- The paper demonstrates that optimal next-pixel prediction in vision requires a significantly higher token-to-parameter ratio and compute resource, needing up to 10-20 times more data than language models.
- It shows that image generation quality benefits from a steeper dataset growth than image classification, highlighting distinct scaling dependencies for different tasks.
- It reveals that higher image resolutions demand accelerated model size growth relative to data volume, indicating that larger models become more effective than simply increasing data.
Scaling the Next-Pixel Prediction Paradigm: An Analytical Perspective
Introduction to Next-Pixel Prediction
The paper "Rethinking generative image pretraining: How far are we from scaling up next-pixel prediction?" (2511.08704) provides a comprehensive analysis of the scaling properties of autoregressive next-pixel prediction in vision models. By training Transformer models on 32 × 32 images, the study investigates the optimal scaling strategies across three target metrics: next-pixel prediction loss, ImageNet classification accuracy, and Fréchet Distance for image generation quality.
This analysis is motivated by contrasting the scaling trends of visual modeling with those of well-established LLMs. Learning from raw pixels poses unique challenges due to their low semantic content and complex spatial dependencies. Despite these challenges, this research identifies scaling trends consistent with those found in natural language processing.
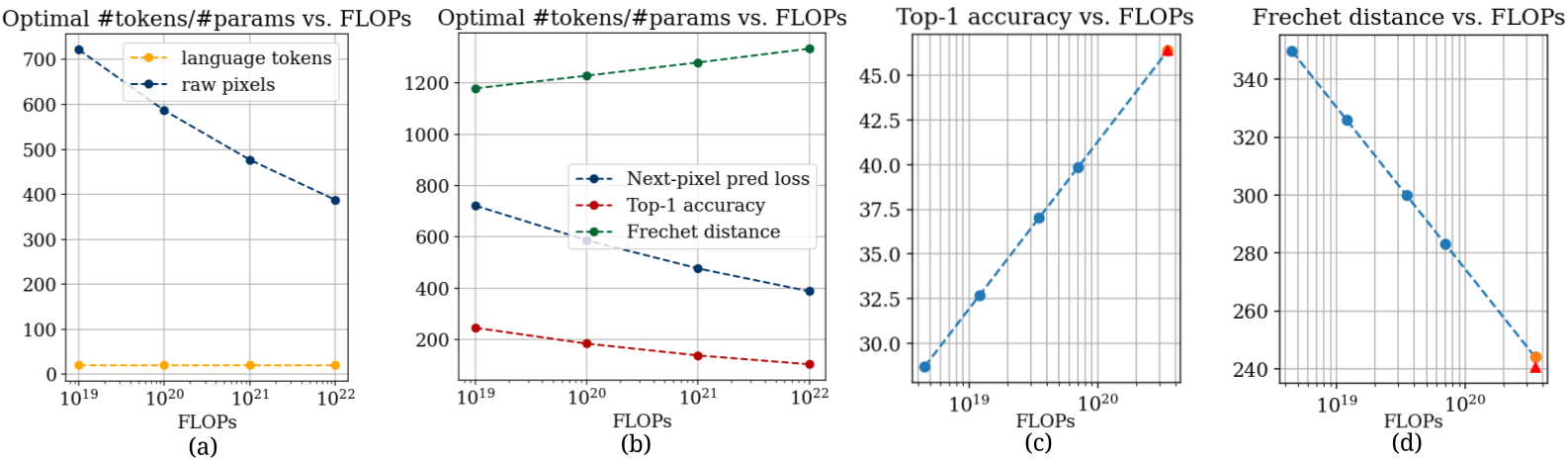
Figure 1: Key scaling properties of next-pixel prediction, showing a higher optimal token-to-parameter ratio for pixels compared to language tokens.
Optimal Scaling and Its Dependencies
The research identifies critical dependencies of optimal scaling strategies on specific tasks. Remarkably, image generation quality requires a larger dataset growth rate than image classification, underscoring the divergent resource allocations necessary for distinct tasks within computer vision.
The results depict that training on raw pixels requires a significantly higher optimal token-to-parameter ratio than language token learning—up to 10-20 times more data. This necessitates a higher compute resource allocation to achieve parity with LLMs, delineating a key bottleneck in visual model scalability.
