- The paper presents a novel autoregressive model that uses continuous tokens and a lightweight flow matching head for efficient image generation.
- It unifies text and image token processing in a single sequence via a causal transformer, achieving state-of-the-art text-to-image synthesis.
- The model demonstrates strong performance on high-resolution benchmarks for image editing and semantic alignment while reducing computational overhead.
NextStep-1: Toward Autoregressive Image Generation with Continuous Tokens at Scale
Introduction
The development of NextStep-1 extends the capabilities of autoregressive (AR) models by utilizing continuous tokens for high-dimensional image generation. Traditional AR models, predominantly for text-to-image tasks, rely extensively on diffusion models or vector quantization (VQ), both of which present challenges in terms of computational efficiency and tokenization loss. NextStep-1 adopts a novel approach, employing a next-token prediction mechanism with a robust flow matching head strategy, allowing for efficient training on both discrete text and continuous image tokens. This approach has demonstrated state-of-the-art capabilities in text-to-image synthesis and image editing.

Figure 1: Overview of NextStep-1 in high-fidelity image generation, diverse image editing, and complex free-form manipulation.
Framework and Architecture
The core of NextStep-1's framework lies in its use of a causal transformer that processes both text and image tokens within a single sequence. This design enables seamless integration of multimodal inputs and generates images by predicting the flow from noise samples to target image patches during the training phase. At inference, this model iteratively refines noise to construct the final image output. The flow matching head—comprised primarily of a lightweight multilayer perceptron (MLP)—is tasked with continual flow prediction, ensuring high-fidelity image synthesis without the computational overhead typically associated with full diffusion models.
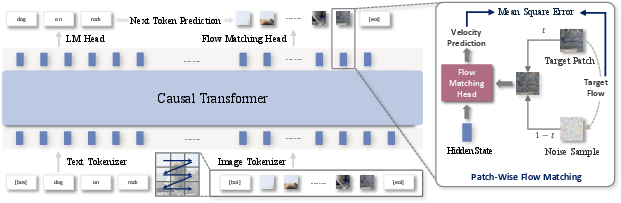
Figure 2: Overview of NextStep-1 Framework with its causal transformer processing tokenized text and image tokens.
Unified Multimodal Generation with Continuous Visual Tokens
NextStep-1's architecture unifies multimodal input into a cohesive sequence, facilitating robust text-to-image generation. Each element within this sequence is treated as either a discrete text token or a continuous image token. The flow matching head enables continuous tokens' prediction, leveraging a standard language modeling head for text processing. An overarching loss function balancing between text cross-entropy and flow matching losses governs the training dynamics, calibrated through specific hyperparameters.
Model Training and Data Processing
The model's training is structured into multiple phases, incorporating an extensive and diverse dataset comprising text-only, image-text pairs, and interleaved data to ensure versatility in generative capabilities. The pre-training follows a curriculum learning approach, gradually scaling image resolution and data complexity. Post-training aligns the model with human preferences using Supervised Fine-Tuning (SFT) and Direct Preference Optimization (DPO), enhancing the model's alignment with desired output characteristics.

Figure 3: Data processing of character-centric data.
NextStep-1 exhibits a competitive edge in high-resolution text-to-image tasks, outperforming many state-of-the-art AR models and aligning closely with the best diffusion models. It achieves high scores across several benchmarks designed to evaluate visual-textual alignment, semantic understanding, and world knowledge integration, such as GenAI-Bench and WISE. Furthermore, its image editing capabilities are validated on benchmarks like GEdit-Bench and ImgEdit-Bench, demonstrating robust instruction-following and editing aptitudes.
Discussion
Image Generation Mechanics
NextStep-1's design differentiates itself by directly modeling image tokens autoregressively, unlike previous AR models dependent on diffusion for full-image generation. The choice of employing a compact flow matching head suggests that much of the image generation's conceptual complexity is handled by the transformer backbone, reinforcing the notion that the AR paradigm offers a scalable solution for complex image generation tasks.

Figure 4: Images generated under different flow-matching heads.
Image Tokenizer's Role
A significant aspect of NextStep-1's success is linked to its image tokenizer, which maintains stability and mitigates artifacts even under strong guidance scales. The integration of channel-wise normalization enhances latent stability, critical for maintaining image fidelity across sequential token generations. The tokenizer’s robustness under varying noise intensities further denotes its central role in image quality consistency and enhances overall performance capabilities.

Figure 5: Impact of Noise Perturbation on Image Tokenizer Performance, illustrating performance metrics versus noise intensity.
Conclusion
NextStep-1 presents a compelling advancement in the domain of autoregressive image models by integrating continuous tokens at scale, using innovative architectural designs and an efficient training regime. Its ability to achieve high-quality, high-resolution image synthesis with reduced computational overhead represents a significant step forward for scalable multimodal model development. While challenges like inference latency and high-resolution training remain, NextStep-1 lays the groundwork for further exploration and refinement in AR-based image generation technologies.