What did Elon change? A comprehensive analysis of Grokipedia
Abstract: Elon Musk released Grokipedia on 27 October 2025 to provide an alternative to Wikipedia, the crowdsourced online encyclopedia. In this paper, we provide the first comprehensive analysis of Grokipedia and compare it to a dump of Wikipedia, with a focus on article similarity and citation practices. Although Grokipedia articles are much longer than their corresponding English Wikipedia articles, we find that much of Grokipedia's content (including both articles with and without Creative Commons licenses) is highly derivative of Wikipedia. Nevertheless, citation practices between the sites differ greatly, with Grokipedia citing many more sources deemed "generally unreliable" or "blacklisted" by the English Wikipedia community and low quality by external scholars, including dozens of citations to sites like Stormfront and Infowars. We then analyze article subsets: one about elected officials, one about controversial topics, and one random subset for which we derive article quality and topic. We find that the elected official and controversial article subsets showed less similarity between their Wikipedia version and Grokipedia version than other pages. The random subset illustrates that Grokipedia focused rewriting the highest quality articles on Wikipedia, with a bias towards biographies, politics, society, and history. Finally, we publicly release our nearly-full scrape of Grokipedia, as well as embeddings of the entire Grokipedia corpus.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper looks at Grokipedia, an online encyclopedia launched by Elon Musk as an AI-powered alternative to Wikipedia. The authors ask a simple question: what, exactly, did Grokipedia change compared to Wikipedia? They study how similar the articles are, what kinds of sources they cite, and how Grokipedia handles sensitive topics like politics and controversial issues.
Key Objectives
The paper explores three main ideas in plain terms:
- How closely do Grokipedia articles match English Wikipedia articles on the same topics?
- What kinds of sources does Grokipedia cite, and are they trustworthy?
- Are certain types of articles (like those about politicians or controversial topics) more different in Grokipedia than in Wikipedia?
Methods and Approach
Think of this as a big compare-and-contrast project between two very large libraries.
- Building the dataset: The researchers collected almost all Grokipedia articles (over 883,000) and matched each one to the same-titled article from English Wikipedia. They used a public dump of Wikipedia from the same week to make fair comparisons.
- Measuring similarity with “embeddings”: They broke each article into small chunks (like paragraphs) and turned each chunk into a “meaning fingerprint” using an AI tool called EmbeddingGemma. This turns text into numbers that capture meaning. Then they measured how close the fingerprints are using cosine similarity. If two chunks are very similar, their “arrows” point in almost the same direction; if they’re different, the arrows point in different directions.
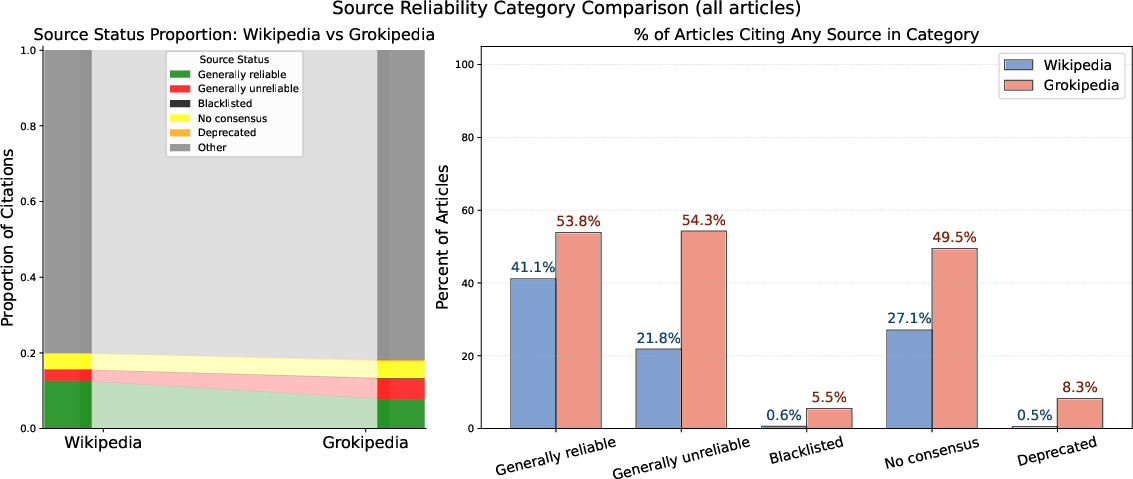
- Checking sources and reliability: The team looked at what websites each article cites. They used:
- Wikipedia’s own “Perennial Sources” list, which groups websites as generally reliable, generally unreliable, blacklisted, etc.
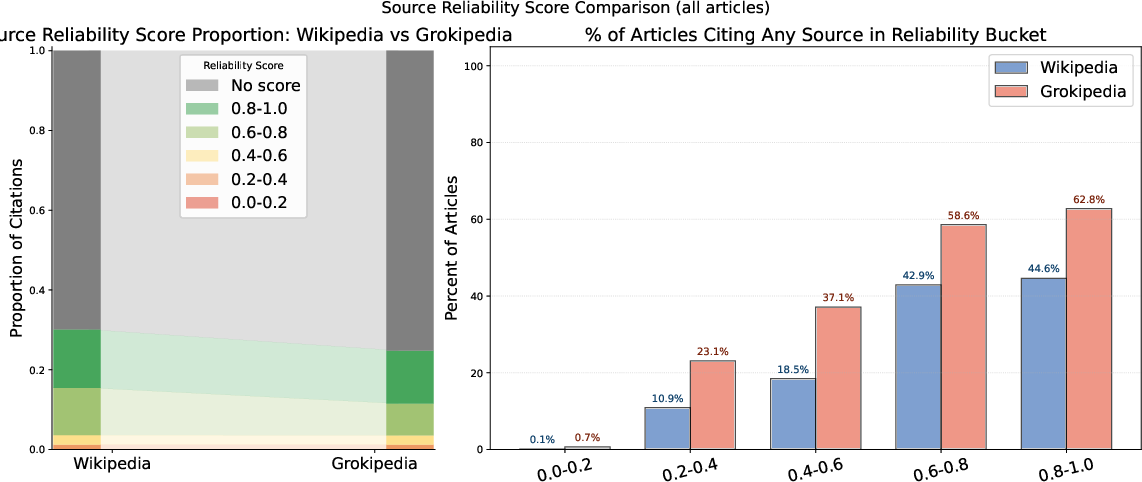
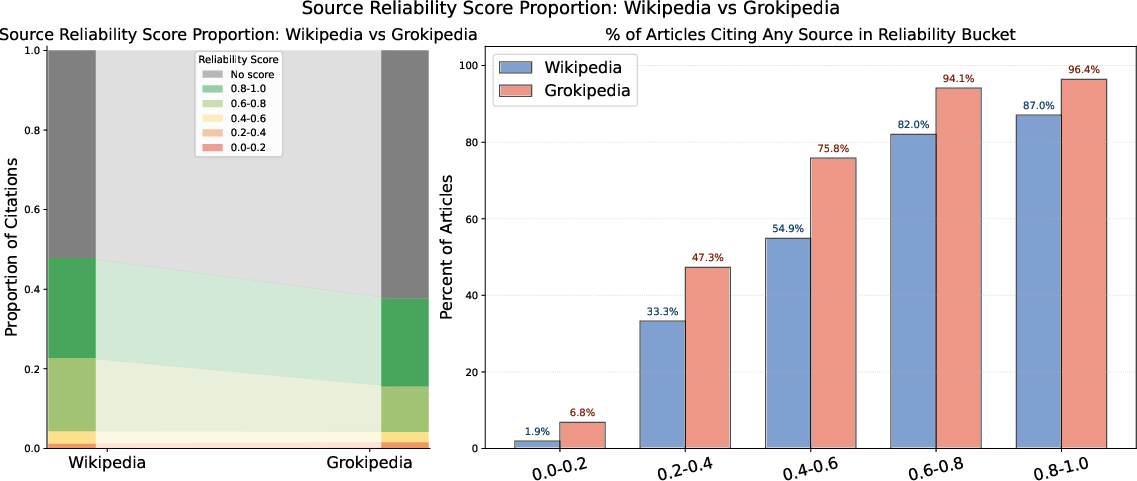
- A separate scorecard from researchers (Lin et al.) that rates news domains from 0.0 (very low credibility) to 1.0 (very high credibility).