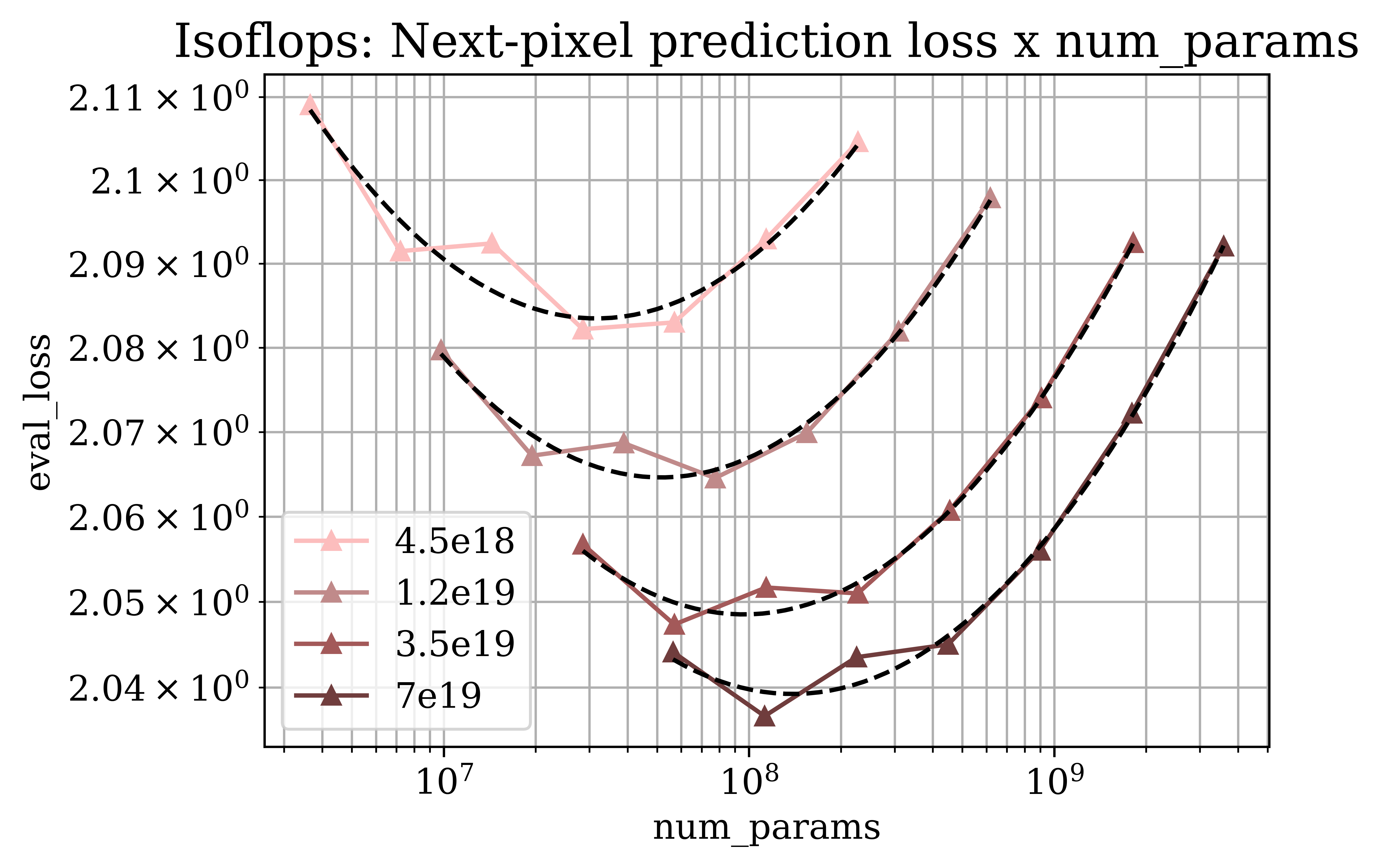
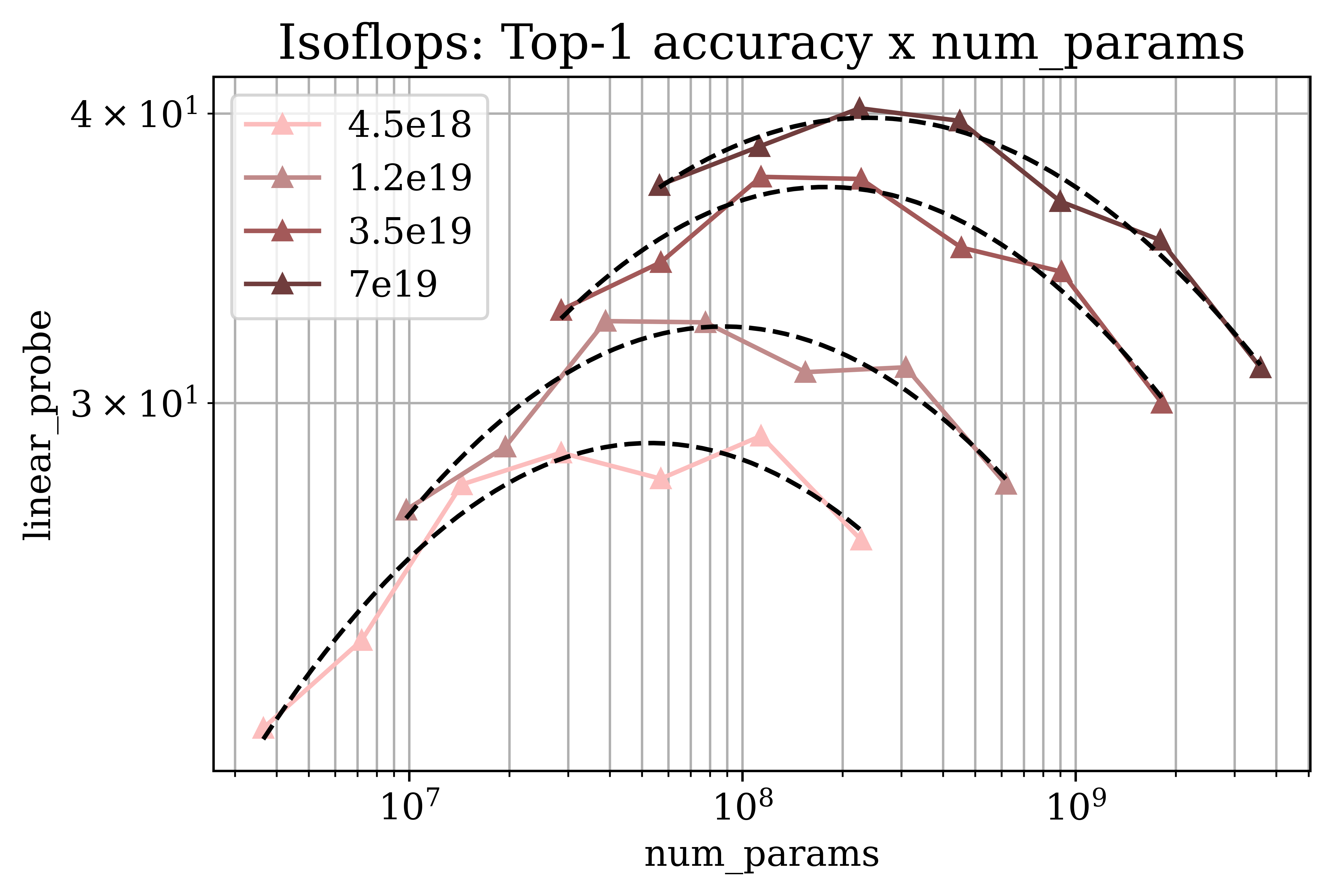
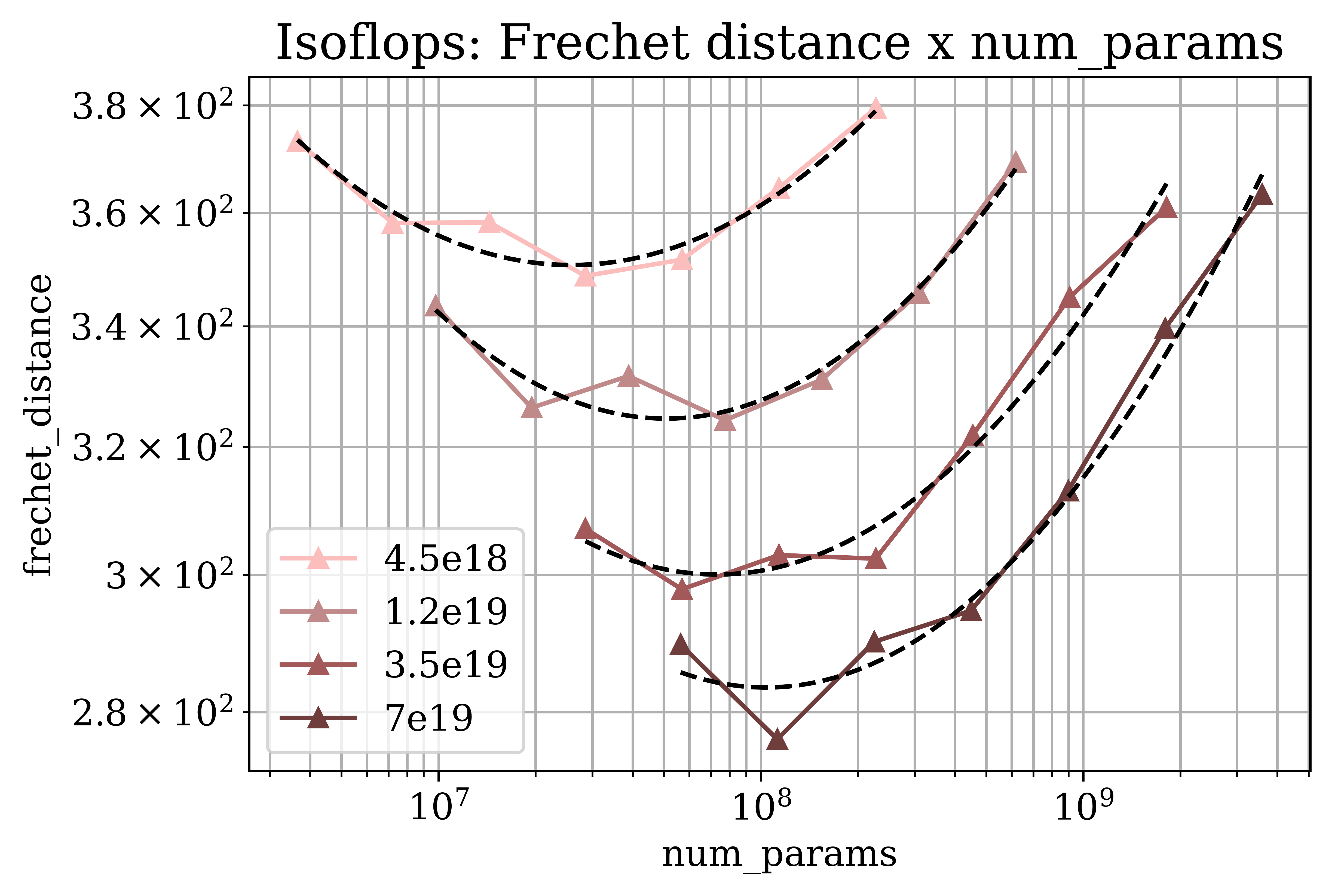
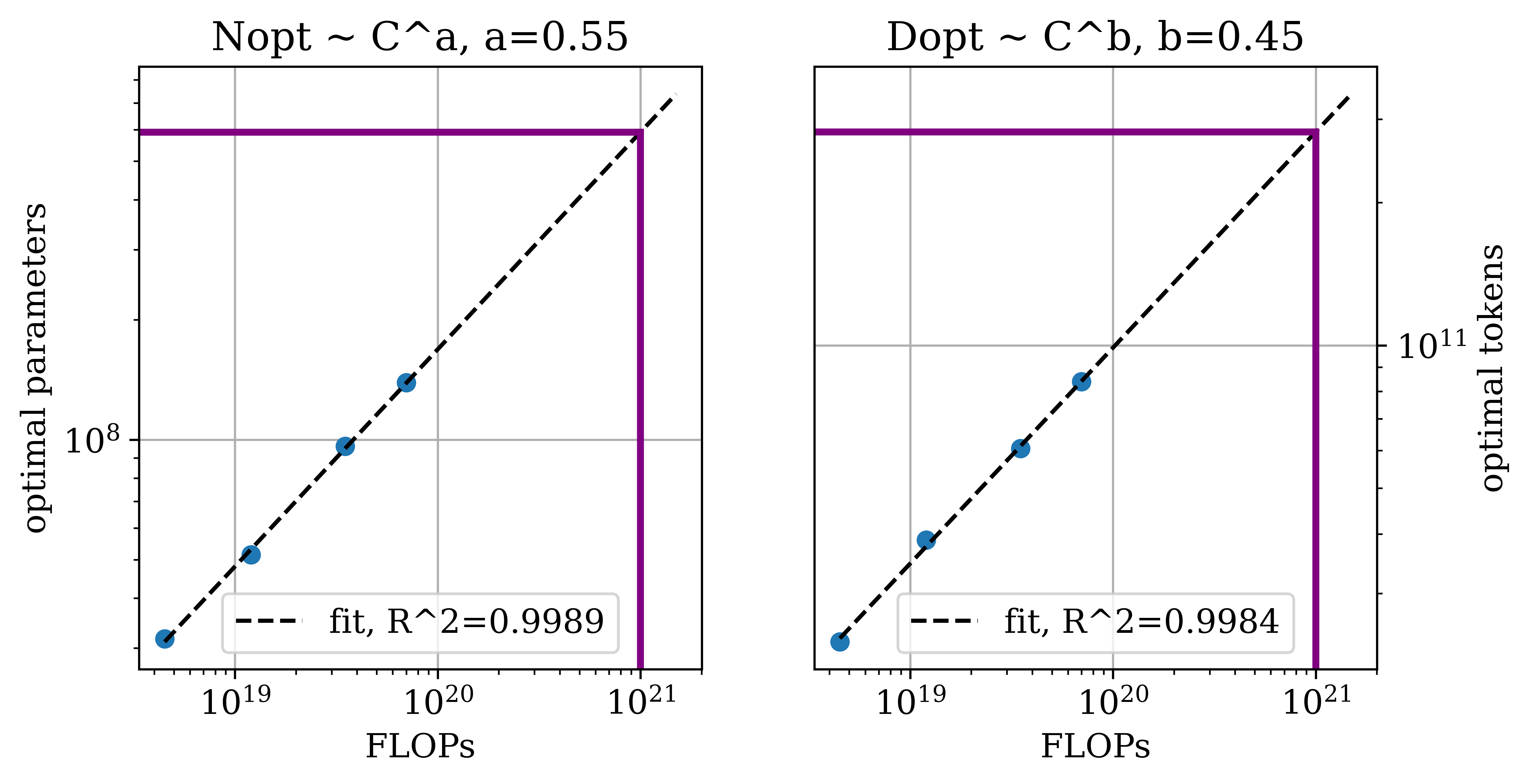
