform literature review and methodological synthesis at runtime, resulting in inefficiencies and performance bottlenecks due to redundant information access, high computational cost, and context window limitations. The runtime-centric paradigm frequently forces agents to reprocess large volumes of unstructured literature, amplifying risks of brittle reasoning and hallucination. Addressing these deficiencies requires decoupling foundational knowledge acquisition from online research generation.
System Overview and Two-Stage Framework
Idea2Story is introduced as an autonomous scientific discovery framework that separates literature understanding into offline knowledge graph construction and online research generation. The system adopts a pre-computation-driven methodology that continually ingests accepted peer-reviewed papers and their review artifacts, extracts reusable methodological units, and organizes them into a structured, compositional knowledge graph. At runtime, research agents retrieve and compose high-quality research patterns from this graph, consistently grounding user research intents in empirically validated paradigms.
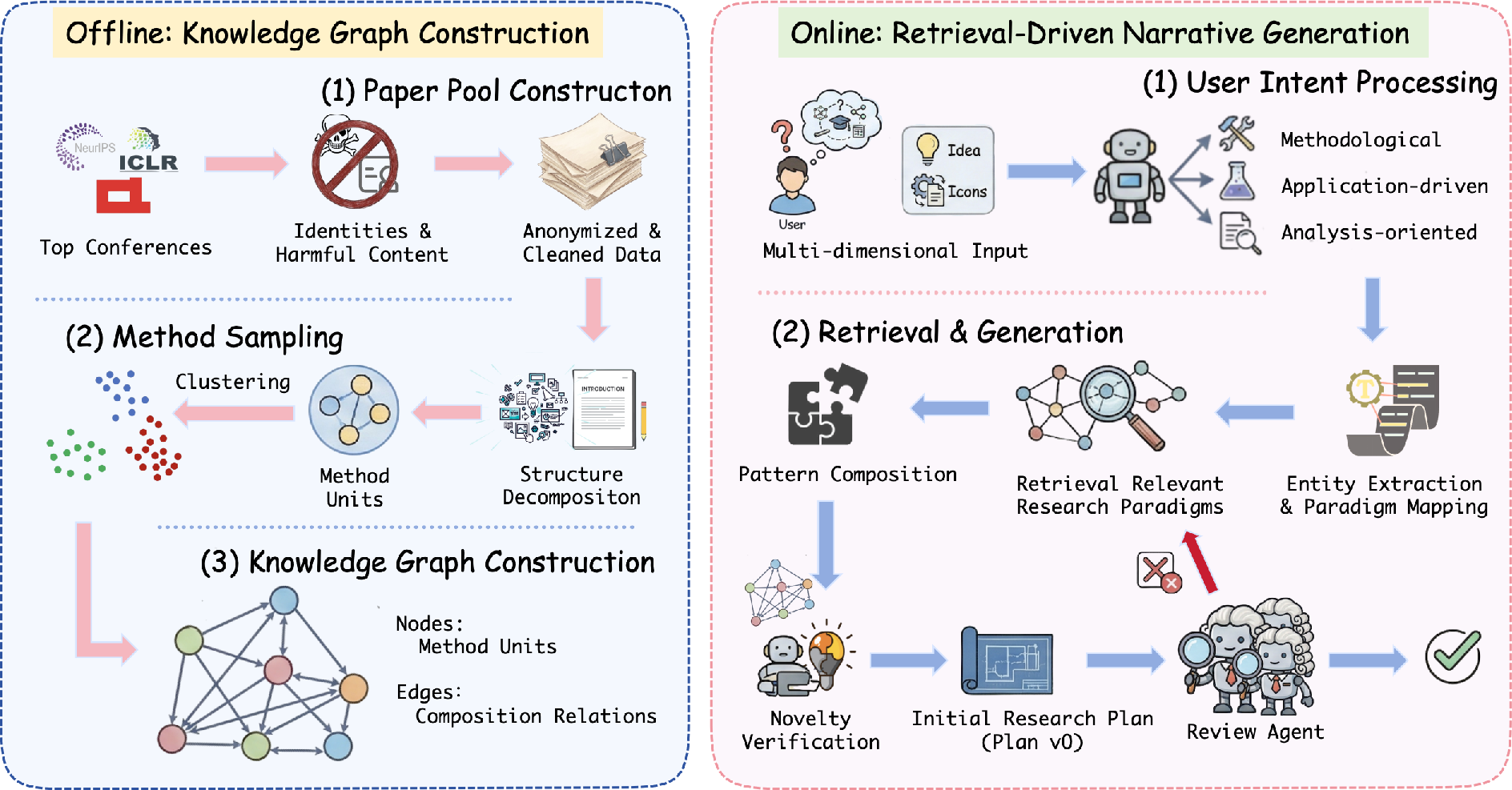
Figure 1: Overview of the two-stage framework in Idea2Story. The offline stage constructs a structured knowledge graph from extracted method units; the online stage leverages this structure to ground underspecified research intent.