- Special subsets: They zoomed in on three groups:
- Articles about elected officials in the US and UK.
- Articles Wikipedia labels as controversial.
- A random sample of 30,000 articles to study topic types and quality levels (like “Featured Articles” vs. “Stubs”).
- Licenses matter: About 56% of Grokipedia articles say they are adapted from Wikipedia under a Creative Commons (CC) license, which is a public permission system that lets you reuse content if you give credit. The rest do not show this license. The paper often compares these two groups separately.
Main Findings
- Grokipedia is longer and wordier: Almost all Grokipedia articles are longer than the matching Wikipedia ones, with more sections and more citations.
- Many articles are highly similar to Wikipedia:
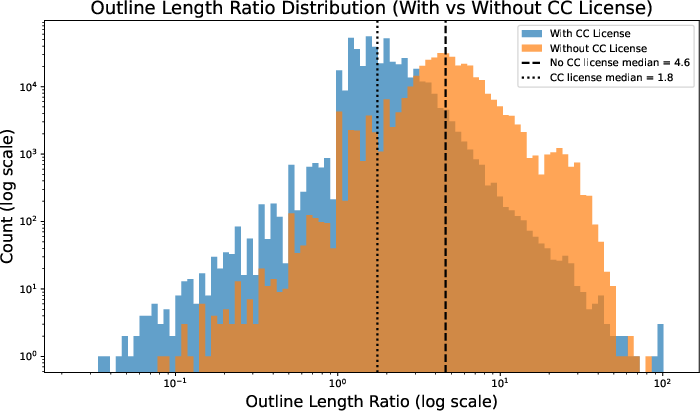
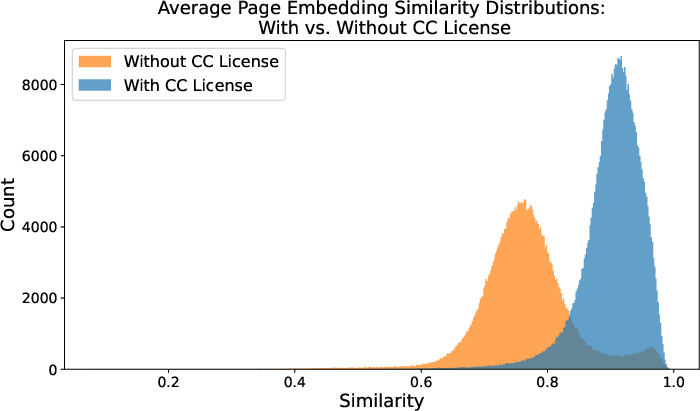
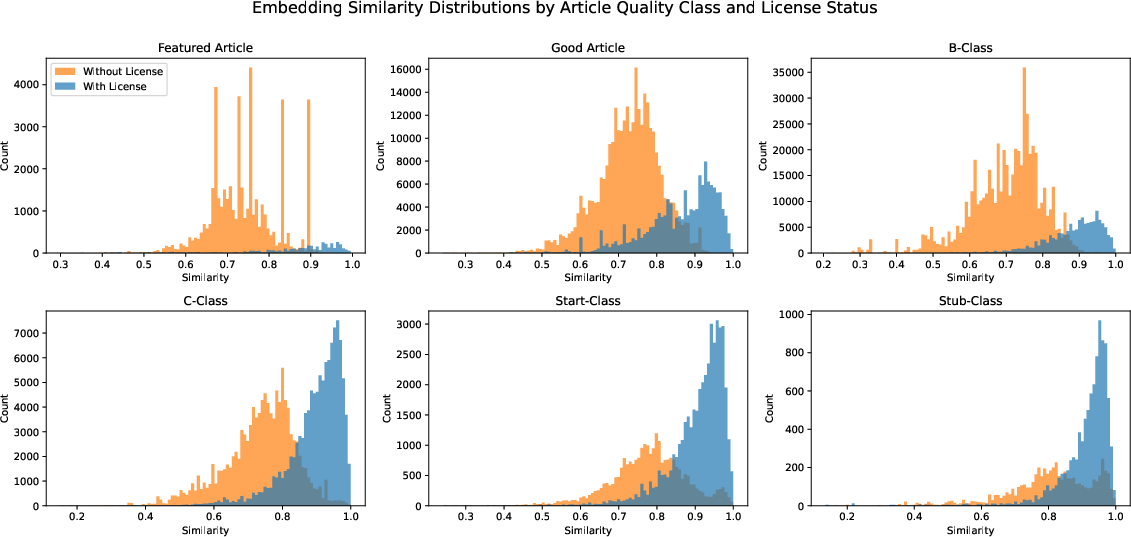
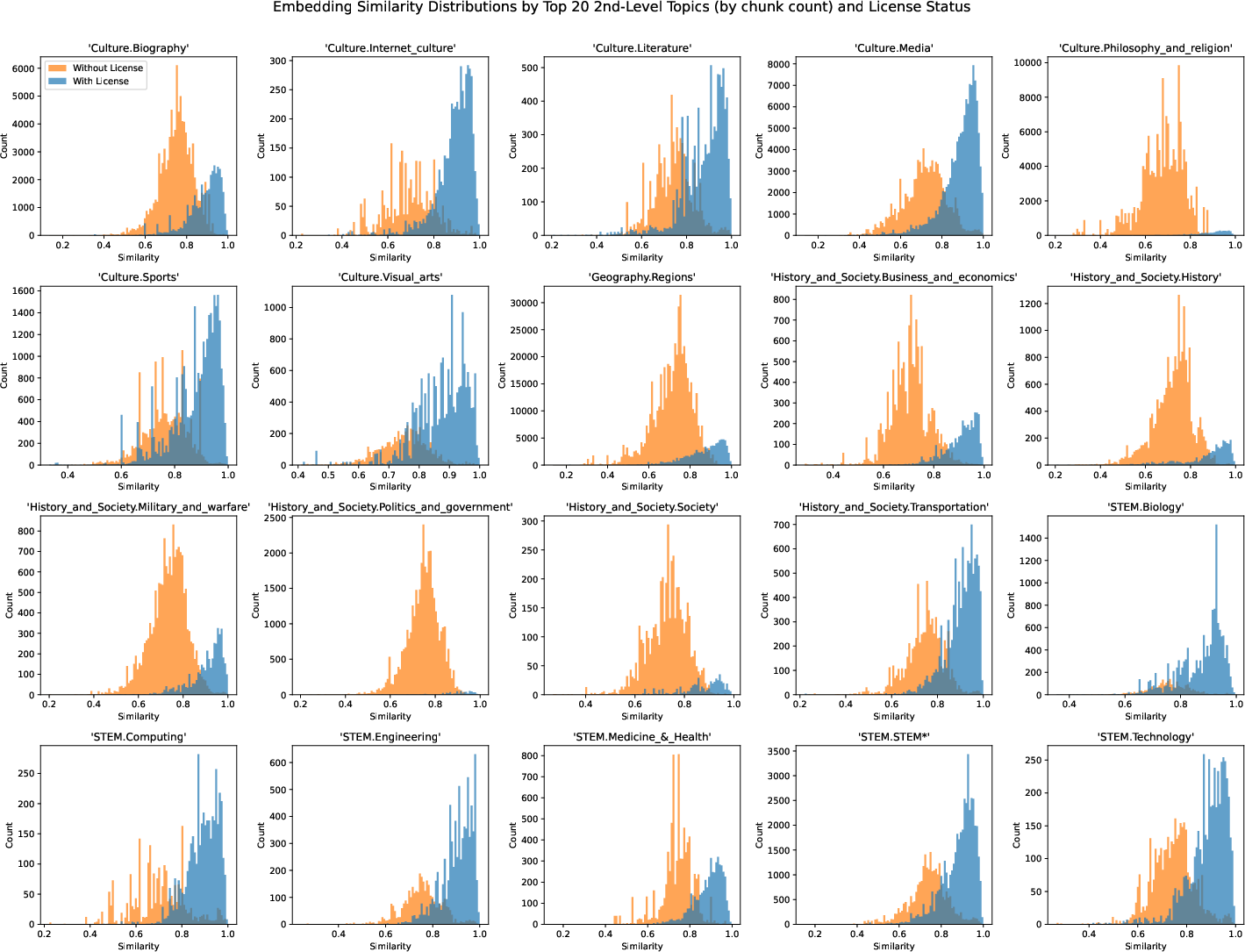
- CC-licensed Grokipedia articles are very close to Wikipedia versions on the same topic, with about 90% average similarity.
- Non-CC articles are less similar, averaging about 77%. Some even copy parts exactly without showing a CC license.
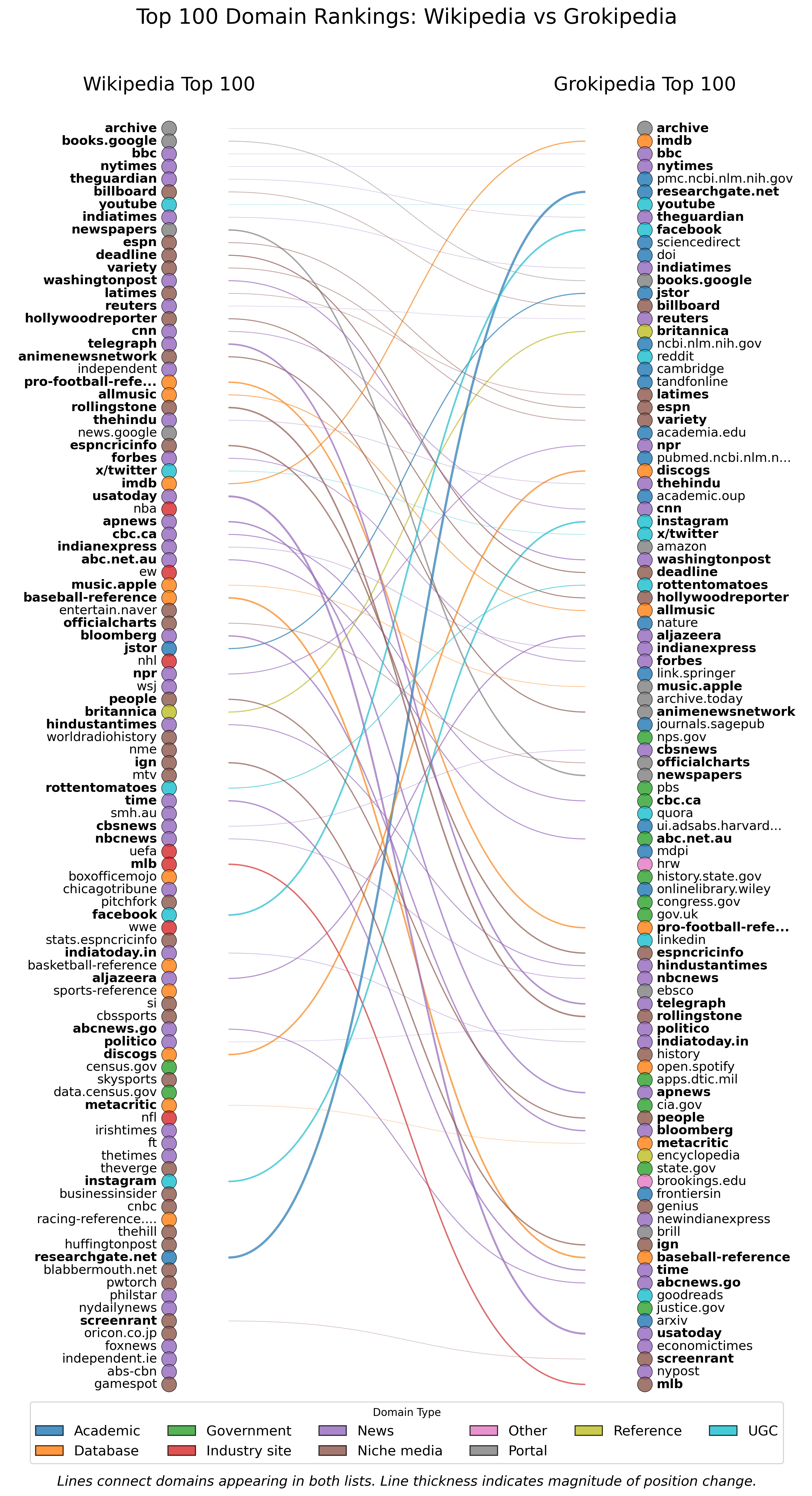
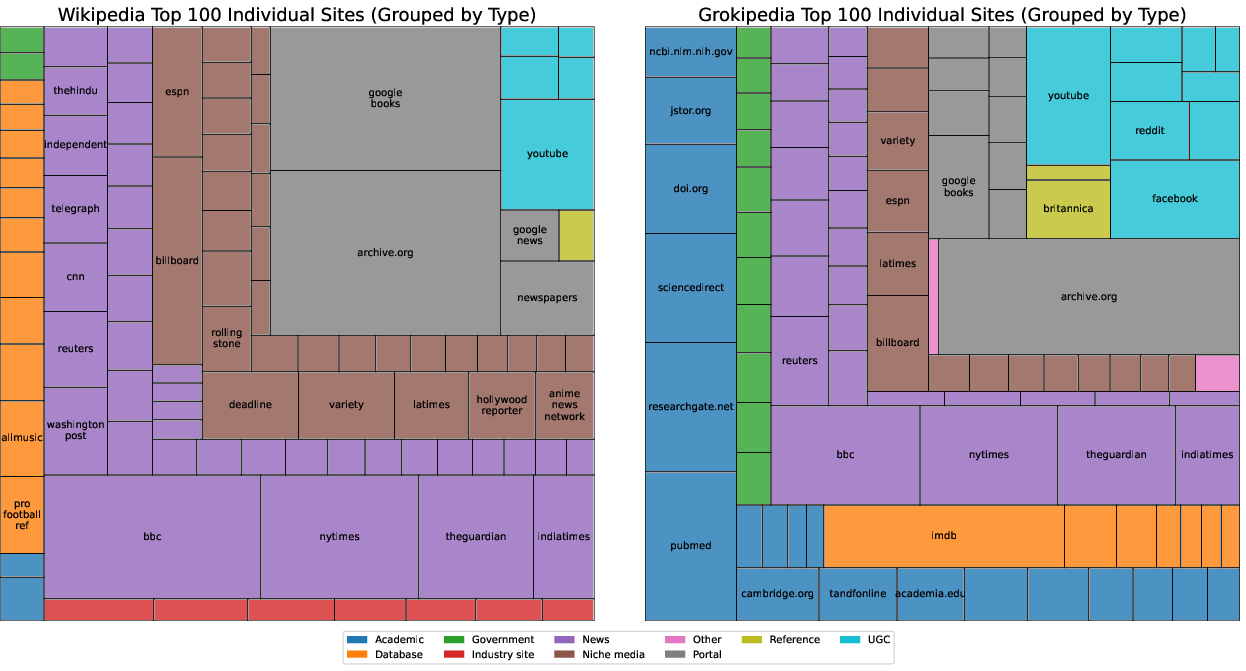
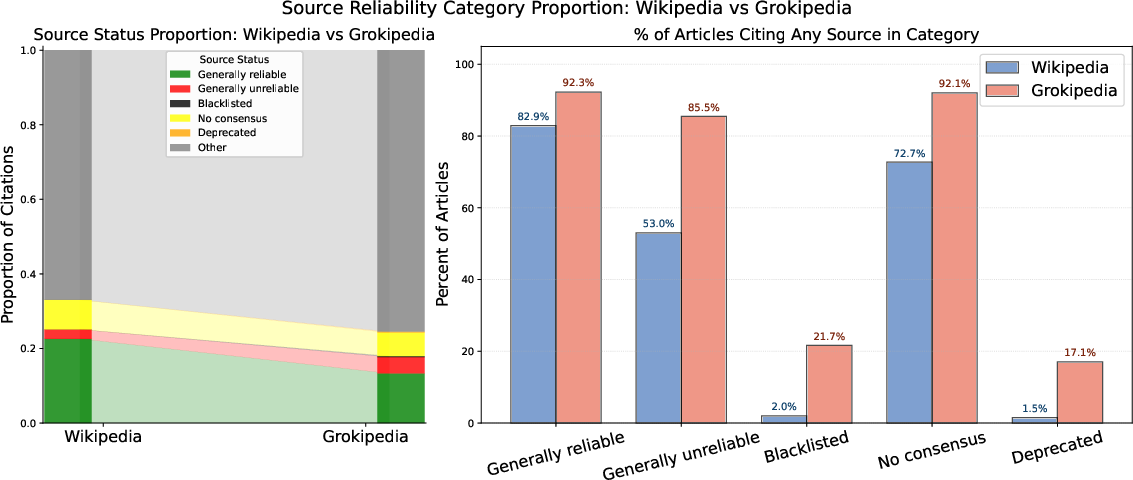
- Grokipedia cites more sources but of lower quality:
- Grokipedia includes roughly twice as many citations per article.