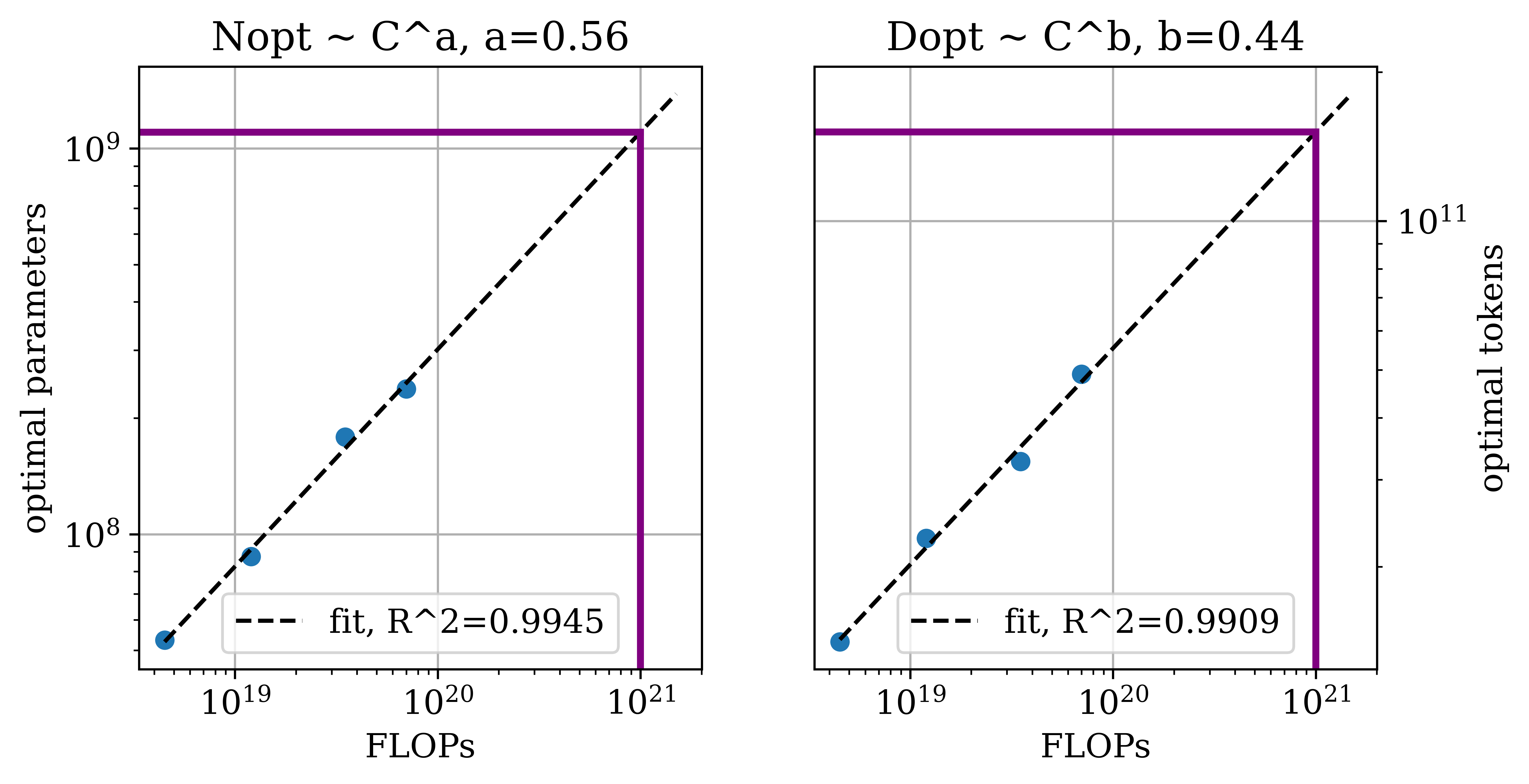
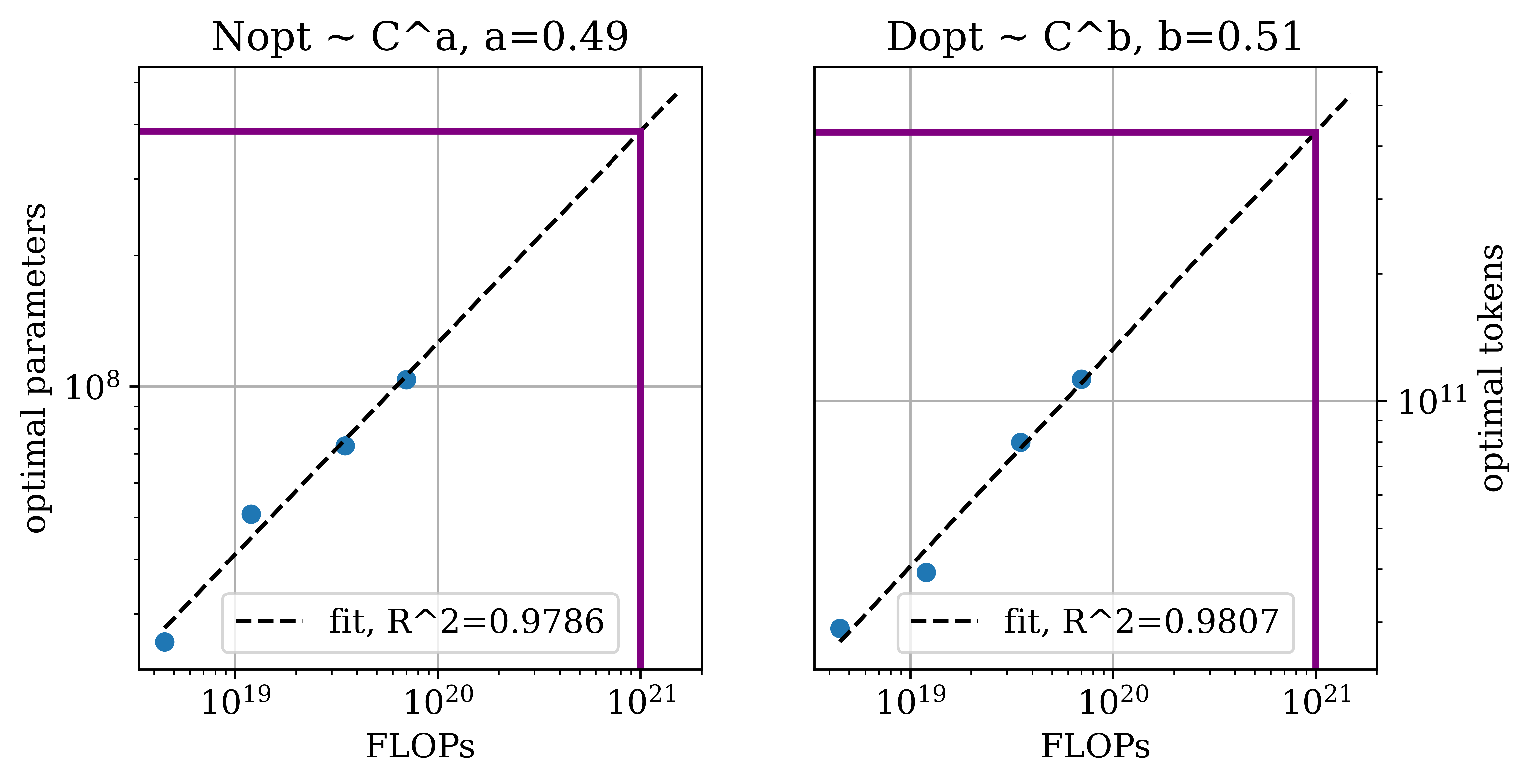
Figure 2: Predicted scaling properties of next-pixel prediction across key metrics and resolutions, emphasizing divergence in data and model scaling needs.
Effects of Image Resolution
The paper also explores how scaling strategies must adapt as image resolution increases. Detailed comparisons reveal that higher resolution demands an accelerated model size growth relative to data size. This shift indicates that, as image resolution increases, larger models become more effective than merely increasing data volume.