This architecture systematically induces persistent methodological memory, substantially reducing both reliance on large context windows and repeated literature analysis at inference time.
Offline Knowledge Construction Pipeline
Data Curation and Preprocessing
Peer-reviewed papers and their reviews from NeurIPS and ICLR (over a three-year window) are selected, aggregating approximately 13,000 papers. Each entry is anonymized to remove identifying information and passed through safety filtering for toxicity.
Papers are decomposed into logically separated sections (introduction, method, experiments). Information is hierarchically extracted into layered representations capturing core research ideas, domain context, high-level story structure, and publication-specific packaging actions.
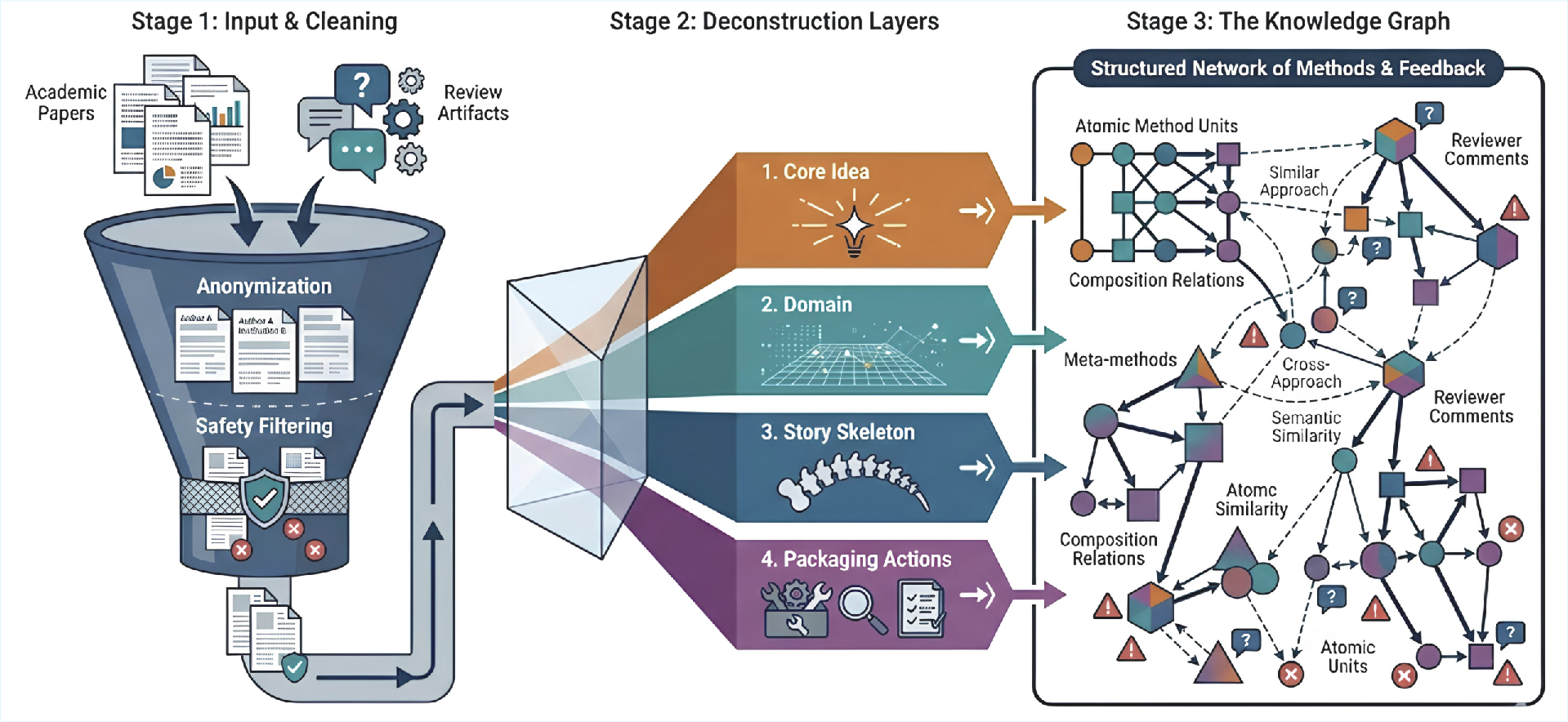
Figure 2: Offline knowledge graph construction in Idea2Story with layered decomposition, normalization into atomic method units, and incorporation of reviewer feedback to refine the graph.