- It relies more on academic papers, government sites, and user-generated content (like YouTube, Reddit, X/Twitter) than Wikipedia does.
- It cites fewer mainstream news outlets than Wikipedia.
- It includes far more citations to sites that Wikipedia editors consider “generally unreliable” or even “blacklisted.” Examples include Stormfront (a Nazi website) and InfoWars (a conspiracy website), which appear dozens of times on Grokipedia and not at all on English Wikipedia.
- Special cases:
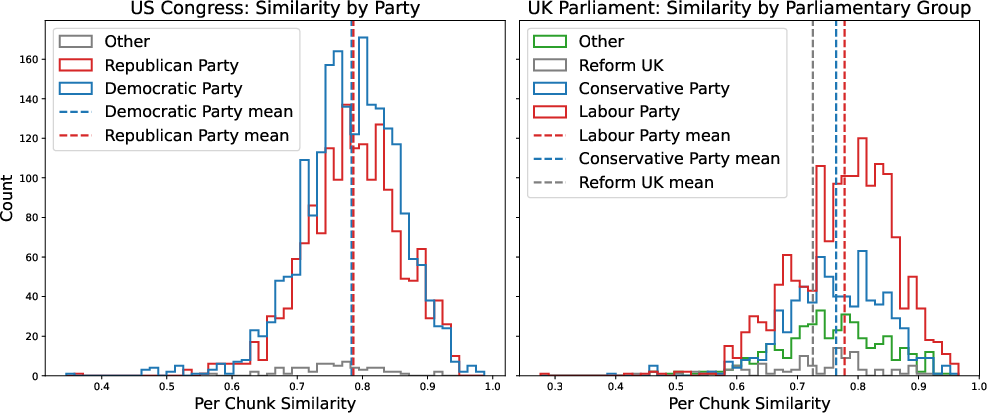
- Politicians: Articles about US and UK elected officials are less similar to Wikipedia and tend to feature more controversial claims or criticisms.