The complexity inherent to higher resolutions results in enriched data content per image, thereby modifying the balance between data and model scaling. This aligns with the intuition that high-resolution images encapsulate rich and intricate structures, necessitating more sophisticated model architectures.
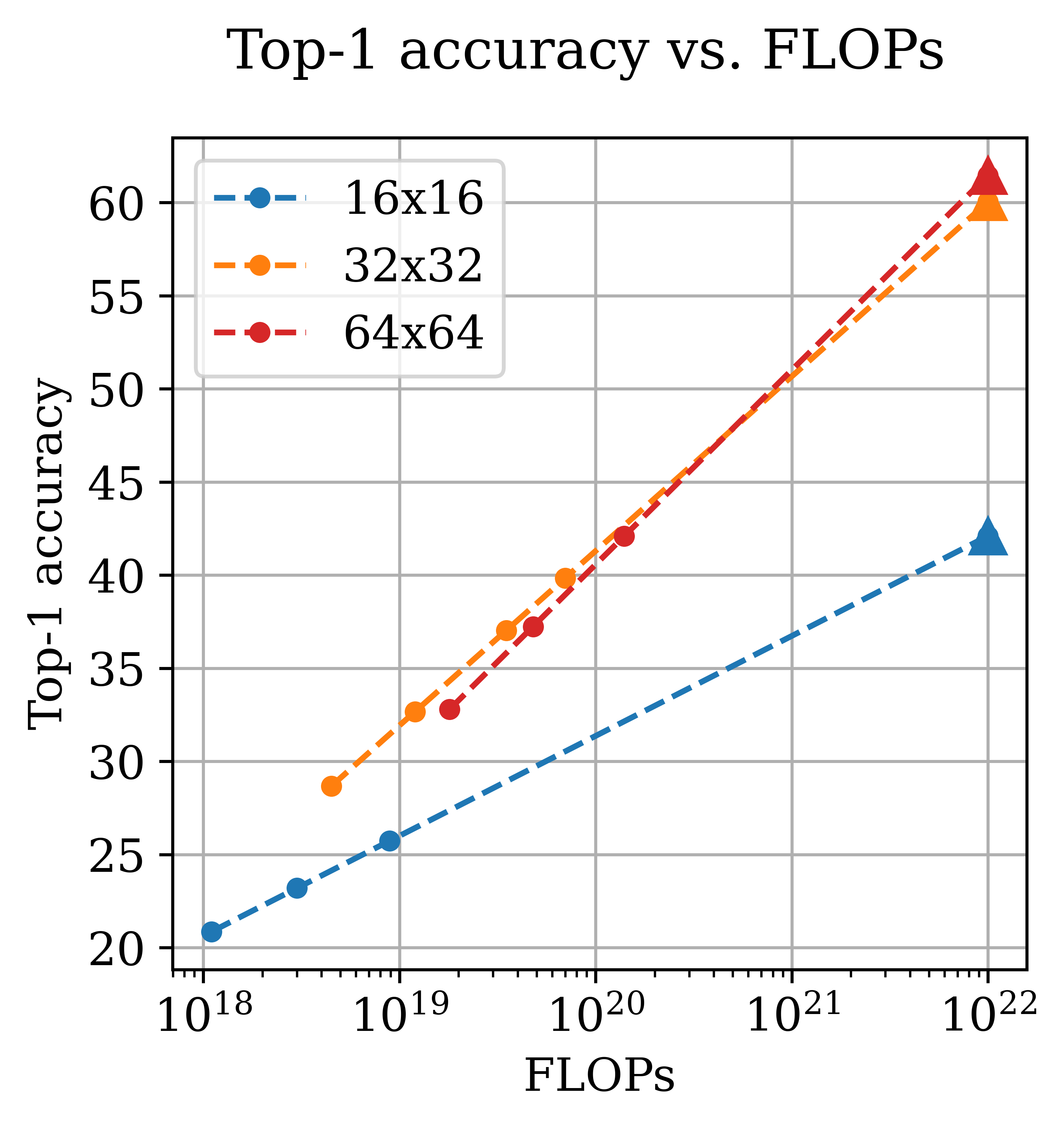
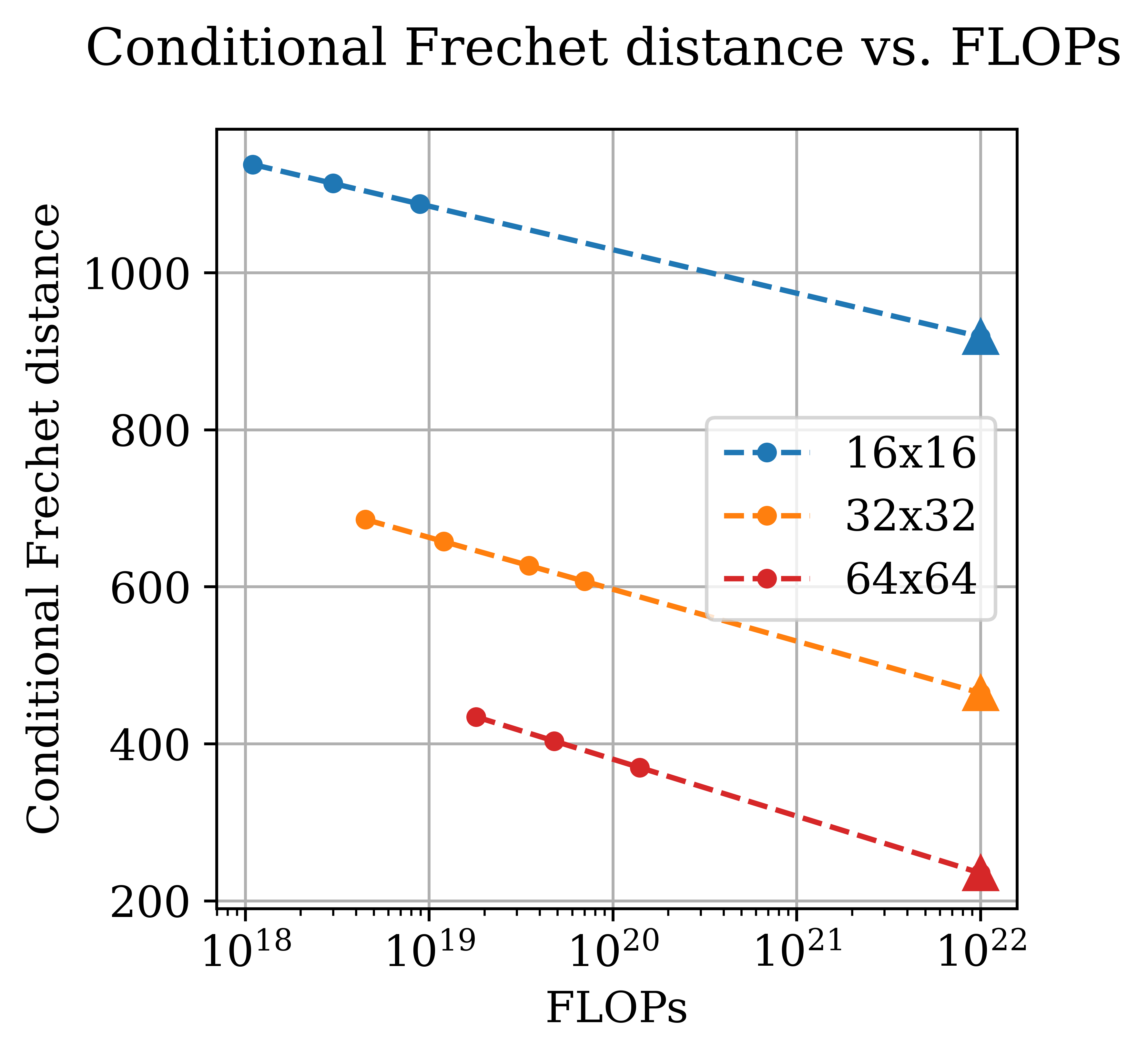
Figure 3: Changes in optimal model and data scaling predictions versus FLOPs across different resolutions, highlighting the shift towards larger models at higher resolutions.
Feasibility of Next-Pixel Modeling
The projection within the study intimates that, while the computational demands are currently prohibitive, next-pixel prediction could reach competitive performance metrics in ImageNet classification and image generation within forthcoming years. This is contingent on expected annual compute growth rates of 4-5 times, signaling a future readiness for scaling raw pixel-based models.
The study thereby offers a forward-looking stance on the feasibility of achieving advanced capabilities in vision models using end-to-end raw pixel learning, predicated on continued growth in available computational resources.
Conclusion
This paper provides critical insights into the computational intricacies of scaling next-pixel prediction models. It underscores the remarkably higher data requirements relative to LLMs and proposes task-dependent, resolution-sensitive scaling strategies as a solution. The broader implication is a pivotal shift, identifying compute as a bottleneck rather than data, framing pixel-based autoregressive modeling as a viable frontier in visual generative model research. Future work can extend this foundation by exploring efficiency improvements and integrating alternative training objectives to harmonize performance across diverse visual tasks.