Method units are abstracted as minimal, reusable blocks—distilled down to problem formulation and core solution approaches, intentionally omitting dataset and tuning specifics unless they introduce substantive methodological advances.
Graph Construction and Canonicalization
Extracted method units are canonicalized into meta-methods, clustered by semantic density (UMAP + DBSCAN), and connected in a directed knowledge graph, where nodes represent canonicalized methodological elements and edges encode empirically validated co-compositional relationships. Review data are integrated to refine relation strengths and validate abstraction accuracy.
This knowledge graph allows explicit modeling of both atomic methodology and higher-order empirical compatibility, supporting both retrieval and composition at levels beyond what is achievable with document-level similarity alone.
Online Research Pattern Retrieval and Generation
When presented with an ambiguous, natural-language research prompt, the agent performs structured search over the knowledge graph. Pattern scoring leverages multi-view retrieval: (1) idea-level semantic similarity, (2) domain-level thematic connection weighted by historical empirical effectiveness, and (3) content-level alignment with papers annotated for review quality. Aggregated signals are used to robustly rank and select research pattern candidates.
Candidate patterns are further refined through an explicit LLM-based review loop using an iterative generate-review-revise cycle, considering technical soundness, novelty, and alignment. Only refinement steps driving model-assessed improvement in novelty and clarity are retained, preventing goal drift and ungrounded revision cycles.
Knowledge Graph Structure and Analysis
Graph substructure analysis reveals hub-and-spoke patterns, where a small set of high-frequency domains serve as central connectors between diverse research areas and patterns. Many induced research patterns act as methodological bridges, generalizing across domains and enabling cross-domain methodological innovation.
Figure 3: Visualization of the knowledge graph substructure highlighting hub domains with high connectivity and pattern-level nodes bridging multiple research areas.
Graph analysis shows clear differentiation between instance-level papers (typically domain-bound) and pattern-level nodes (often cross-domain), enabling truly compositional retrieval unachievable via standard retrieval-augmented generation.
Experimental and Comparative Evaluation
Empirical studies demonstrate that method unit extraction yields structured entities capturing both base research problems and conceptual solution blueprints. In qualitative user-driven ideation tests, patterns generated by Idea2Story exhibit higher degrees of problem reinterpretation, compositionality, and methodological specificity over direct LLM generation baselines.
Notably, blind assessment by external evaluators (Gemini 3 Pro) reports that Idea2Story outputs are consistently rated superior in terms of novelty and specificity, whereas LLM-only baselines default to high-level formulations lacking concrete methodological grounding.
Implications and Future Directions
By relegating scientific knowledge synthesis to an offline phase and formalizing research patterning in a continuously updated knowledge graph, Idea2Story provides a scalable substrate for robust autonomous research planning. This approach mitigates the inherent brittleness and inefficiency of context window–limited runtime agents and offers explicit structures for empirical validation and compositional innovation.
Extending Idea2Story with automated experimental agents, connected in a closed empirical-theoretical loop, could move the field closer to fully autonomous, self-refining scientific discovery pipelines—where method, experiment, and manuscript generation are all grounded in validated, empirically derived research narratives.
Practically, such a paradigm has the potential to accelerate and democratize hypothesis exploration, facilitating broader engagement in scientific ideation and reducing the cost of credible research. Theoretically, it motivates systematic analysis of empirical compatibility and compositionality in methodological innovation, suggesting new targets for progress in open-endedness, continual learning, and agentic scientific intelligence.
Conclusion
Idea2Story operationalizes a shift from runtime-centric, online reasoning toward offline, structured knowledge curation and pattern retrieval, substantially improving efficiency and methodological fidelity in automated scientific discovery (2601.20833). Qualitative and comparative evidence shows superior research pattern induction relative to direct LLM methods, with increased novelty, grounding, and compositionality. The knowledge-graph-centered approach provides a scalable, reliable foundation for future advances in autonomous discovery agents and compositional AI research workflows.