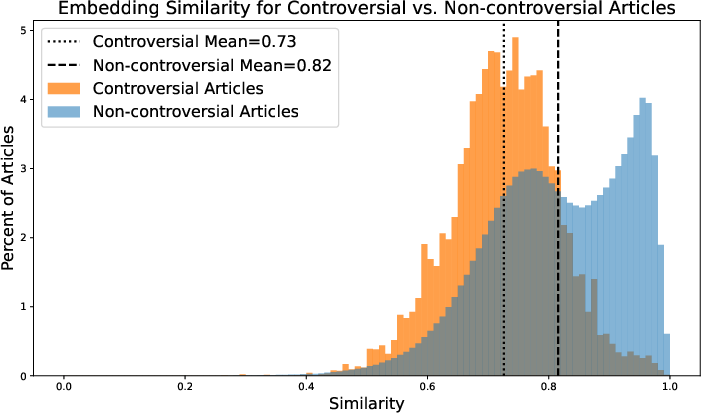
- Controversial topics: These Grokipedia articles are much less similar to Wikipedia and much more likely to include unreliable and blacklisted sources. Most of these do not carry the CC license.
- Random sample trends: Grokipedia seems to rewrite many of Wikipedia’s highest-quality articles (like Featured and Good Articles) more aggressively, especially in topics like biographies, politics, society, history, military, and government — areas where small changes in wording can influence how readers feel.
- Curious citation behavior:
- Grokipedia sometimes cites conversations with the Grok AI chatbot itself, and cites X/Twitter accounts like @grok and @elonmusk.
- It rarely cites Wikimedia sites (like Wikipedia itself) even when it clearly borrows content.
- Open data: The authors share their Grokipedia scrape and AI “embeddings” publicly so other researchers can study them.
Why It Matters
- Accuracy and trust: Encyclopedias should be careful about their sources. Grokipedia’s tendency to include more low-credibility and blacklisted sites raises concerns about reliability and potential misinformation.
- Bias and framing: Differences are strongest in political and controversial topics. Grokipedia often emphasizes controversy and shifts the tone, which could push readers toward a certain viewpoint rather than a neutral summary.
- Derivative yet different: Grokipedia is both a heavy reuse of Wikipedia (especially in CC-licensed articles) and also a place where content and citations diverge more on sensitive subjects. The authors conclude it’s partly a “synthetic derivative” and partly an “ideological project.”
Implications and Impact
- For readers: Be cautious when using Grokipedia, especially on political or controversial topics. Check sources and compare with Wikipedia or other trusted references.
- For researchers and educators: The released datasets make it possible to study how AI-written encyclopedias differ in style, framing, and sourcing — and how those differences might shape public understanding.
- For platforms: This study highlights the importance of clear sourcing rules and transparent licensing. If AI tools build encyclopedias, they need strong guardrails to avoid amplifying unreliable information.
In short, Grokipedia often mirrors Wikipedia, but where it diverges, it tends to add more words, more citations, and more low-quality sources — especially on sensitive topics — which can affect how people see the world.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper’s analysis. Each point specifies work future researchers could undertake.
- Corpus mapping and matching
- The join relies on exact title matching; unresolved coverage for redirects, disambiguation pages, capitalization variants, and titles that differ slightly. Build a robust crosswalk with redirect resolution and fuzzy matching to quantify unmatched but corresponding articles.
- The geographic and popularity selection of Grokipedia’s 885k entries is inferred from pageviews but not causally demonstrated. Reverse-engineer the selection criteria (e.g., thresholds, topic filters) and quantify geographic/subject bias introduced by the launch subset.
- Licensing and compliance
- License status is detected by a footer string, which risks false negatives/positives. Audit licensing programmatically (e.g., via page metadata or API) and manually sample to estimate error rates.
- Verbatim or near-verbatim text appears in non-CC-licensed pages; the extent and legal compliance (attribution, share-alike) remain unverified. Quantify identical-text prevalence across the corpus and assess compliance with CC BY-SA terms.
- The public “Grok edit log” present on CC-licensed pages was not scraped or analyzed. Capture and study these logs to reconstruct the transformation pipeline (what edits, by whom/what, when) and relate them to similarity and sourcing changes.
- Similarity measurement and content change characterization
- Embedding-based cosine similarity may miss subtle framing shifts, stance changes, and rhetorical choices. Develop claim-level and discourse-level measures (e.g., stance detection, subjectivity, hedging, voice shifts, loaded language) and compare results to embeddings.
- The bimodal distribution for non-CC-licensed article similarity is unexplained. Test hypotheses by controlling for article length, topic, quality class, and structure; conduct mixture modeling to identify latent subgroups and their drivers.
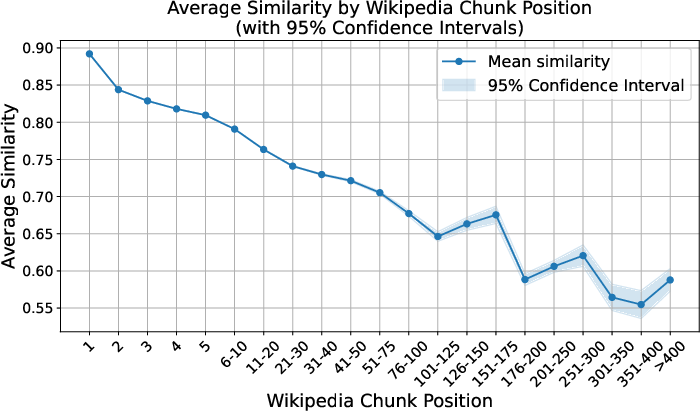
- Chunk-position effects are described but not causally probed. Align sections semantically (lead, infobox-like summaries, body sections) to evaluate whether similarity decay is structural or topical.
- Citation quality, use, and impact
- Domain-level quality scores (Perennial Sources, Lin et al.) cover only a minority of citations. Expand coverage by integrating multiple rating providers (e.g., NewsGuard, Ad Fontes, MBFC), build a unified reliability ontology, and assign confidence-weighted scores.
- The role of low-quality sources within articles is unknown (supporting primary claims vs peripheral anecdotes). Perform claim-to-citation linkage and classify each citation’s evidentiary function (support, background, refutation, primary-source reporting).
- Deduplication and redundancy of citations are not analyzed. Quantify unique sources per article, citation reuse, and the marginal informational value of added references relative to Wikipedia.
- X/Twitter and Grok-conversation citations are counted but not evaluated for reliability or influence. Measure prevalence, typologies (official accounts vs anonymous users), and the proportion of claims whose primary support is AI-generated or user-generated content.
- No validation of citation correctness (e.g., does the cited source substantiate the exact claim?). Build an automated pipeline and human-evaluation protocol for claim verifiability and precision of citation support.
- The taxonomy of “domain types” (news, academic, government, UGC) is used but its construction and reproducibility are unspecified. Publish the classification method, inter-rater reliability, and error analysis; test sensitivity of findings to taxonomy choices.
- Ideology, controversy, and political bias
- Evidence of ideological framing is anecdotal for controversial topics and political figures. Systematically measure slant using established political-leaning indices, stance/bias classifiers, and human annotation across a representative sample.
- Party-specific or country-specific differences (e.g., UK parties) are shown but not tested for statistical significance or confounds (topic mix, article quality, length). Run multivariate models to isolate party effects.
- The controversial-article subset is inherited from Wikipedia’s category, which may reflect Wikipedia’s own norms. Construct an independent controversy index (e.g., edit wars, news salience, social media polarization) and re-run analyses.
- Article quality and topic coverage
- WMF quality predictions are applied only to Wikipedia; there is no quality model for Grokipedia content. Train or adapt an article quality model for Grokipedia to compare intrinsic quality across platforms.
- The 30k random subsample is small relative to the corpus and may be topic-biased. Increase sample size, stratify by topic and license, and report confidence intervals and robustness checks.
- The finding that non-CC pages concentrate on high-quality Wikipedia articles lacks causal explanation. Investigate editorial prompts or prioritization criteria (e.g., biographies, politics, society, history) using internal logs or external signals.
- Temporal dynamics and versioning
- The analysis captures a single scrape window at launch. Establish longitudinal tracking to measure drift in similarity, sourcing, updates, and policy changes over time.
- Recency/staleness of content and citations (update lag vs Wikipedia) is not measured. Compare timestamped facts, citation publication dates, and responsiveness to breaking changes.
- Structure, readability, and error analysis
- Grokipedia’s added length is not evaluated for readability, coherence, or factual density. Assess with readability metrics, hallucination detection, and human judgments of informativeness vs verbosity.
- Typos and factual errors (e.g., “Commissioned on 1996”) are noted anecdotally. Conduct systematic error-mining (typo detection, contradiction checks, entity/date consistency) and compare error rates to Wikipedia.
- Sectioning and outline expansions are measured in length but not functionally analyzed. Map section types introduced by Grokipedia (e.g., “Controversies” sections, tables) and their effect on framing and sourcing.
- Knowledge provenance and synthesis
- The proportion of content that constitutes original synthesis vs aggregation from sources is unknown. Classify claims by origin and test alignment with “No Original Research” norms.
- “LLM auto-citogenesis” is flagged but not quantified. Develop detectors for AI-generated citations, measure feedback loops, and propose safeguards to prevent self-referential knowledge amplification.
- Internal linking and ecosystem integration
- Wikimedia domains are rarely cited despite high textual similarity. Investigate the internal linking policy, cross-article references, and whether Grokipedia systematically avoids citing Wikipedia even when derivative.
- Image, media, and data-table provenance and licensing (infobox data, figures) are not analyzed. Audit non-text assets for licensing, accuracy, and source attribution.
- Method validation and robustness
- EmbeddingGemma is used as the sole semantic comparator; model bias and sensitivity are untested. Replicate with multiple embedding models and with alignment-aware methods; include human evaluation for calibration.
- Results may be sensitive to chunking choices (size, overlap, weighting). Perform ablations varying chunk parameters and aggregation strategies (e.g., section-weighted vs uniform).
- Statistical uncertainty (confidence intervals, effect sizes, corrections for multiple comparisons) is largely absent. Add rigorous inferential statistics and power analyses to support key claims.
- User impact and governance
- Reader outcomes (trust, comprehension, misinformation uptake) are unexplored. Run user studies to assess how Grokipedia’s sourcing and framing affect understanding and trust compared to Wikipedia.
- Editorial governance, moderation, and policy transparency for Grokipedia are not examined. Document governance structures, enforcement mechanisms, and their relationship to sourcing and neutrality.
Practical Applications
Immediate Applications
Below are actionable use cases that can be deployed now, grounded in the paper’s released datasets, methods, and findings.
- Citation-quality auditing for platforms
- Sector: software, media integrity, trust & safety
- Application: Use the paper’s Perennial Sources mapping and Lin et al. reliability scores to build automated checks that flag “generally unreliable,” “blacklisted,” and very low-scored domains in AI-written articles.
- Tool/Product: “Citation Quality Monitor” that surfaces risk scores per article and per domain; batch reports for site-wide audits; alerts for controversial-topic pages.
- Dependencies/Assumptions: Ongoing access to domain rating lists; acceptance of Wikipedia community norms and Lin et al. scores as proxies; up-to-date scraping or API access.
- Fact-checking triage based on structural drift
- Sector: journalism, fact-checking, civil society
- Application: Exploit the demonstrated pattern that article similarity is highest in introductions and drops linearly with position to prioritize verification of later sections where divergence is likelier.
- Tool/Product: “Section Triage Assistant” that ranks claims by chunk position and similarity deltas against a canonical source set.
- Dependencies/Assumptions: Reliable chunking and embeddings; access to comparison corpora (e.g., Wikipedia dumps).
- Semantic search and clustering on Grokipedia
- Sector: software (search and IR), research
- Application: Build semantic search, topic clustering, and duplicate detection over the released Grokipedia embeddings for discovery, navigation, and corpus analysis.
- Tool/Product: “Grokipedia Semantic Explorer” with topic filters mirroring WMF’s topic ontology; near-duplicate and verbatim-copy detectors.
- Dependencies/Assumptions: Use of the EmbeddingGemma-based vectors provided; basic infra for vector search.
- Browser extension for readers to flag suspect citations
- Sector: consumer software, education
- Application: Surface per-page badges showing proportions of “generally unreliable,” “blacklisted,” and very low-scored domains; highlight “LLM auto-citogenesis” (citations to Grok/X conversations).
- Tool/Product: “CiteGuard” extension overlay on Grokipedia (and other AI encyclopedias).
- Dependencies/Assumptions: Stable page structure for client-side parsing; public domain lists.
- Enterprise AI documentation QA
- Sector: software/enterprise knowledge management
- Application: Integrate citation checks and similarity monitors into CI pipelines to avoid self-referential citations, low-quality domains, and unattributed copying.
- Tool/Product: “AI Doc QA Gate” with policies for permitted domains; detectors for self-citation (e.g., x.com/i/grok/share) and unattributed CC content.
- Dependencies/Assumptions: Organizational policy adoption; access to internal content provenance signals.
- Reputation and political-risk monitoring
- Sector: public affairs, finance, policy advisory
- Application: Track framing changes and citation quality for elected officials and controversial topics, where the paper shows lower similarity and higher use of unreliable sources.
- Tool/Product: “Framing Delta Dashboard” comparing Grokipedia vs. Wikipedia across parties/topics; alerts for spikes in low-quality citations.
- Dependencies/Assumptions: Regular updated scrapes; stable title joins; acceptance of similarity metrics as framing proxies.
- Disinformation watchdog dashboards
- Sector: civil society, security
- Application: Monitor extremist and conspiracy sites (e.g., Stormfront, InfoWars, Natural News) that appear in Grokipedia but not in Wikipedia; track frequency and page types.
- Tool/Product: “Extremist Citation Tracker” with longitudinal counts and topic breakdowns; case file exports for investigations.
- Dependencies/Assumptions: Domain blocklists; sustained scraping; care to avoid amplification harms.
- IP/licensing compliance checks
- Sector: legal/IP, platform ops
- Application: Use cosine similarity and CC-license markers to detect verbatim or near-verbatim copies without attribution, enabling license compliance enforcement.
- Tool/Product: “CC Compliance Auditor” with similarity thresholds tuned per topic; reporting on pages missing attribution.
- Dependencies/Assumptions: Clear license text detection; legal review of similarity thresholds and evidence standards.
- Education modules on source evaluation and NPOV
- Sector: education
- Application: Classroom exercises comparing Grokipedia vs. Wikipedia entries on controversial topics; teach neutrality, sourcing norms, and how “UGC vs. academic vs. news” sourcing shifts affect reliability.
- Tool/Product: Ready-to-use lesson plans and datasets; interactive examples using released corpora.
- Dependencies/Assumptions: Educator access to datasets; school policy alignment.
- Policy risk briefs for regulators
- Sector: policy/governance, platform oversight
- Application: Summarize platform-level metrics (share of blacklisted/unreliable citations; prevalence in controversial topics) for risk assessments of AI encyclopedias.
- Tool/Product: “AI Knowledge Base Risk Report” with sectoral breakdowns (e.g., health, politics).
- Dependencies/Assumptions: Agreement on metrics; careful communication to avoid politicization of source lists.
- Content strategy and SEO insights
- Sector: marketing, content ops
- Application: Use the pageview overlap finding (Grokipedia launched with ~69% of Wikipedia traffic pages) to prioritize high-demand topics and geographic focus.
- Tool/Product: “Demand Map” based on WMF geo-pageviews; topic selection guidance.
- Dependencies/Assumptions: Continued availability of WMF pageview data; correct title mappings.
- Academic use of released datasets
- Sector: academia (NLP, IR, media studies)
- Application: Immediate use of the HuggingFace dump and embeddings to study framing, bias, citation quality, and corpus similarity at scale; build benchmarks.
- Tool/Product: “Framing & Sourcing Benchmark Suite” seeded by this corpus and code.
- Dependencies/Assumptions: Dataset persistence; compute resources; proper ethical review.
Long-Term Applications
The following applications require further research, scaling, standardization, or development before broad deployment.
- Automated verifiability scoring of claims
- Sector: AI/fact-checking, journalism
- Application: Develop systems that rate claim verifiability against cited sources, beyond domain-level heuristics, as flagged in the paper’s future work.
- Tool/Product: “Claim Verifier” with retrieval-grade evidence matching and veracity scoring.
- Dependencies/Assumptions: Advances in claim-evidence alignment; gold-standard datasets; human-in-the-loop workflows.
- Framing-shift detection beyond similarity
- Sector: AI safety, media analysis
- Application: Build models that detect subtle linguistic framing changes (lexical choice, voice shifts, implication), not captured by cosine similarity.
- Tool/Product: “Framing Auditor” with bias-sensitive NLP features and topic-aware baselines.
- Dependencies/Assumptions: Annotated corpora; robust, domain-generalizable metrics; careful validation to avoid false positives.
- Dynamic, comprehensive source reliability graph
- Sector: research, platform integrity
- Application: Expand beyond limited lists to a web-scale, continuously updated reliability graph incorporating expert ratings, provenance, and topic sensitivity.
- Tool/Product: “Web Reliability Atlas” powering moderation, ranking, and citation scoring.
- Dependencies/Assumptions: Data partnerships; governance for updates; transparency standards.
- Content provenance tracking and attribution enforcement
- Sector: AI trust, IP compliance
- Application: Watermarking and lineage tracking to detect when AI encyclopedias synthesize or copy from CC sources without attribution; enforce license terms.
- Tool/Product: “Attribution Ledger” combining cryptographic watermarks and similarity signals.
- Dependencies/Assumptions: Industry adoption of provenance signals; legal frameworks and cross-platform cooperation.
- Standards and certification for AI encyclopedias
- Sector: policy/regulation, industry consortia
- Application: Create neutrality and citation-quality standards; certify platforms that meet minimum thresholds for reliable sourcing and non-self-referential citations.
- Tool/Product: “AI Knowledge Integrity Standard” and certification program.
- Dependencies/Assumptions: Multi-stakeholder governance; agreement on metrics; compliance auditing mechanisms.
- Training data curation pipelines that penalize low-quality citations
- Sector: AI/ML engineering
- Application: Use citation-quality signals to filter or reweight training data (and fine-tuning corpora), improving model outputs on knowledge tasks.
- Tool/Product: “Citation-Aware Data Curator” integrated into model training workflows.
- Dependencies/Assumptions: Scalable labeling; measurable downstream gains; avoidance of over-filtering niche but valid sources.
- Mitigation of “LLM auto-citogenesis” across platforms
- Sector: AI safety, platform governance
- Application: Establish platform-wide protocols to detect and prevent models from citing their own or sibling model outputs as authoritative evidence.
- Tool/Product: “Self-Citation Firewall” with cross-domain provenance checks.
- Dependencies/Assumptions: Shared provenance schemas; cooperative enforcement by major platforms.
- Search ranking based on citation-quality signals
- Sector: search/IR
- Application: Incorporate reliability and self-citation penalties into ranking, demoting pages that lean on blacklisted or very low-scored domains.
- Tool/Product: “Citation-Aware Ranker” with explainable score components.
- Dependencies/Assumptions: High-coverage reliability labels; guardrails against bias; transparency to site owners.
- Community moderation tooling for AI-generated knowledge bases
- Sector: platform moderation
- Application: Adapt Wikipedia policies (NPOV, “No Original Research,” anti-puffery) into moderation UIs and workflows for AI encyclopedias, informed by the paper’s topic-specific findings.
- Tool/Product: “NPOV Moderator Console” with policy-aligned prompts and review queues.
- Dependencies/Assumptions: Platform willingness; community-building; policy translation to AI contexts.
- Geo-aware bias and coverage analytics
- Sector: media analysis, policy
- Application: Combine geo-pageviews with topic and citation-quality to study regional exposure to low-quality sourcing and ideological framing.
- Tool/Product: “GeoBias Analyzer” for public-interest reporting and interventions.
- Dependencies/Assumptions: Continued access to geo-aggregated pageviews; privacy-preserving methods.
- Public service for cross-corpus comparisons
- Sector: research infrastructure, transparency
- Application: Productize the paper’s pipeline as an open service that compares any AI encyclopedia to reference corpora (Wikipedia, authoritative databases) for similarity and source quality.
- Tool/Product: “Knowledge Base Comparator” with APIs, dashboards, and reproducible reports.
- Dependencies/Assumptions: Sustainable hosting; legal review for fair use; community governance of reference lists.
- Sector-specific risk monitors (health, energy, finance)
- Sector: healthcare, energy, finance
- Application: Track unreliable sourcing and framing in domain-critical topics (e.g., vaccines, grid reliability, banking crises) to inform communications and counter-misinformation.
- Tool/Product: “Domain Integrity Monitor” with sector taxonomies and escalation playbooks.
- Dependencies/Assumptions: Domain ontologies; expert curation; coordination with regulators and professional bodies.
Glossary
- Bimodal distribution: A probability distribution with two distinct peaks, indicating two prevalent values or clusters in the data. "follow a bimodal distribution"
- Blacklisted: A category in Wikipedia’s sourcing guidelines indicating domains that are broadly prohibited from citation due to severe reliability issues. "grouped as “generally reliable,” “generally unreliable,” “blacklisted,” “no consensus,” and “deprecated.”"
- C-class: A mid-level Wikipedia article quality rating indicating a substantial article that still requires significant work. "Start, Stub, and C-class articles"
- CC-licensed: Content released under a Creative Commons license allowing reuse with attribution and other terms. "CC-licensed articles on Grokipedia"
- Chunk: A contiguous segment of text used for processing or analysis, often defined by token counts. "we extracted the plaintext content of each article in 250-token chunks"
- Cosine similarity: A measure of similarity between two vectors that calculates the cosine of the angle between them, often used for comparing embeddings. "we utilized embedding cosine similarity"
- Creative Commons Attribution-ShareAlike 4.0 License: A CC license allowing reuse and modification with attribution and share-alike requirements. "The content is adapted from Wikipedia, licensed under Creative Commons Attribution-ShareAlike 4.0 License."
- Deprecated: A Wikipedia sourcing status indicating sources strongly discouraged due to reliability concerns. "grouped as “generally reliable,” “generally unreliable,” “blacklisted,” “no consensus,” and “deprecated.”"
- Domain reliability scores: Quantitative ratings for source domains indicating credibility based on expert aggregations. "we use Lin et al.'s domain reliability scores"
- Edit wars: Repeated back-and-forth revisions on a page by opposing editors, often requiring protections or strict guidelines. "more vulnerable to “edit wars,”"
- EmbeddingGemma: A specific embedding model from Google designed for creating vector representations of text. "using Google's EmbeddingGemma"
- Embeddings: Vector representations of text capturing semantic meaning for comparison or retrieval. "as well as embeddings of the entire Grokipedia corpus."
- Generally reliable: A Wikipedia Perennial Sources category for sources broadly accepted as trustworthy. "grouped as “generally reliable,” “generally unreliable,” “blacklisted,” “no consensus,” and “deprecated.”"
- Generally unreliable: A Wikipedia Perennial Sources category for sources broadly considered untrustworthy. "grouped as “generally reliable,” “generally unreliable,” “blacklisted,” “no consensus,” and “deprecated.”"
- Geo-pageview dataset: A Wikimedia dataset reporting pageviews by country in a privacy-preserving manner. "we utilize a month of WMF's geo-pageview dataset"
- Geolocated pageview data: Pageview counts associated with user locations, aggregated to protect privacy. "The geolocated pageview data from the month prior to Grokipedia's release"
- Good Articles: A Wikipedia quality class for well-written, factually accurate, and broad coverage articles that meet specific criteria. "Other quality classes include: “Good Articles” (GA)"
- Histogram: A graphical representation showing the distribution of numeric data by binning values. "Figure~\ref{fig:sim-by-quality} depicts a histogram of chunk similarity"
- LLM auto-citogenesis: The process where LLMs generate content that is then cited by related systems, creating feedback loops. "may be engaging in a new kind of “LLM auto-citogenesis”"
- Log-scaled: A transformation where values are scaled logarithmically to better visualize wide-ranging data. "log-scaled geographic distribution of pageview traffic"
- Markdown rendering: Converting Markdown-formatted text into structured HTML or similar output. "seems to be derived from Markdown rendering."
- MediaWiki: The software platform that powers Wikipedia and other Wikimedia projects. "Grokipedia does not use MediaWiki software to run their service."
- Neutral Point of View: A core Wikipedia policy requiring content to be written without bias. "English Wikipedia has a “Neutral Point of View” policy"
- No consensus: A Wikipedia sourcing category indicating the community has not reached agreement on a source’s reliability. "grouped as “generally reliable,” “generally unreliable,” “blacklisted,” “no consensus,” and “deprecated.”"
- No Original Research: A Wikipedia policy requiring all content to be supported by published sources rather than original analysis. "via the “No Original Research” policy"
- Non-CC-licensed: Content not released under Creative Commons, governed by other terms, often with different reuse constraints. "non-CC-licensed articles are notably less similar to their corresponding English Wikipedia articles"
- Pairwise cosine similarity: Computing cosine similarity between every pair of vectors in a set or between corresponding elements. "calculated the within-article pairwise cosine similarity for each chunk."
- Perennial Sources list: A community-maintained roster of frequently discussed sources with documented reliability assessments. "The English Wikipedia community maintains the “Perennial Sources” list"
- Proxy: An intermediary server used to route requests, often for load management or access control. "routing requests through a proxy."
- Semantic similarity: The degree to which texts share meaning, often measured via embeddings. "The other primary measure we use to compare the two corpora is semantic similarity between article chunks."
- Start: A Wikipedia article quality class indicating an article that covers the topic inadequately and needs significant work. "“Starts,”"
- Stub: A minimal Wikipedia article providing only basic information, needing expansion. "“Stubs,”"
- Token overlap: The number of token units duplicated between consecutive chunks to preserve context continuity. "with a 100-token overlap between chunks."
- Topic ontology: A structured hierarchy of topics used for classification and analysis. "This topic ontology is multi-level"
- User-generated content (UGC): Content created by users on platforms like social media, often less vetted than editorial sources. "social networks and other UGC platforms."
- Wikidata: A collaboratively edited knowledge base providing structured data used across Wikimedia projects. "Specifically, we query Wikidata"
- Wikipedia dump: A comprehensive export of Wikipedia content for a specific date, used for offline analysis. "the daily Wikimedia Enterprise English Wikipedia dump"
- Wikimedia Foundation (WMF): The nonprofit organization that hosts and supports Wikipedia and related projects. "The Wikimedia Foundation (WMF) publishes statistics"
- Featured Article: Wikipedia’s highest quality designation indicating exemplary writing, sourcing, and coverage. "an article with a “Featured Article” (FA) designation could be featured on the front page of Wikipedia."
Collections
Sign up for free to add this paper to one or more collections.